
关注人工智能、LLM 、 AI 图像视频和设计(Interested in AI, LLM, Stable Diffusion, and design)
歸藏的 AIGC 周刊|公众号:歸藏的AI工具箱
 如果你懒得等施工🚧可以在这里看长文:
如果你懒得等施工🚧可以在这里看长文: 提示词:参考图一的风格和样式为图2的角色生成一个图标,图标下方的文字应该为“guizang”
提示词:参考图一的风格和样式为图2的角色生成一个图标,图标下方的文字应该为“guizang” 用 Nano Banana 多的朋友可能发现了,就是 Nano Banana 在有多张图片输入的时候,输出图的比例会跟其中一张相同,只不过这个过程很不可控。
用 Nano Banana 多的朋友可能发现了,就是 Nano Banana 在有多张图片输入的时候,输出图的比例会跟其中一张相同,只不过这个过程很不可控。


 提示词:
提示词: ID 保持真的很牛批,比如让藏师傅变瘦
ID 保持真的很牛批,比如让藏师傅变瘦 


 等不及施工的可以先收藏
等不及施工的可以先收藏

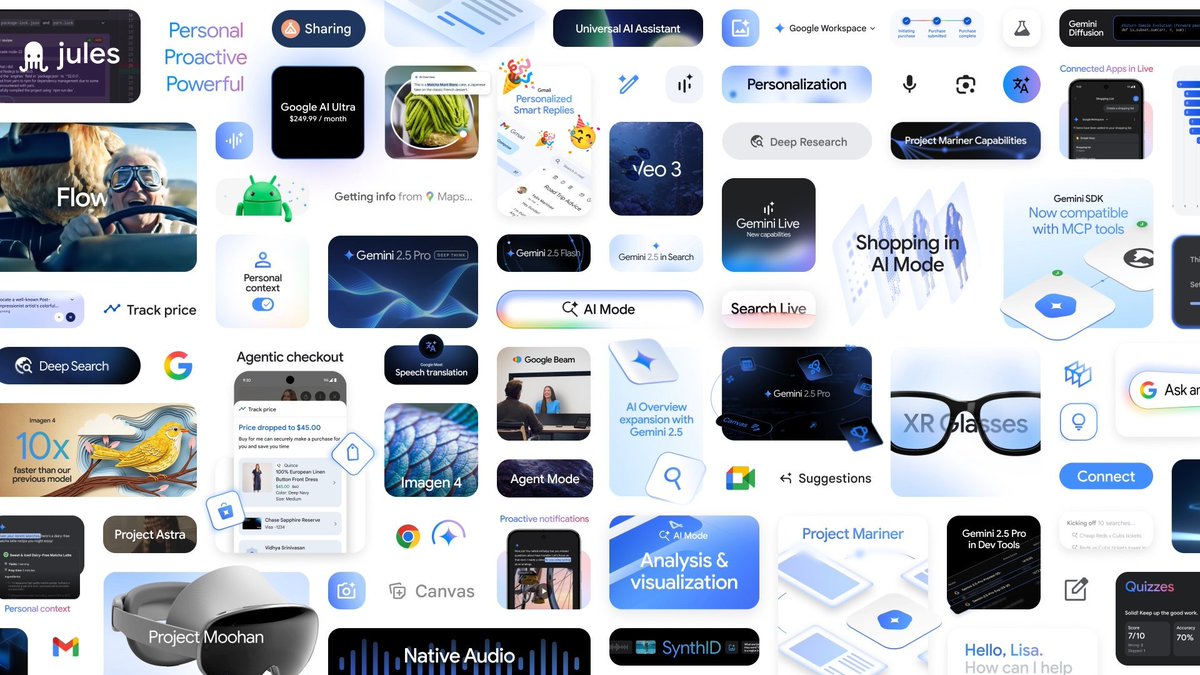 AI 模式即将面向美国所有用户推出。
AI 模式即将面向美国所有用户推出。 如果等不及施工可以看这里:mp.weixin.qq.com/s/uQQ7R8rBUXZ6…
如果等不及施工可以看这里:mp.weixin.qq.com/s/uQQ7R8rBUXZ6…
 先看一下Trae 发布了四大重磅功能
先看一下Trae 发布了四大重磅功能



