手把手教你训练你自己的AI歌手,最重要的一步来了。如何训练歌手的模型。这一步主要由两部分组成数据处理和模型训练。
这个林俊杰是我自己训练的4800步的模型,对比一下上一篇教程里的孙燕姿模型有两万多步,数据的质量也很重要。
感谢各位的支持,下面是具体步骤🧶
这个林俊杰是我自己训练的4800步的模型,对比一下上一篇教程里的孙燕姿模型有两万多步,数据的质量也很重要。
感谢各位的支持,下面是具体步骤🧶
详细教程和文件下载可以看这里:mp.weixin.qq.com/s/IeeW1PbMUbxM… 
首先我们需要准备你训练的人的声音素材,尽量找质量比较高人声比较清晰的音频。
歌手的声音素材是比较好找的,因为他们的歌就是天然的素材,我们在训练的时候最少要准备30分钟以上的人声素材,一般一个小时到两个小时最好。但是声音的质量大于时间长度,不要为了凑数搞一些质量不那么好的素材。
歌手的声音素材是比较好找的,因为他们的歌就是天然的素材,我们在训练的时候最少要准备30分钟以上的人声素材,一般一个小时到两个小时最好。但是声音的质量大于时间长度,不要为了凑数搞一些质量不那么好的素材。
在准备好足够的声音素材之后我们开始对素材进行处理,跟第一期一样,先把我们的素材转换为WAV格式,批量转换的话还是用格式工厂之类的本地软件比较快。
获取到我们个WAV格式素材之后,继续进行跟上个教程一样的步骤利用UVR去掉我们素材的伴奏以及混响之类的声音,只留下单纯的人声。
获取到我们个WAV格式素材之后,继续进行跟上个教程一样的步骤利用UVR去掉我们素材的伴奏以及混响之类的声音,只留下单纯的人声。

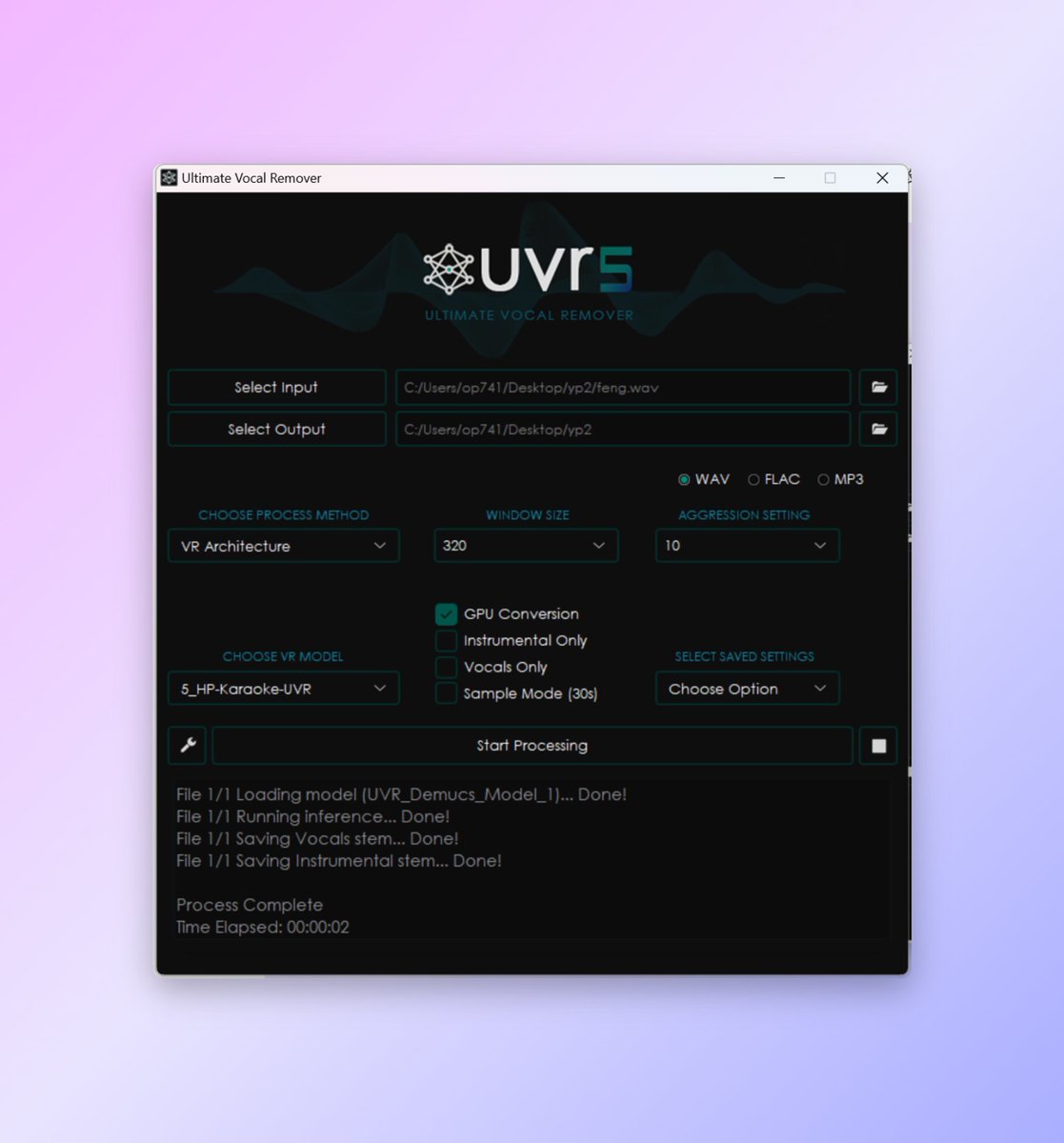
处理完成后扔掉分离出来的伴奏,只留下人声素材,整理好备用。类似我下图这样扔到一个文件夹里。
接下来我们要对处理好的人声文件进行分割,因为如果训练的时候每段文件过长的话容易爆显存。
接下来我们要对处理好的人声文件进行分割,因为如果训练的时候每段文件过长的话容易爆显存。

这个时候就要用到下载文件里的【slicer-gui】这个软件了,它可以自动把声音素材分割成合适的大小。我们先打开slicer-gui,刚开始的参数按我的来就行。
