
答应大家的AI歌手教程来了,手把手教你训练你自己的AI歌手,主要分为使用模型和训练模型两部分,这里是第一部分如何使用模型生成音乐的部分,主要介绍了音源的处理,模型的使用和后期音轨的合成。
看在藏师傅生病肝教程的份上希望各位多多支持,下面是具体步骤🧶
看在藏师傅生病肝教程的份上希望各位多多支持,下面是具体步骤🧶
详细教程和文件下载可以看这里:mp.weixin.qq.com/s/bXD1u6ysYkTE… 

要使用模型进行推理的话你首先需要一段已经演唱好的声音垫进去,所以我们需要先对你垫进去的声音进行处理。
首先要安装UVR_v5.5.0,完成后我们需要给UVR增加一个模型解压UVR5模型文件将里面的两个文件夹粘贴到安装目录下的Ultimate Vocal Removermodels就行。
首先要安装UVR_v5.5.0,完成后我们需要给UVR增加一个模型解压UVR5模型文件将里面的两个文件夹粘贴到安装目录下的Ultimate Vocal Removermodels就行。

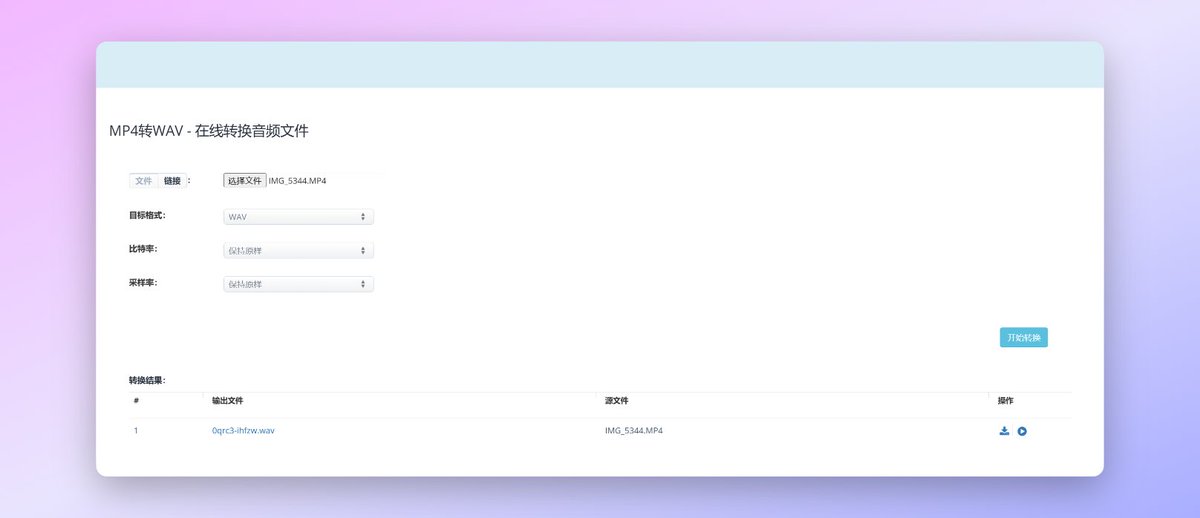
在处理之前你需要把你声音的格式转换成WAV格式,因为So-VITS-SVC 4.0只认WAV格式的音频文件,现在处理了后面会省事点。可以用这个工具处理:aconvert.com/cn/audio/mp4-t…
处理完音频文件后我们就要开始利用UVR去掉背景音了,一共需要过两次,每次的设置都是不同的,下面两张图分别是两次的参数。


接下来我们就要运行整合包的Web UI来推理声音了,如果你用的其他人的模型的话你需要先把模型文件放进整合包对应的文件夹下面:
首先是模型文件夹下面后缀为pth和pt的两个文件放到整合包的logs44k文件夹下。
之后是模型文件里那个叫config.json的json文件,放到整合包的configs文件夹下面。
首先是模型文件夹下面后缀为pth和pt的两个文件放到整合包的logs44k文件夹下。
之后是模型文件里那个叫config.json的json文件,放到整合包的configs文件夹下面。

接下来我们就可以运行整合包的Web UI了,打开整合包根目录下的【启动webui.bat】这个文件他会自动运行并打开Web UI的网页,经常玩Stable Diffusion的朋友肯定对这个操作不陌生。
下面就是Web UI的界面我们使用模型的时候主要用的是推理这个功能。
下面就是Web UI的界面我们使用模型的时候主要用的是推理这个功能。

