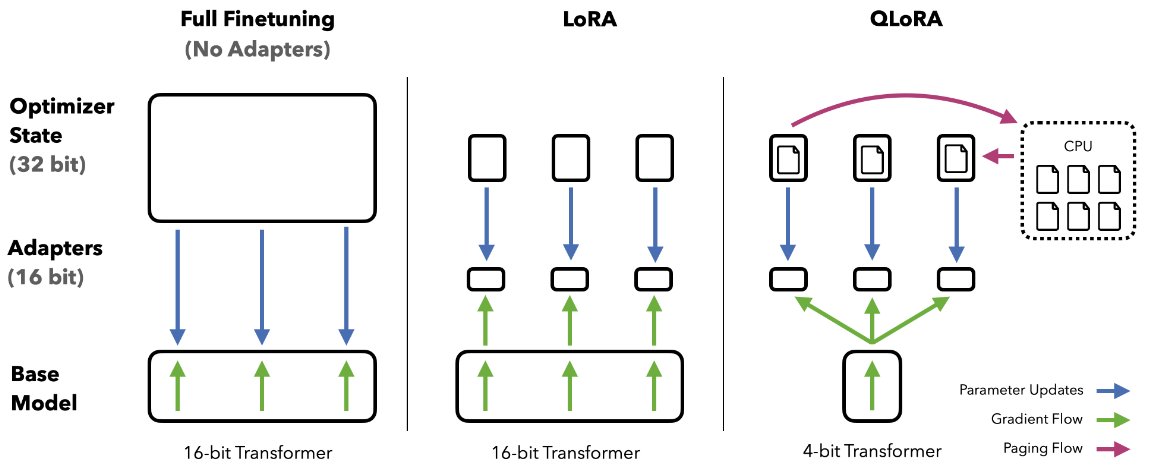
QLoRA uses a frozen 4-bit base model with adapters. We backpropagate through the 4-bit weights into the adapters. QLoRA incorporates the NF4 datatype, double-quantization, and paged optimizers. We show it is on par with 16-bit finetuning at a fraction of the memory footprint.