把你你准备好的人声素材拖到【Task List】里面,在Output位置设置好输出文件夹的位置,然后点Start就可以开始分割了。
把你你准备好的人声素材拖到【Task List】里面,在Output位置设置好输出文件夹的位置,然后点Start就可以开始分割了。

处理好的文件,基本上就是下面这个文件的样子,处理完成后在输出文件夹把文件从大到小排序,看一下最大的文件时多长的,分割完的素材每一段尽量不要超过15秒。不然有可能会爆显存。
如果你发现有几条素材比较大的话可以拖进slicer-gui里面重新分割一下,参数按我下面图片设置就行。
如果你发现有几条素材比较大的话可以拖进slicer-gui里面重新分割一下,参数按我下面图片设置就行。

所有数据处理好之后,我们准备开始训练了首先需要把准备好的素材移动到so-vits-svcdataset_raw这个文件夹下,注意不要直接把素材放在dataset_raw文件夹里,拿个文件夹装好放进去,所有的目录不要有中文字符。
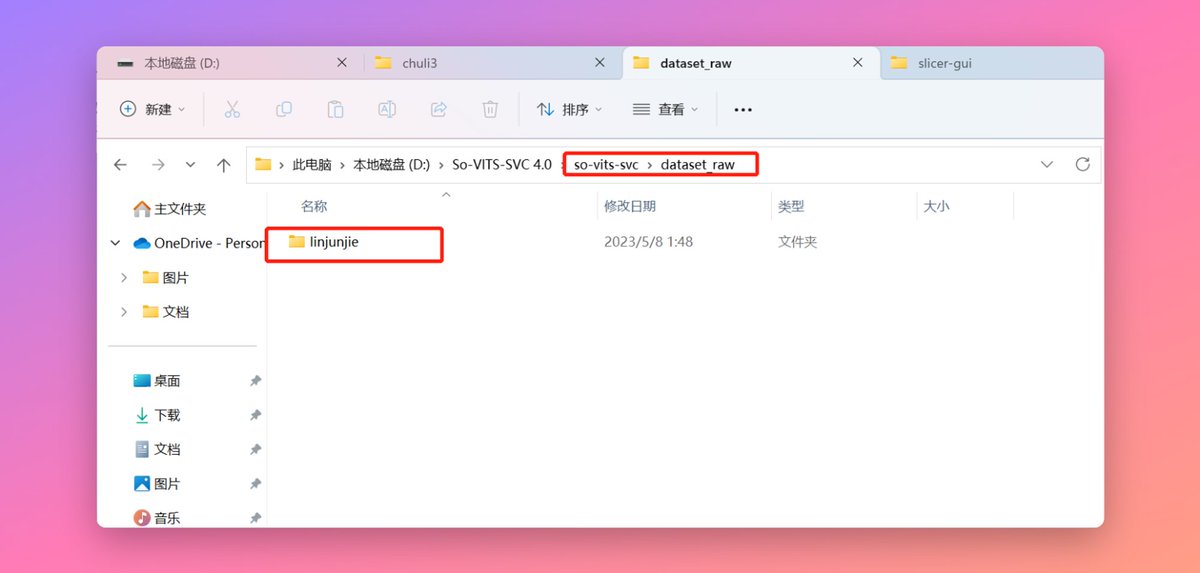
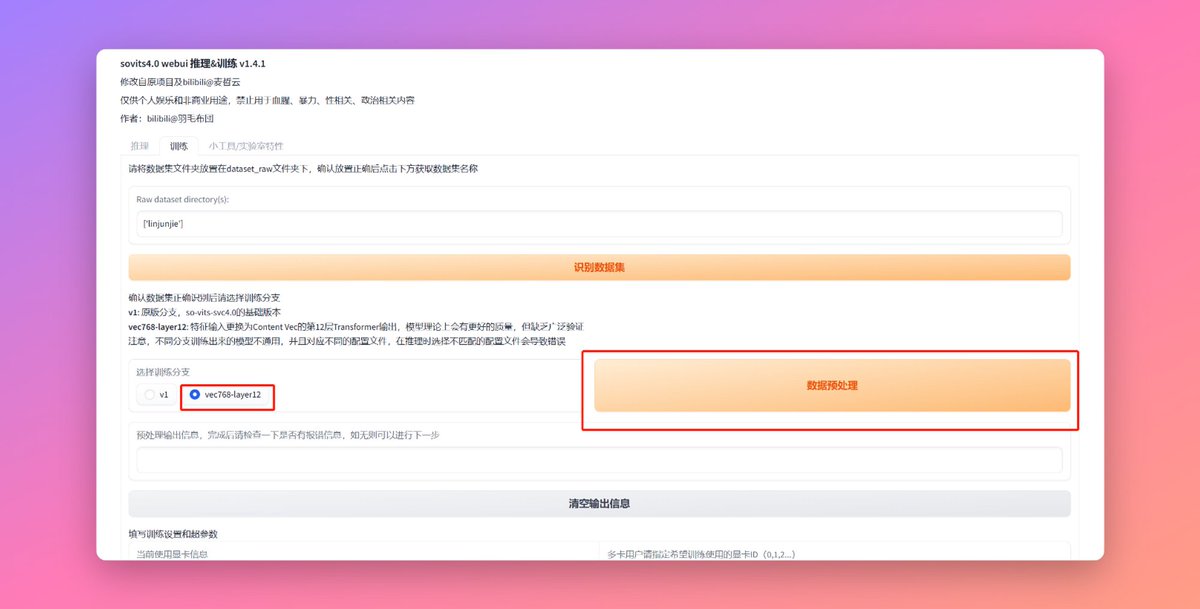
我们开始模型训练,运行so-vits-svc根目录的【启动webui.bat】打开Web UI界面,切换到训练Tab下面。然后点击识别数据集,这时候上面就会展示你数据集文件夹的名字,也会是你模型的名字。

之后就是选择与训练分支了,【vec768-layer12】好像效果会好一些,所以这里我选了这个分支。后就是点击【数据预处理】。
注意这里有个大坑,昨天折腾了我好久,你需要看一下你数据集里面有多少条数据,如果有几百条的的话,你需要把虚拟内存调大点,至于如何调整虚拟内存,这个百度就行,有很多教程。
注意这里有个大坑,昨天折腾了我好久,你需要看一下你数据集里面有多少条数据,如果有几百条的的话,你需要把虚拟内存调大点,至于如何调整虚拟内存,这个百度就行,有很多教程。
开始数据预处理之后这个框会有非常多的信息,基本都是进度到百分之几了,如果预处理出错,在这个框的最后会展示报错信息,如果没错这个回显的基本就到100%就结束了。

