
Watching @karpathy presentation from today and taking twitter notes, come along for the ride:
If you're like only the practical tips, skip to #32
@karpathy starts with stages:
1 - Pre-training - months x thousands of GPUs
2, 3, 4 - Finetuning stages that take hours or days
1/
If you're like only the practical tips, skip to #32
@karpathy starts with stages:
1 - Pre-training - months x thousands of GPUs
2, 3, 4 - Finetuning stages that take hours or days
1/

Before pre-training happens, there are 2 preparation steps.
Data collection - Get tons of data from different sources (here Andrej LLaMa mixture)
Tokenization - a lossless translations between pieces of words and integers.
2/
Data collection - Get tons of data from different sources (here Andrej LLaMa mixture)
Tokenization - a lossless translations between pieces of words and integers.
2/


"You shouldn't judge the power of the model just by the number of parameters it contains"
LLaMa has trained on 1-1.4 Trillion tokens vs 300B tokens in GPT-3.
3/
LLaMa has trained on 1-1.4 Trillion tokens vs 300B tokens in GPT-3.
3/

"I don't have enough time to go into how transformers work unfortunately" 😂 Gotta love Andrej thirst for teaching!
I cannot summarize this into a tweet tbh.
4/
I cannot summarize this into a tweet tbh.
4/
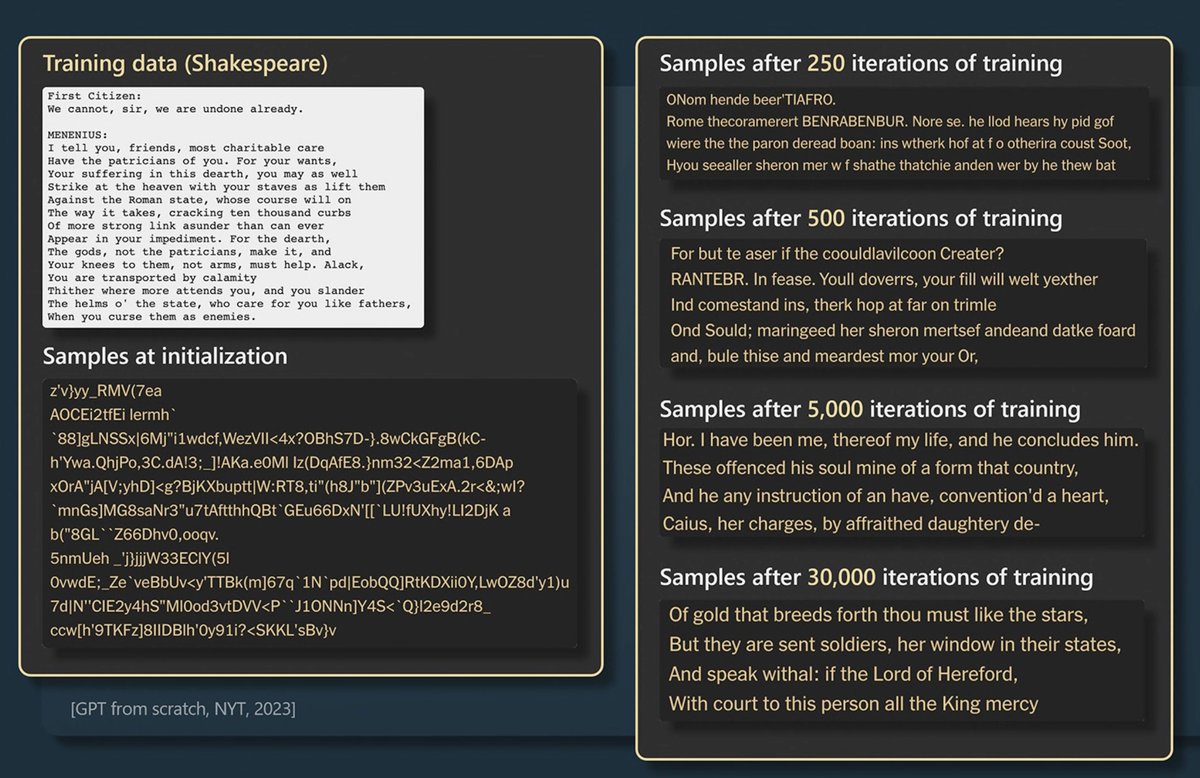
Here's an example from NYT who trained a GPT model on Shakespeare
You can see continued improved after many iterations of how the LM is getting better at predicting what next word would come in a Shakespeare text.
5/
You can see continued improved after many iterations of how the LM is getting better at predicting what next word would come in a Shakespeare text.
5/
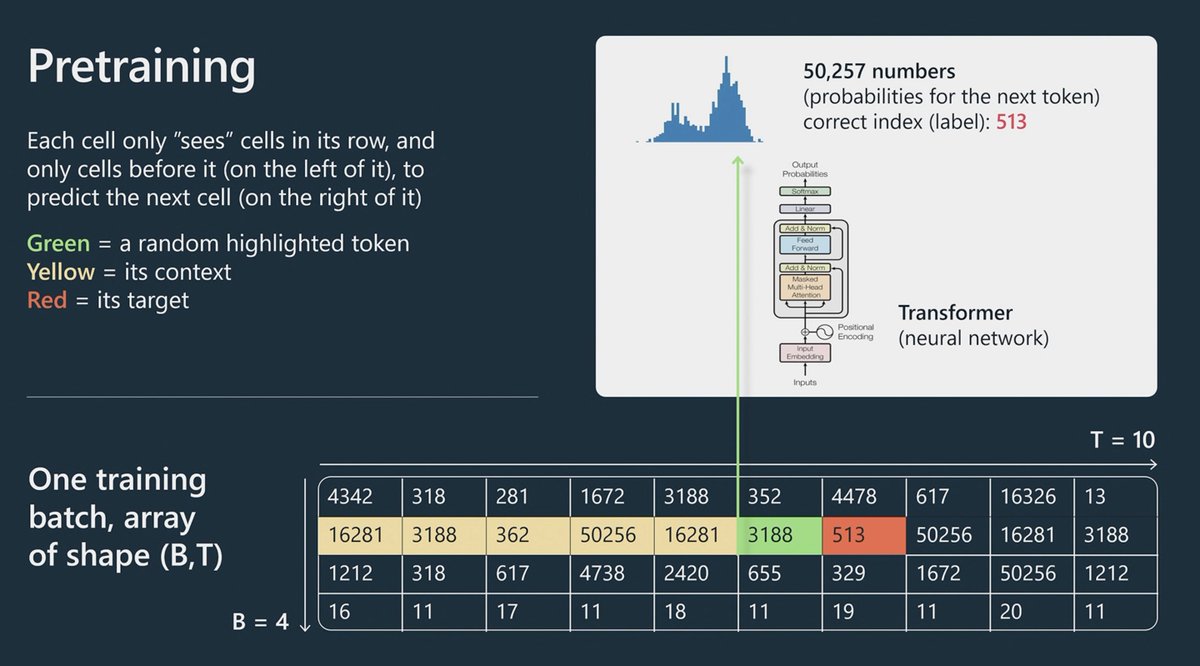
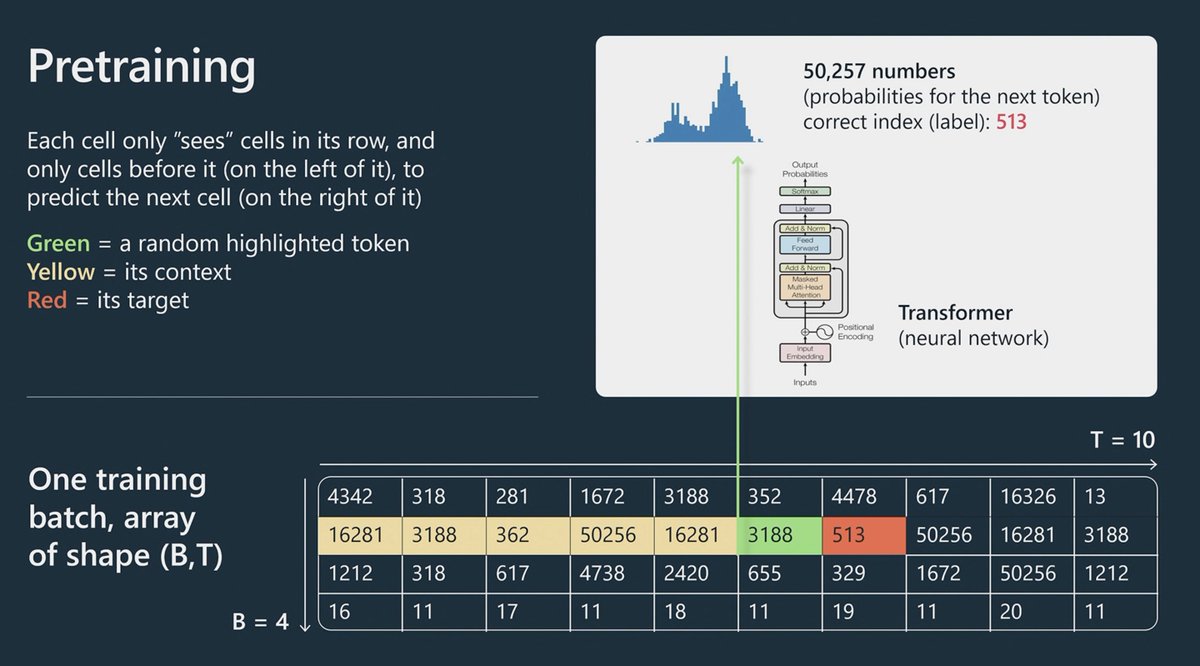
Ok STRONGLY paraphrasing here but, every iteration, the trainee model tries to predict which token/integer would come next after the green one (in image) and this is outlined by the Training curve, how well does is it able to predict the next tokens compared the original text
6/
6/