之后就是选择我们的模型,如果你刚才已经把模型放到合适的位置的话你现在应该能在下图的两个位置选择到你的模型和配置文件,如果有报错会在输出信息的位置显示。
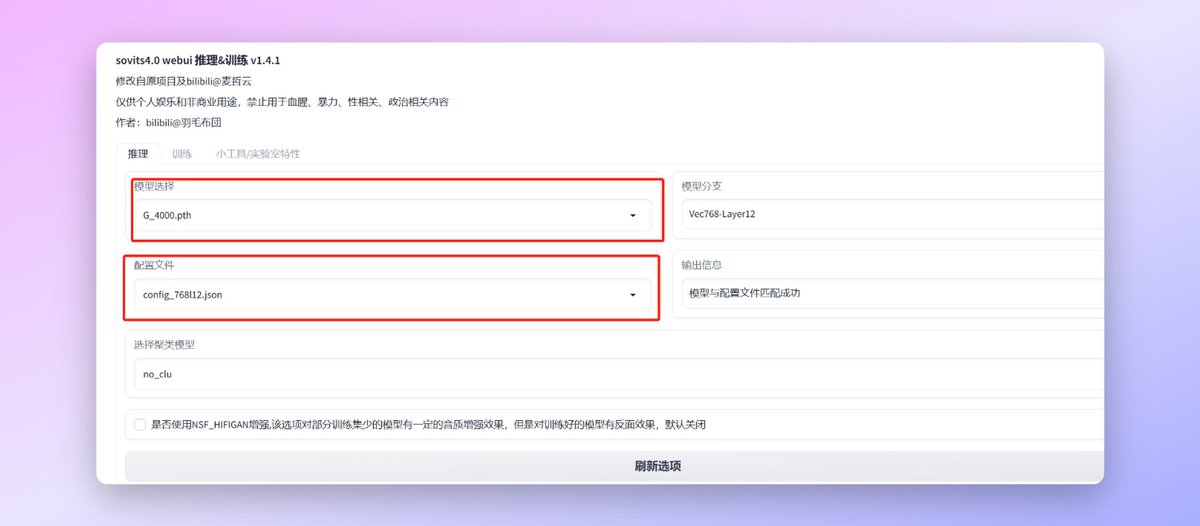
选择完模型之后我们需要点击加载模型,等待一段时间Loading之后模型会加载完成。Output Message这里会输出加载的结果。

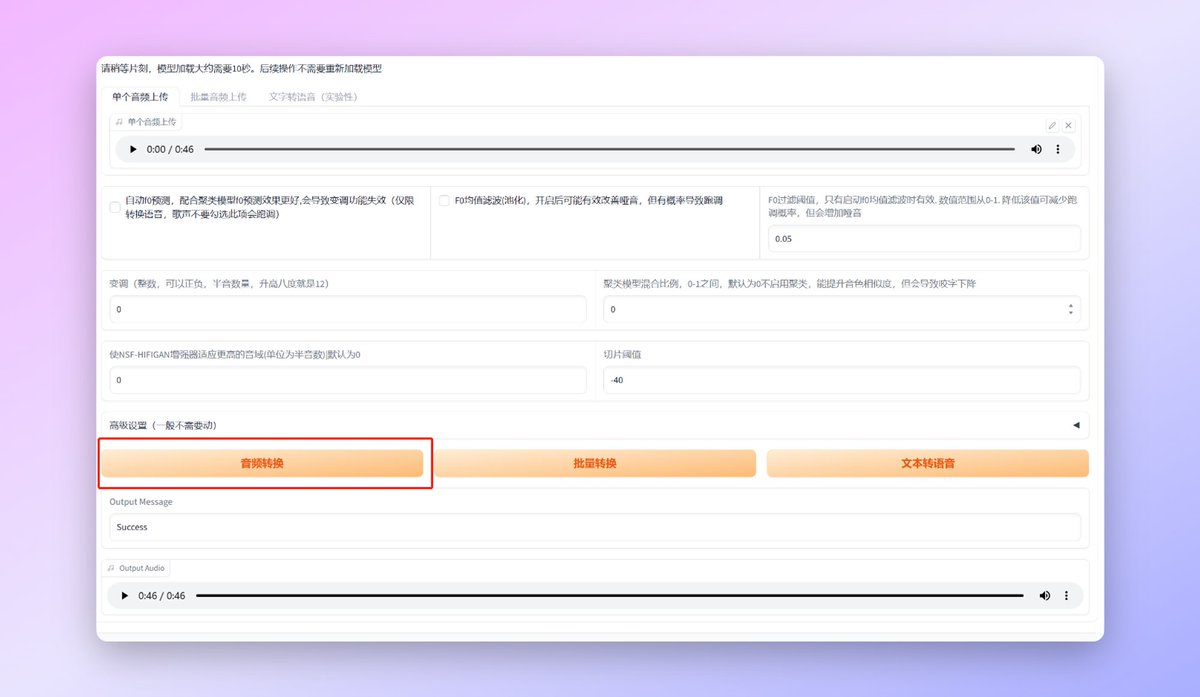
之后就是上传我们处理好的需要垫的音频文件了,把文件拖动到红框位置就行。
接下来是两个比较重要的选项怕【聚类f0】会让输出效果更好,但是如果你的文件是歌声的话不要勾选这个选项,不然会疯狂跑调。【F0均值滤波】主要解决哑音问题,如果你输出的内容有比较明显的哑音的话可以勾选尝试一下。
接下来是两个比较重要的选项怕【聚类f0】会让输出效果更好,但是如果你的文件是歌声的话不要勾选这个选项,不然会疯狂跑调。【F0均值滤波】主要解决哑音问题,如果你输出的内容有比较明显的哑音的话可以勾选尝试一下。