如果你数据预处理完了,不想看那一堆信息的话可以点那个【清空输出信息】。
数据处理完之后我们来看一下下面的几个参数,调整一下,准备开始训练。
每多少步生成一次评估日志这里,用默认的200步就行
数据处理完之后我们来看一下下面的几个参数,调整一下,准备开始训练。
每多少步生成一次评估日志这里,用默认的200步就行
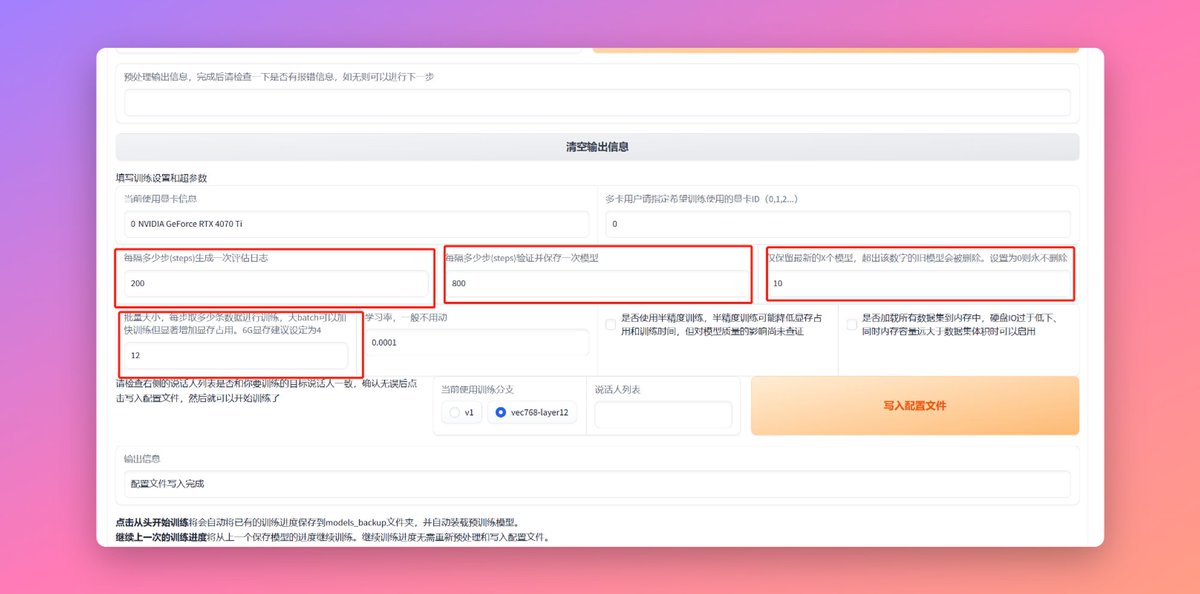
【每隔多少步(steps)验证并保存一次模型】这里默认的800步也就够了,他的意思是每训练800步就会保存一次模型,这个保存的模型你是可以用的
【仅保留最新的X个模型】这个就是字面意思如果每800步保存一次模型的话,你训练到8800的时候第800步的模型就会被自动删除,一个模型大概有1G左右这里看你的硬盘
【仅保留最新的X个模型】这个就是字面意思如果每800步保存一次模型的话,你训练到8800的时候第800步的模型就会被自动删除,一个模型大概有1G左右这里看你的硬盘