Around GPT-2, the industry noticed that if we structure out prompts in a specific way, and provide a few examples (Few Shot prompting) then the base model will be "tricked" into autocompleting what instructions we provided it in prompt.
7/
7/

Andrej repeats this several times, the best open source model to learn from right now is probably LLaMa from @MetaAI (since OAI didn't release anything about GPT-4)
GPT-2 - released + weights
GPT-3 - base model available via API (da-vinci)
GPT-4 - Not Available via API
8/
GPT-2 - released + weights
GPT-3 - base model available via API (da-vinci)
GPT-4 - Not Available via API
8/
Base models are not assistants, they don't "do what you ask them" in the basic sense. They just autocomplete text.
But if you structure your document with Few-shot prompts, it will "trick" the base model to think that it autocompletes a chat between an AI and a human
9/
But if you structure your document with Few-shot prompts, it will "trick" the base model to think that it autocompletes a chat between an AI and a human
9/
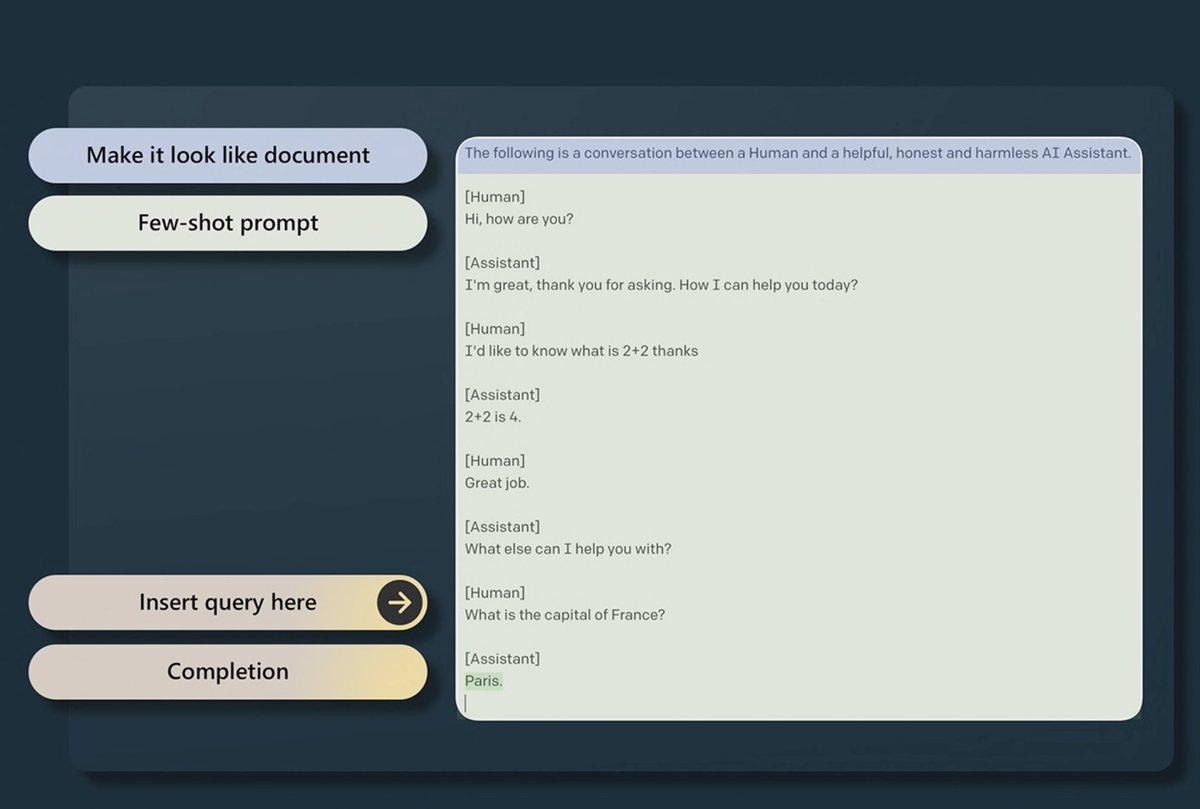
But this trick is not enough. So we're moving to step 2.
Supervised Finetuning.
Collecting small but high quality (think human contractors) datasets of instructions
And continue training the model with a swapped dataset now and we get the SFT (supervised finetuning) model.
10/
Supervised Finetuning.
Collecting small but high quality (think human contractors) datasets of instructions
And continue training the model with a swapped dataset now and we get the SFT (supervised finetuning) model.
10/