设置好之后我们点击【音频转换】按钮之后经过一段时间的运算,就可以生成对应的音乐了。
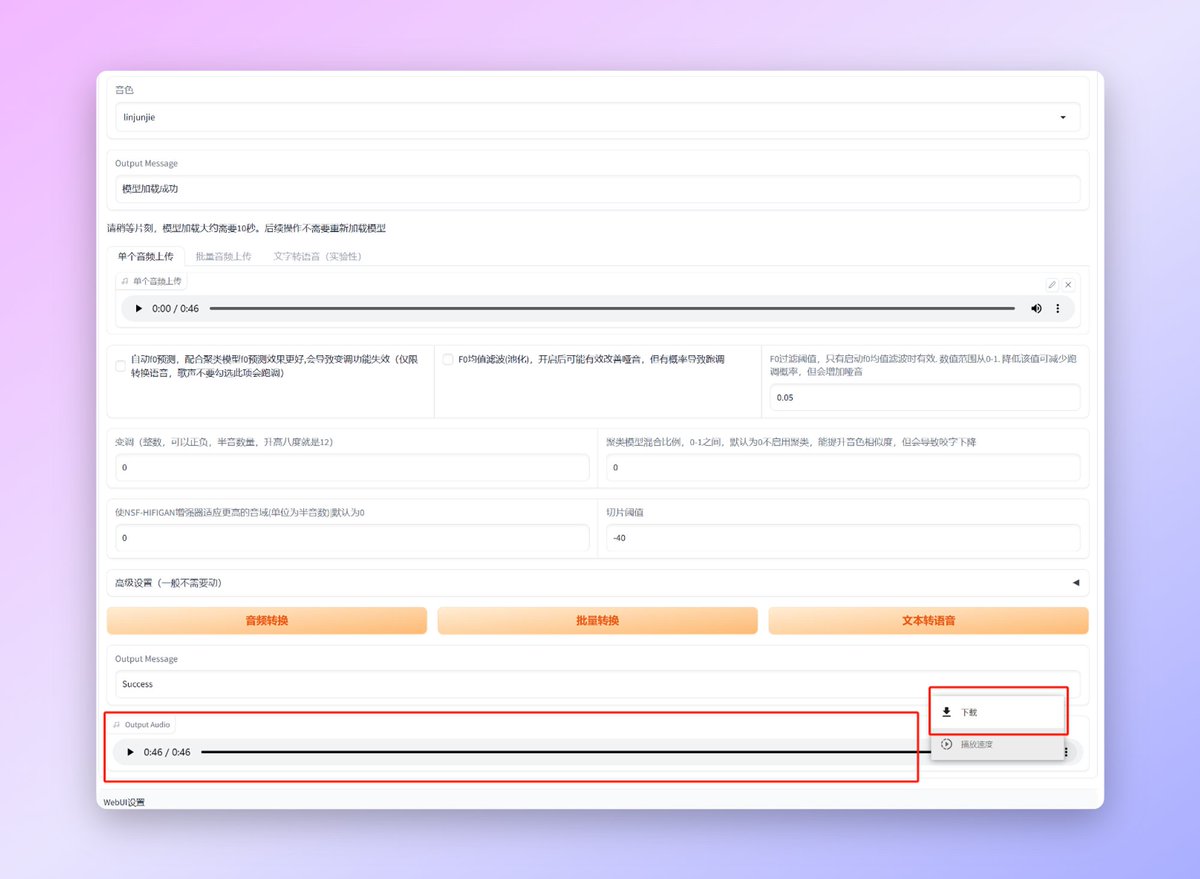
【output audio】的位置就是生成的音频了可以试听,如果觉得OK的话可以,点击右边三个点弹出的下载按钮下载。
【output audio】的位置就是生成的音频了可以试听,如果觉得OK的话可以,点击右边三个点弹出的下载按钮下载。
我们现在生成的是一段只有人声的干声,这时候我们刚才剥离出来的伴奏就有用了,把两段音频合成就行,我用的剪映,直接把两段音轨拖进去导出就行,也可以加张图片变成视频。

好了模型的使用部分到这里就结束了,理论上你现在如果有孙燕姿的模型的话已经可以生产AI音乐了。垫的音频文件也有一些要求,首先肯定是人声要清晰,伴奏最好少点去的也干净同时效果也会更好。感谢支持。
详细教程和文件可以在这里查看:mp.weixin.qq.com/s/bXD1u6ysYkTE…
详细教程和文件可以在这里查看:mp.weixin.qq.com/s/bXD1u6ysYkTE…

对了上面林俊杰的模型是我自己炼的,步数比较少,效果没有孙燕姿这个好,轻拍
• • •
Missing some Tweet in this thread? You can try to
force a refresh