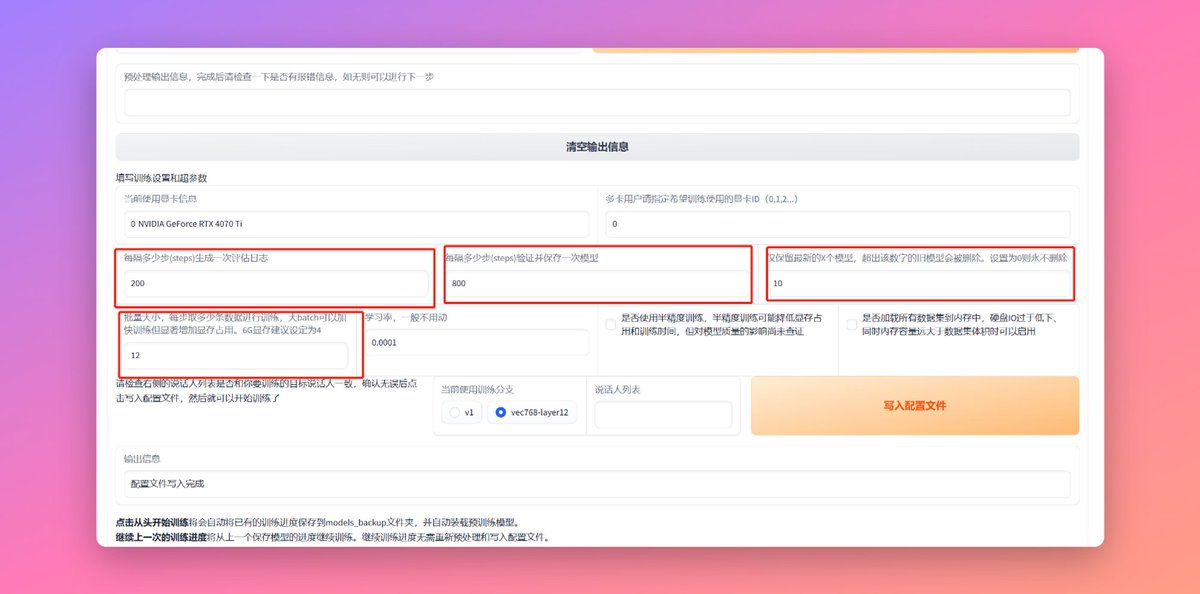
如果设置成0的话就永远不会自动删除。
【批量大小】这个参数跟你的显卡的显存有关,6G建议是4,我的4070Ti是12G我昨天设置的8,我有点怂,其实12也行,我怕爆显存。
【批量大小】这个参数跟你的显卡的显存有关,6G建议是4,我的4070Ti是12G我昨天设置的8,我有点怂,其实12也行,我怕爆显存。
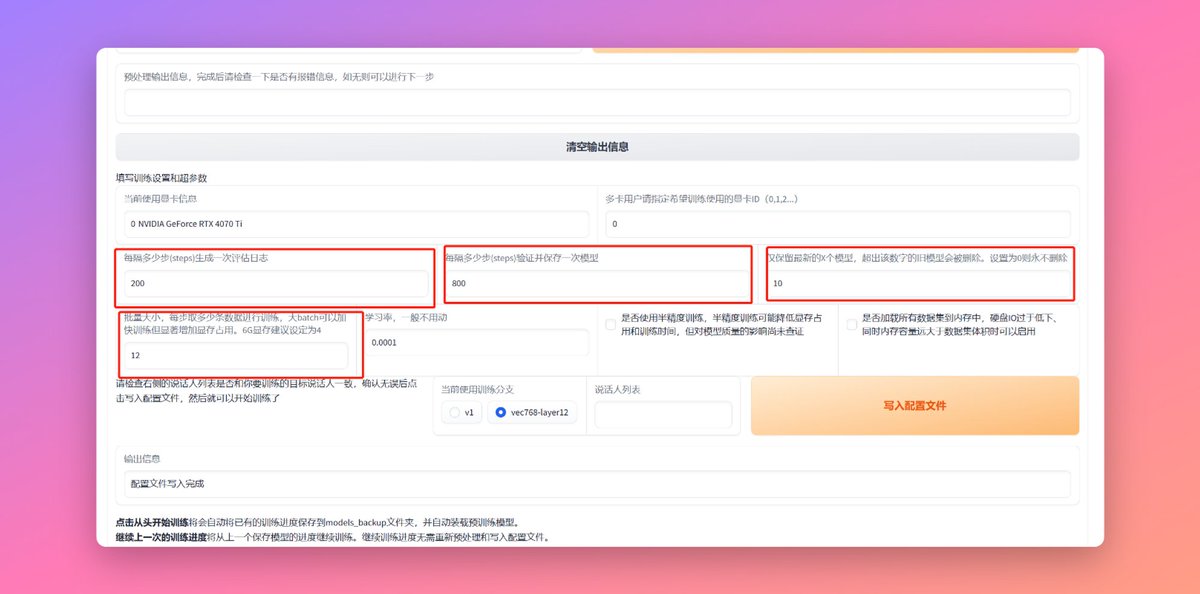
上面几个参数设置完之后,我们选择当前训练分支跟我们数据预处理的时候的一致就行,然后点击写入配置文件,输出信息那里会有写入的结果,如果有报错也会显示在那里。

如果你是第一次训练点击这个【从头开始训练】就行,如果你之前训练过你还想继续训练的话就点这个【继续上一次训练进度】。如果你之前有训练进度,然后你点了【从头开始】的话你的训练进度就会被清空,从新开始从第0步训练。
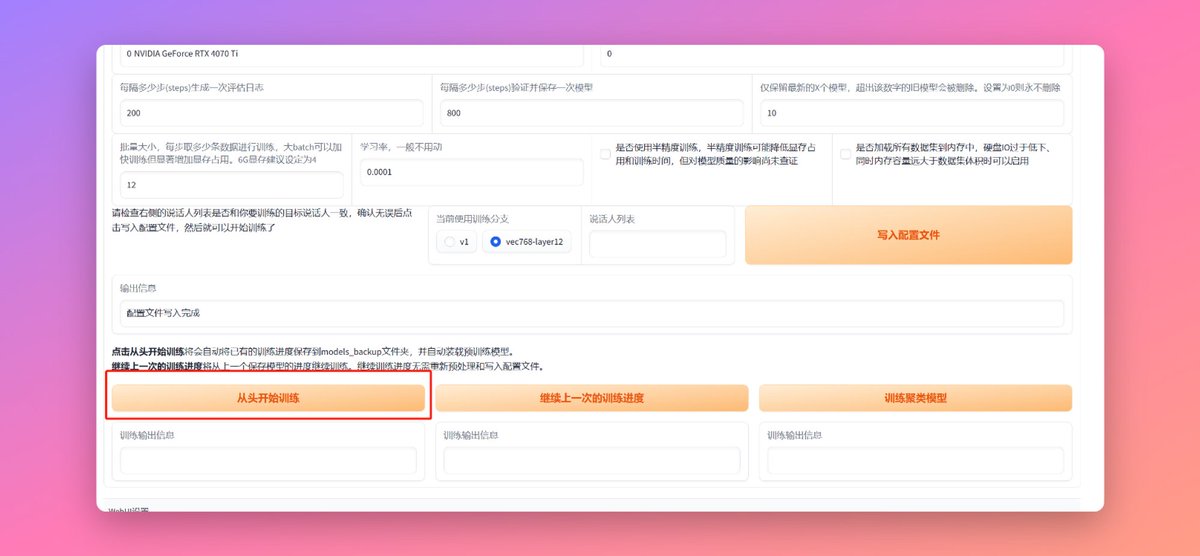
在你点击按钮之后会弹出这样一个弹窗里面就是训练进度,我框起来的地方就是每200步输出的信息,那个loss的值就是判断模型质量好坏的标准,越低越好。
如果你觉得现在的已经可以了的话按CTAL+C键就会停止训练,你可以去推理tab下尝试你的模型,如果不满意还是可以重新回来训练的。
如果你觉得现在的已经可以了的话按CTAL+C键就会停止训练,你可以去推理tab下尝试你的模型,如果不满意还是可以重新回来训练的。

注意你如果设置的每800步保存的话起码要到800才能暂停训练,不然没有保存的模型供你使用。下面这个图就是模型已经保存的提示。

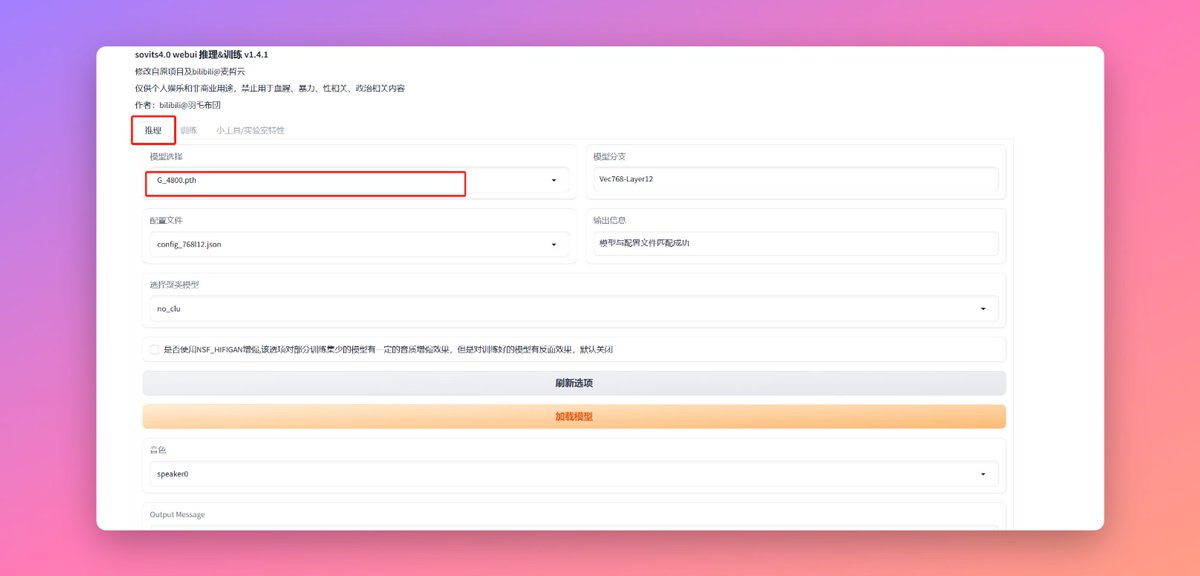
如果你觉得可以了暂停训练之后回到推理 Tab 就能看到你刚才训练的模型了,可能会有好几个因为你选的最多保留十个。按照我们第一期的内容正常使用就可以了。
• • •
Missing some Tweet in this thread? You can try to
force a refresh