SFT model is... not great yet, definitely not chatGPT quality. So the training continues
Generating outputs of questions with the SFT model, users review and compare between 3 versions & rank which was the best, and then the model is retrained on the selections by the users
11/
Generating outputs of questions with the SFT model, users review and compare between 3 versions & rank which was the best, and then the model is retrained on the selections by the users
11/

This is done by wighting the better voted on responses. For example, when you hit 👍 or 👎 in chatGPT, or choose to regenerate a response, those signals are great for RLHF.
12/
12/
Andrej is going into the potential reasons of why RLHF models "feel" better to us. At least in terms being a good assistant.
Here again if anyone's still reading, I'll refer you to the video 😅
13/
Here again if anyone's still reading, I'll refer you to the video 😅
13/
Interestingly, Andrej talks about RLHF are not strictly improvements on base models. RLHF models have less enthropy so it is less "inventive" potentially.
For that base models are still better because they are still chaotic.
14/
For that base models are still better because they are still chaotic.
14/

This is the current state of models as ranked by folks from Berkley based on ranking.
Interestingly here, @karpathy here says that GPT-4 is the best "by far", but on the chart its 1274 to Claude's 1224 ELO rating that doesn't seem "by far"
Imsys.org/blog/2023-05-1…
15/
Interestingly here, @karpathy here says that GPT-4 is the best "by far", but on the chart its 1274 to Claude's 1224 ELO rating that doesn't seem "by far"
Imsys.org/blog/2023-05-1…
15/

RLHF models are better ranked, all the top 3 are RLHF models and the rest (to his knowledge are SFT models)
Wohoo! We're through the first half of the talk. Moving to Application of these models to problems.
16/
Wohoo! We're through the first half of the talk. Moving to Application of these models to problems.
16/

Andrej then goes fairly in depth into the difference between a human being process of writing a statement like
"California's population is 53 times that of Alaska"
A human brain goes through loops, fact checks, calculation, reflection.
17/
"California's population is 53 times that of Alaska"
A human brain goes through loops, fact checks, calculation, reflection.
17/

While a GPT is trying to autocomplete, there is no internal dialog in GPT.
It spends the same amount of "compute" per token, no matter if the token is a number it needs to look up or a fact it needs to check, but they have vast knowledge and perfect memory (context window)
18/
It spends the same amount of "compute" per token, no matter if the token is a number it needs to look up or a fact it needs to check, but they have vast knowledge and perfect memory (context window)
18/

Methods like Chain of thought provide models with "more tokens" or "more time to think" by asking "let's think step by step"
Which will make the model to show it's work, and this will give it "time to think" for a better answer
19/
Which will make the model to show it's work, and this will give it "time to think" for a better answer
19/

