
16 bit unorm is the best vertex position format. I have shipped many games using it. HypeHype will soon use it too (2.5x mem savings).
Precalc model xyz bounds and round it to next pow2 to ensure that you get zero precision issues with pow2 grid snapping (for kitbashed content).
Precalc model xyz bounds and round it to next pow2 to ensure that you get zero precision issues with pow2 grid snapping (for kitbashed content).
https://twitter.com/ChrisGr93091552/status/1655757946624823296
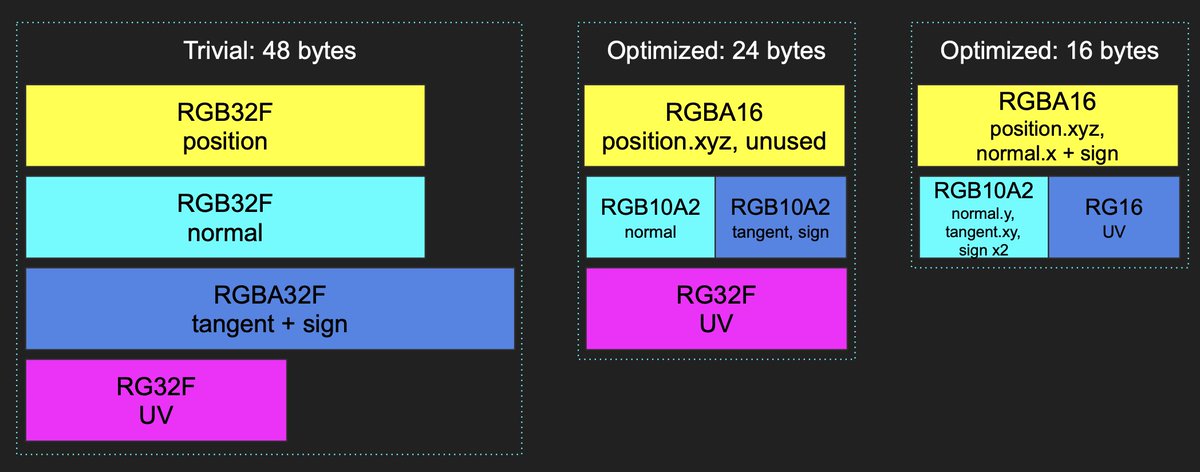
For 2.5x storage savings, I also store the tangent frame in a more dense way. We will use the same 16 bit UV encoding that Horizon Forbidden West uses. 
@Dan87626237 Our solution was to cut the support for bottom 5% hardware. This allowed us to support more modern feature set (such as this texture format). Improves the performance and visuals for the remaining 95%. Makes our new min spec devices actually playable.
@guycalledfrank Of course you use 32 bit floating point for interpolating UVs between VS->PS. 16 bit float interpolants are not enough.
@guycalledfrank fp16 gives you only 10+1+1 = 12 bits equal precision outside the 1/2^3 area in the center, which is where most of the object vertices tend to be. 16 bits is 16x more precision than 12 bits. Thus 16 bit unorm is the better mesh format by far.
• • •
Missing some Tweet in this thread? You can try to
force a refresh




