
4-bit QLoRA is here to equalize the playing field for LLM exploration. You can now fine-tune a state-of-the-art 65B chatbot on one GPU in 24h.
Paper: arxiv.org/abs/2305.14314
Code and Demo: github.com/artidoro/qlora
Paper: arxiv.org/abs/2305.14314
Code and Demo: github.com/artidoro/qlora
https://twitter.com/Tim_Dettmers/status/1661379354507476994
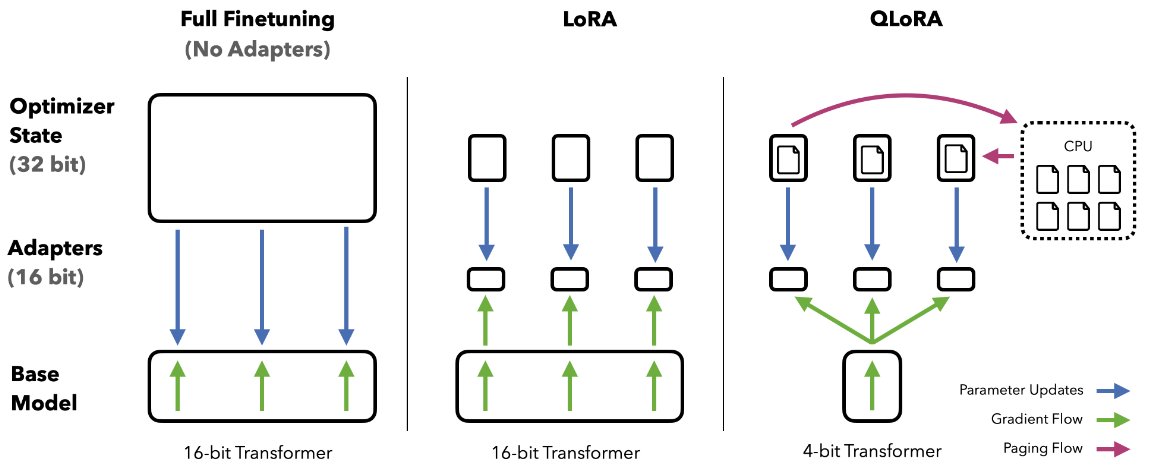
QLoRA uses a frozen 4-bit base model with adapters. We backpropagate through the 4-bit weights into the adapters. QLoRA incorporates the NF4 datatype, double-quantization, and paged optimizers. We show it is on par with 16-bit finetuning at a fraction of the memory footprint. 
QLoRA tuning on the OpenAssistant dataset produces a state-of-the-art chatbot.
According to GPT-4 and human annotators, our models outperform all other open-source systems and are even competitive with ChatGPT.
According to GPT-4 and human annotators, our models outperform all other open-source systems and are even competitive with ChatGPT.

The paper arxiv.org/abs/2305.14314 contains lots of insights and considerations about instruction tuning and chatbot evaluation and points to areas for future work.
In particular:
- instruction tuning datasets are not necessarily helpful for chatbot performance
- quality of data rather than quantity is important for chatbots
- multitask QA benchmarks like MMLU are not always correlated with chatbot performance
- instruction tuning datasets are not necessarily helpful for chatbot performance
- quality of data rather than quantity is important for chatbots
- multitask QA benchmarks like MMLU are not always correlated with chatbot performance
- both human and automated evaluations are challenging when comparing strong systems
- using large eval datasets with many prompts, like the OA benchmark, is important for evaluation
- many possible improvements to our setup including RLHF explorations
- using large eval datasets with many prompts, like the OA benchmark, is important for evaluation
- many possible improvements to our setup including RLHF explorations
Guanaco is *far from perfect*, but the fact that it is remarkably easy to train with QLoRA while obtaining strong chatbot performance makes it a perfect starting point for future research.
Thank you to @Tim_Dettmers @universeinanegg @LukeZettlemoyer and the many people who made this project possible! In particular, @younesbelkada and the @huggingface team. It's been amazing working with you
• • •
Missing some Tweet in this thread? You can try to
force a refresh