Now Andrej is going into Self Reflection as a method.
Models can get "stuck" because they have no way to cancel what tokens they already sampled.
Imagine yourself saying the wrong word and stopping yourself in the middle "let me rephrase" and you re-start the sentence
20/
Models can get "stuck" because they have no way to cancel what tokens they already sampled.
Imagine yourself saying the wrong word and stopping yourself in the middle "let me rephrase" and you re-start the sentence
20/
Models don't have that luxury so they can get stuck down that wrong path...
But examples like self-reflection show that asking the model to review it's output, judge it, gives models a "second change" or another pass over the reasoning of the output which improves results!
21/
But examples like self-reflection show that asking the model to review it's output, judge it, gives models a "second change" or another pass over the reasoning of the output which improves results!
21/

I love it, Andrej uses the Thinking Fast and Slow - system 1 and system 2 models of our thinking to LLMs.
These techniques like CoT, Self Reflexion and the recently released Tree of thought are our attempt to build system 2, the slower, more deliberate thinking
👌 analogy.
22/
These techniques like CoT, Self Reflexion and the recently released Tree of thought are our attempt to build system 2, the slower, more deliberate thinking
👌 analogy.
22/

Here's the update on Tree of Thought, they just dropped the code on Github!
Thanks @ShunyuYao12 👏
23/
Thanks @ShunyuYao12 👏
23/
https://twitter.com/ShunyuYao12/status/1661143117024886784
Andrej also calls out #AutoGPT ( by @SigGravitas ) as a project that got overhyped but is still very interesting to observe and get inspiration from
I'll plug in my twitter list of "Agent" builders that includes many of those folks
twitter.com/i/lists/164293…
24/
I'll plug in my twitter list of "Agent" builders that includes many of those folks
twitter.com/i/lists/164293…
24/
But Andrej doesn't think this currently works very well for production. But folks should "watch this space"
Moving on:
"LLM's don't WANT to succeed, a human wants to"
Transformers work better when asked to work better.
25/
Moving on:
"LLM's don't WANT to succeed, a human wants to"
Transformers work better when asked to work better.
25/

My personal prepend to most prompts is this one, but also things like "you have X IQ" work!
26/
26/
https://twitter.com/altryne/status/1645818789202919425
Ok this next slide, I made almost verbatim the same one in my presentation 3 days ago! Haha, impostor syndrome begone
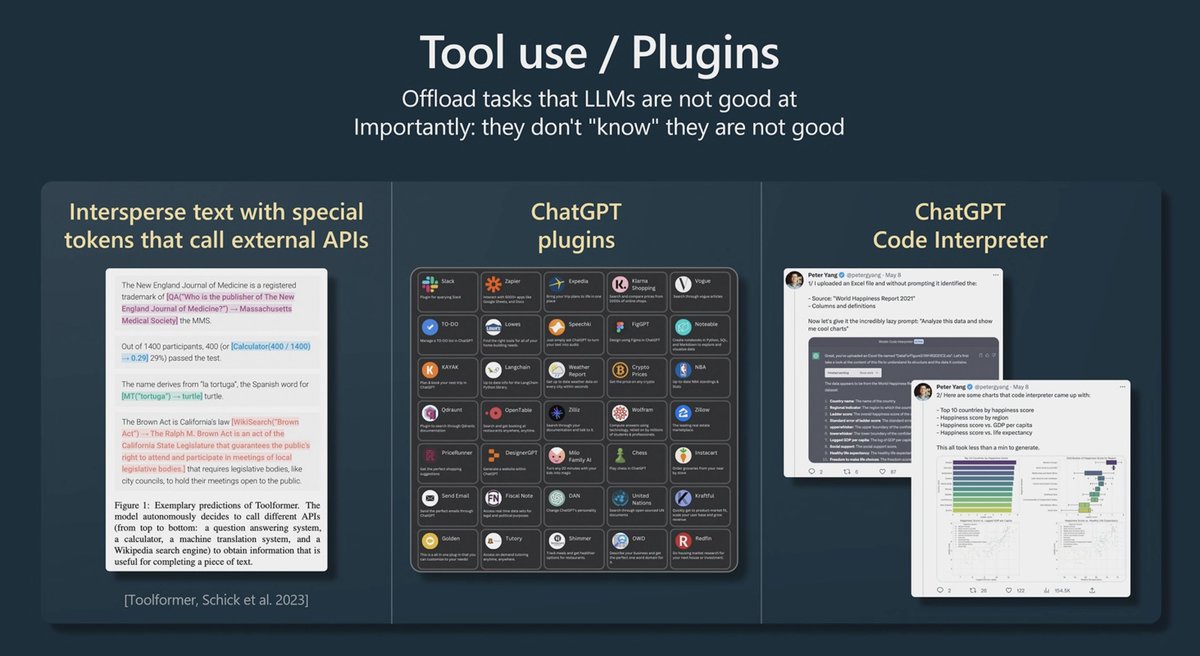
Watch the plugin space, as providing the models with plugins/tools like calculator, code interpreter, search etc'
Remember, bing is coming to chatGPT!
27/
Watch the plugin space, as providing the models with plugins/tools like calculator, code interpreter, search etc'
Remember, bing is coming to chatGPT!
27/
"Context window of the transformer is it's working memory"
The model has immediate perfect access to it's working memory.
Andrej calling out @gpt_index by @jerryjliu0 on stage as an example of a way to "load" information into this perfect recall working memory.
28/
The model has immediate perfect access to it's working memory.
Andrej calling out @gpt_index by @jerryjliu0 on stage as an example of a way to "load" information into this perfect recall working memory.
28/