 阿里百炼具体特点有:
阿里百炼具体特点有: 快速导入
快速导入
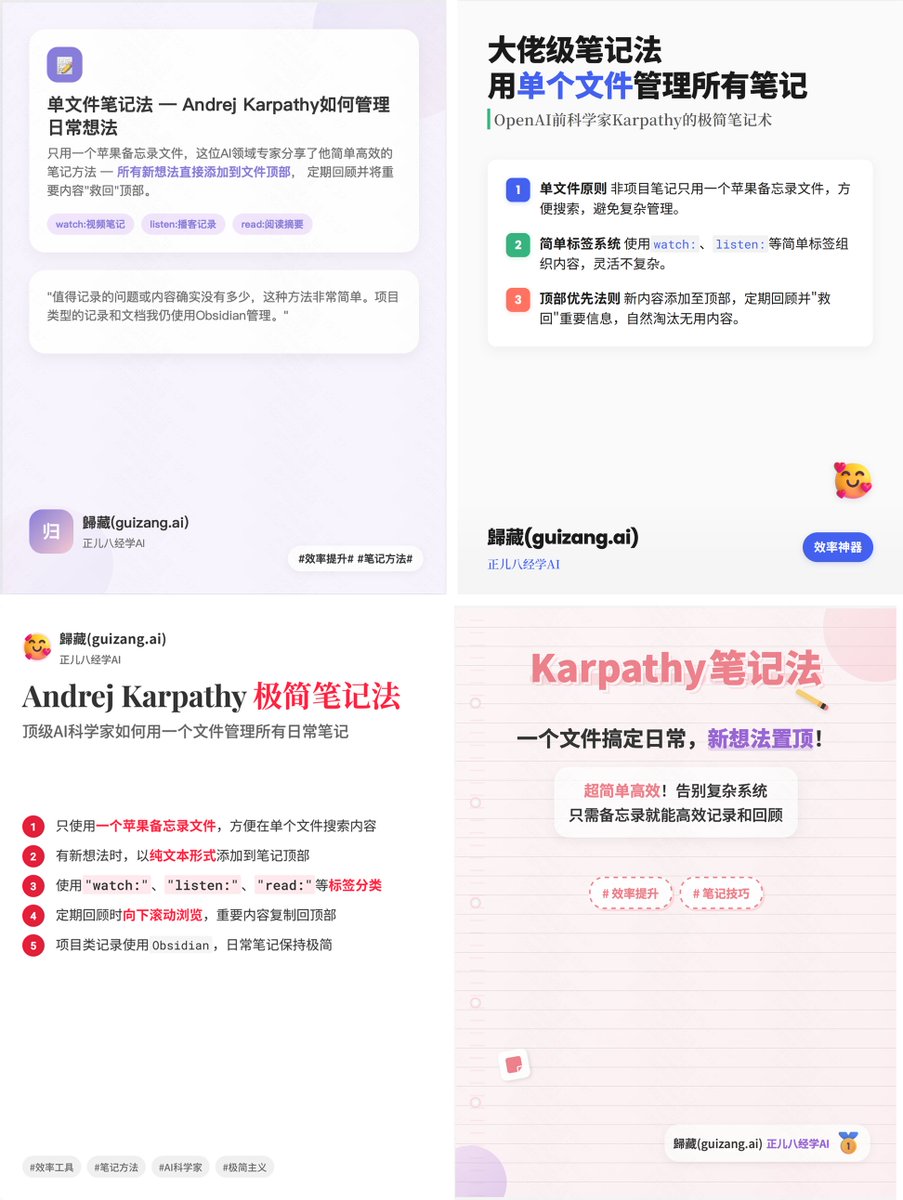 不想等施工🚧的可以看这里:mp.weixin.qq.com/s/OFCgFrXNQgIT…
不想等施工🚧的可以看这里:mp.weixin.qq.com/s/OFCgFrXNQgIT…
 比如我最近一直在看 MCP 相关的内容,秘塔搭载了 Deepseek R1 的研究模式非常强大,搜索的结果非常全面。
比如我最近一直在看 MCP 相关的内容,秘塔搭载了 Deepseek R1 的研究模式非常强大,搜索的结果非常全面。

 解决这个事情其实挺难的,因为需要模型去调用各种 Agents 工具完成任务。需要几个条件:
解决这个事情其实挺难的,因为需要模型去调用各种 Agents 工具完成任务。需要几个条件: