这篇文章大致讲清楚了Embedding和如何借助Embedding做PDF问答,原文翻译如下(略有删改):
向量数据库和Embedding是现在 AI 领域的热门话题。
Pinecone 是一家向量数据库公司,估值约为 10 亿美元,刚刚融资 1 亿美元。Shopify、Brex、Hubspot 等公司都在他们的 AI… twitter.com/i/web/status/1…
向量数据库和Embedding是现在 AI 领域的热门话题。
Pinecone 是一家向量数据库公司,估值约为 10 亿美元,刚刚融资 1 亿美元。Shopify、Brex、Hubspot 等公司都在他们的 AI… twitter.com/i/web/status/1…
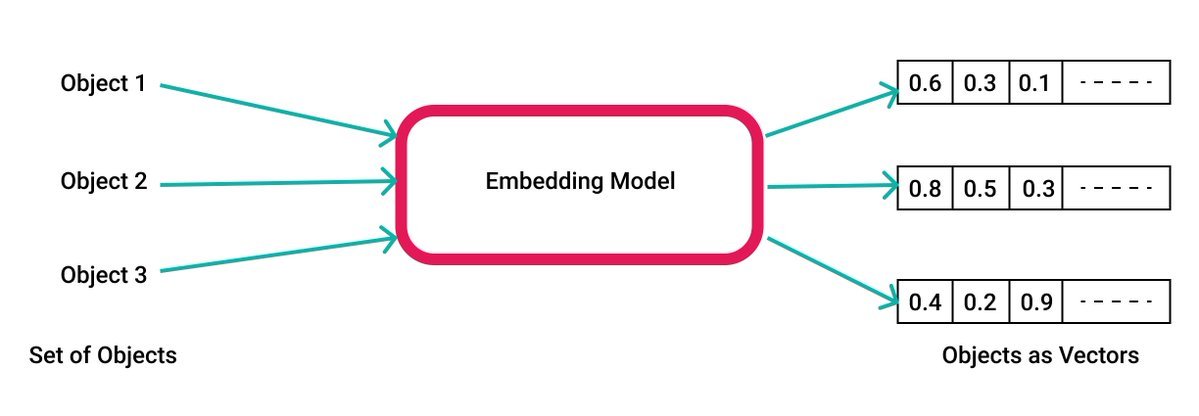
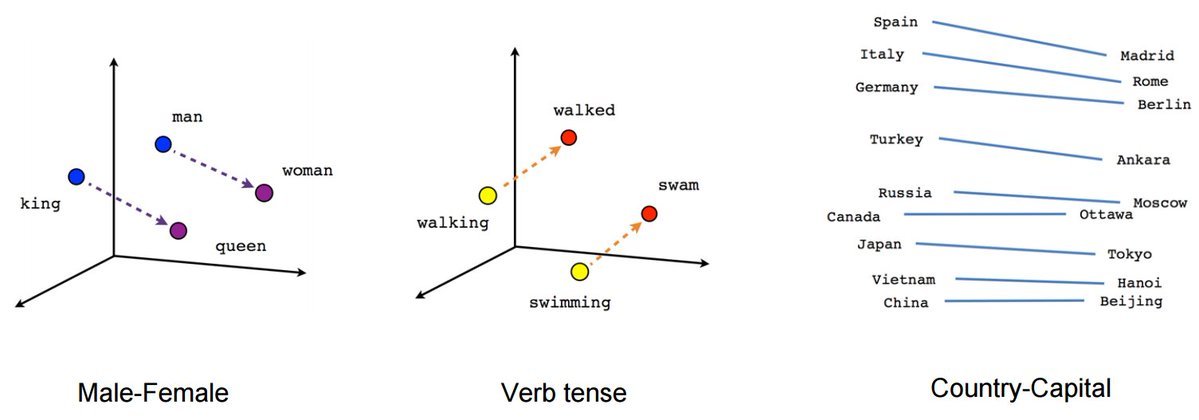
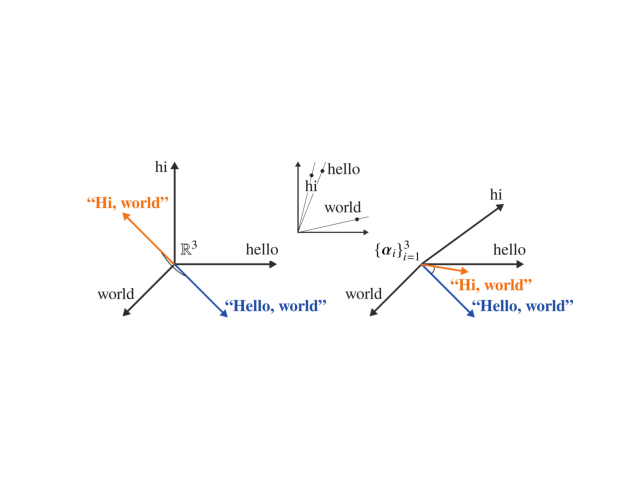
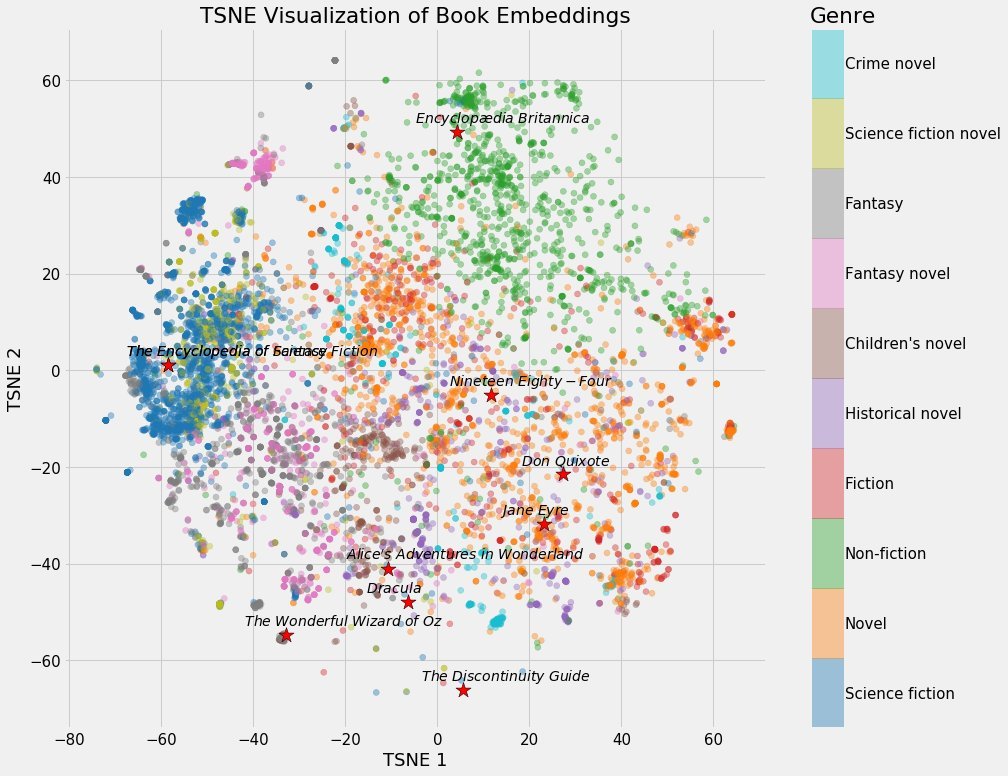
推荐看OpenAI的官方文档《Introducing text and code embeddings》的介绍:
openai.com/blog/introduci…
另外还有OpenAI的系列Embedding相关的Cookbook,例如:
github.com/openai/openai-…
openai.com/blog/introduci…
另外还有OpenAI的系列Embedding相关的Cookbook,例如:
github.com/openai/openai-…
• • •
Missing some Tweet in this thread? You can try to
force a refresh