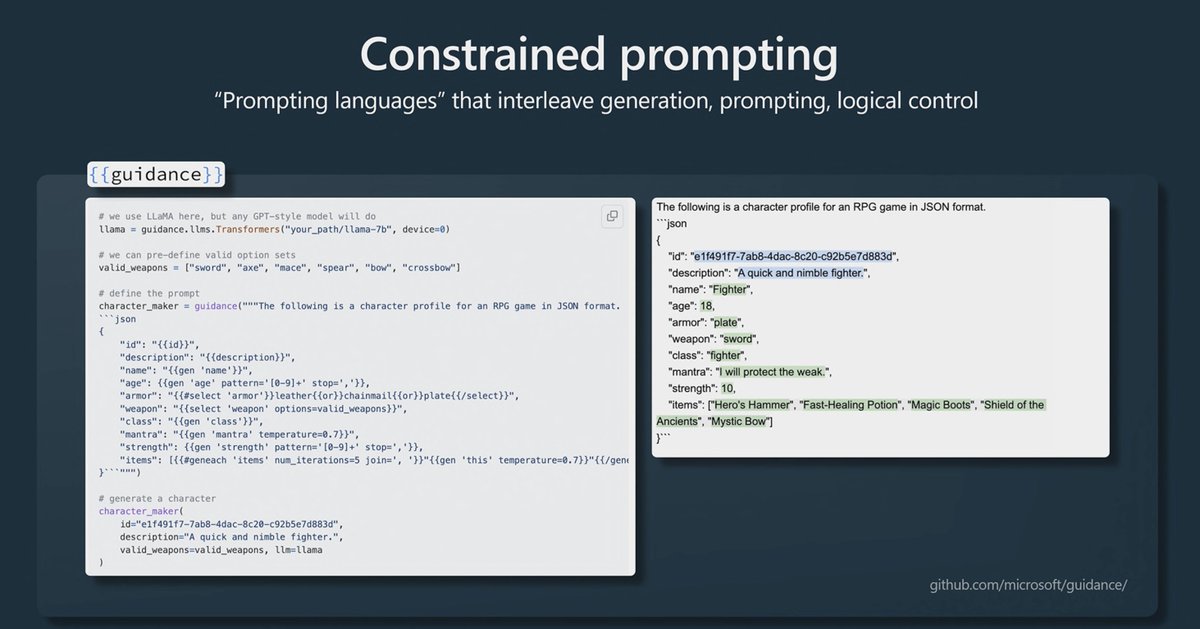
Yay, he's covering the guidance project from Microsoft, that constraints the prompt outputs.
github.com/microsoft/guid…
29/
github.com/microsoft/guid…
29/
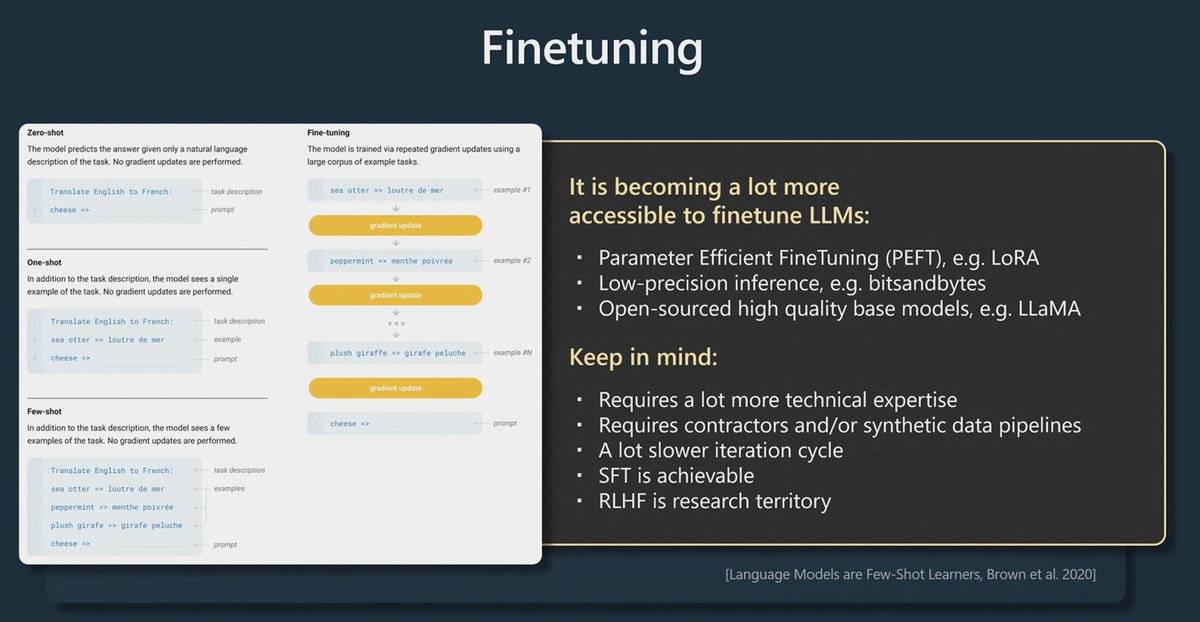
On to Finetuning - Prompt engineering can only take you so far. (could be really far)
Fine-tuning changes the weights of the models. Works for smaller and open source models.
With methods like LoRa allow you to only train small pieces of the large model which reduces costs
30/
Fine-tuning changes the weights of the models. Works for smaller and open source models.
With methods like LoRa allow you to only train small pieces of the large model which reduces costs
30/
This is way more efficient than retraining the whole model, and is more available.
Andrej again calls out LlaMa as the best open source fine-tuneable model and is hinting at @ylecun to open source it for commercial use 😅🙏
31/
Andrej again calls out LlaMa as the best open source fine-tuneable model and is hinting at @ylecun to open source it for commercial use 😅🙏
31/
If you'd like @karpathy's practical examples - start from here 👇
This is the de-facto "kitchen sink" for building a product with an LLM goal/task.
32/
This is the de-facto "kitchen sink" for building a product with an LLM goal/task.
32/

"Use GPT-4 he says, it's by far the best."
I personally noticed Claude being very good at certain tasks, and it's way faster for comparable tasks so, y'know if you have access, I say evaluate. But he's not wrong, GPT-4 is... basically amazing.
Can't wait for Vision 😍
33/
I personally noticed Claude being very good at certain tasks, and it's way faster for comparable tasks so, y'know if you have access, I say evaluate. But he's not wrong, GPT-4 is... basically amazing.
Can't wait for Vision 😍
33/
https://twitter.com/altryne/status/1658357541846552582
"What would you tell a task contractor if they can't email you back" is a good yard stick at a complex prompt by Andrej.
From me: for example, see wolfram alpha's prompt
34/
From me: for example, see wolfram alpha's prompt
34/
https://twitter.com/dmvaldman/status/1658689854056853504
Retrieve and add any relevant context or information to the prompt.
And shove as many examples of how you expect the results to look like in the prompting.
Me: Here tools like @LangChainAI and @trychroma come into play, use them to enrich your prompts.
35/
And shove as many examples of how you expect the results to look like in the prompting.
Me: Here tools like @LangChainAI and @trychroma come into play, use them to enrich your prompts.
35/
Experiment with tools/plugins to offload tasks like calculation, code execution.
Andrej also suggest first achieving your task, and only then optimize for cost.
Me: removing the constraint of "but this will be very costly" definitely helps with prompting if you can afford
36/
Andrej also suggest first achieving your task, and only then optimize for cost.
Me: removing the constraint of "but this will be very costly" definitely helps with prompting if you can afford
36/
If you've maxed out prompting, and he again repeats, prompting can take you very far, then your company can decide to move to fine-tuning and RLHF on your own data.
37/
37/
Optimizing for costs :
- Use lower quality models if they execute on your specific tasks
- Gradually reduce number of tokens of your prompt while testing the output to reduce costs.
38/
- Use lower quality models if they execute on your specific tasks
- Gradually reduce number of tokens of your prompt while testing the output to reduce costs.
38/

Models may be biased
Models may fabricate ("hallucinate") information
Models may have reasoning errors
Models may struggle in classes of applications, e.g. spelling related tasks
Models have knowledge cutoffs (e.g. September 2021)
Models are susceptible to prompt injection
39/
Models may fabricate ("hallucinate") information
Models may have reasoning errors
Models may struggle in classes of applications, e.g. spelling related tasks
Models have knowledge cutoffs (e.g. September 2021)
Models are susceptible to prompt injection
39/
So for may 2023 - per Andrej Karpahy, use LLMs for these tasks:
⭐ Use in low-stakes applications, combine with human oversight
⭐ Source of inspiration, suggestions
⭐ Copilots over autonomous agents
40/
⭐ Use in low-stakes applications, combine with human oversight
⭐ Source of inspiration, suggestions
⭐ Copilots over autonomous agents
40/
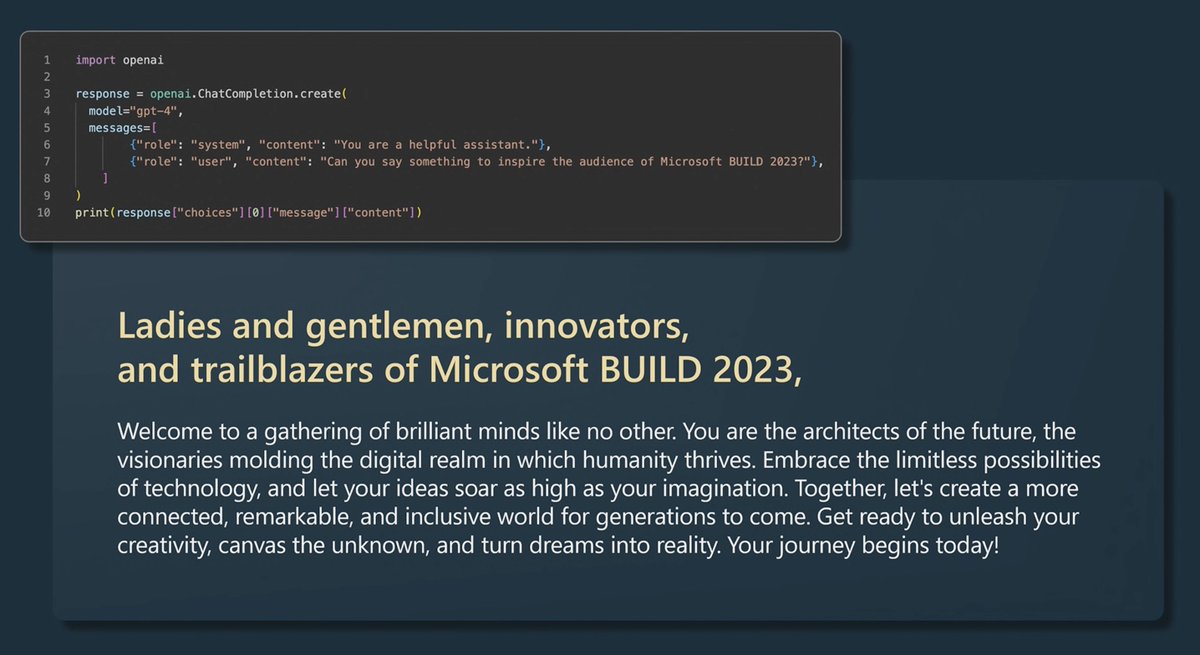
Finally, Andrej concludes with an example of how easy it is to ask for a completion, and with GPT-4 generated address to the audience of #microsoftBuild which he reads in a very TED like cadence to the applauds from the audience!
Thanks @karpathy
41/
Thanks @karpathy
41/
And yeah, I made this thread as I was watching, if you like these or my bling reactions, y'know... follow me @altryne :) and @karpathy of course duh.
42/
42/
Oh and duh, here is the video! 😶
I meant for the first tweet to be a quote of Andrey's tweet but then... got rugged by twitter
I meant for the first tweet to be a quote of Andrey's tweet but then... got rugged by twitter
https://twitter.com/karpathy/status/1661176583317487616?s=20
• • •
Missing some Tweet in this thread? You can try to
force a refresh








