
I need a thing that listens to speech, and holds some state. this is an old project that I'm resurrecting
I will keep this thread updated
I will keep this thread updated
TIL about sampling rates, channels, etc
stdin works, saves file
setting up my devloop.
just need to figure out how to get ffmpeg to do the same so I don't have to record myself speaking
ideally the logic triggers on save with the whole "speech"
stdin works, saves file
setting up my devloop.
just need to figure out how to get ffmpeg to do the same so I don't have to record myself speaking
ideally the logic triggers on save with the whole "speech"

setting up the dev loop from a different source was a good exercise
subjecting myself to slowmo'd noisy sam hyde rant because I messed up bit depth (TIL)
I think i have a reasonably constrained interface & understand how audio data works
I will now think about eventing
subjecting myself to slowmo'd noisy sam hyde rant because I messed up bit depth (TIL)
I think i have a reasonably constrained interface & understand how audio data works
I will now think about eventing

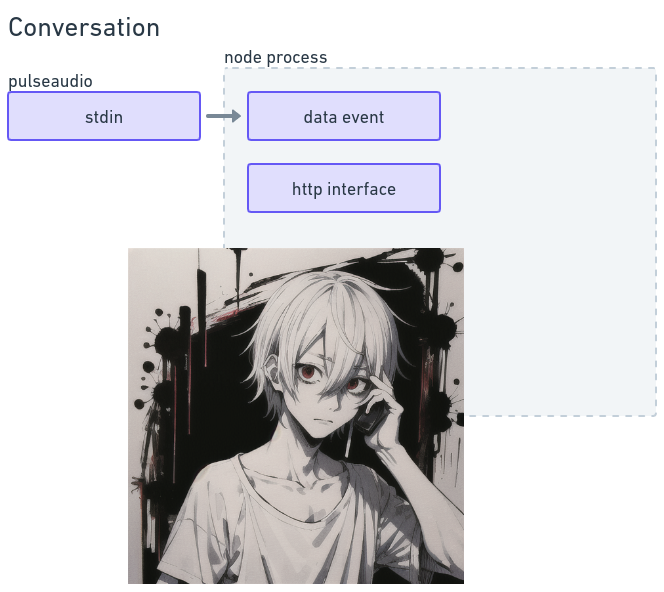
Eventing depends on the decoding system
Naively, you can chunk and spread it across discrete TTS inferences
However, there are gotchyas
Whisper is trained on 30s chunks
You can have a running inference that keeps up
But maybe there is something faster
I will look at research
Naively, you can chunk and spread it across discrete TTS inferences
However, there are gotchyas
Whisper is trained on 30s chunks
You can have a running inference that keeps up
But maybe there is something faster
I will look at research
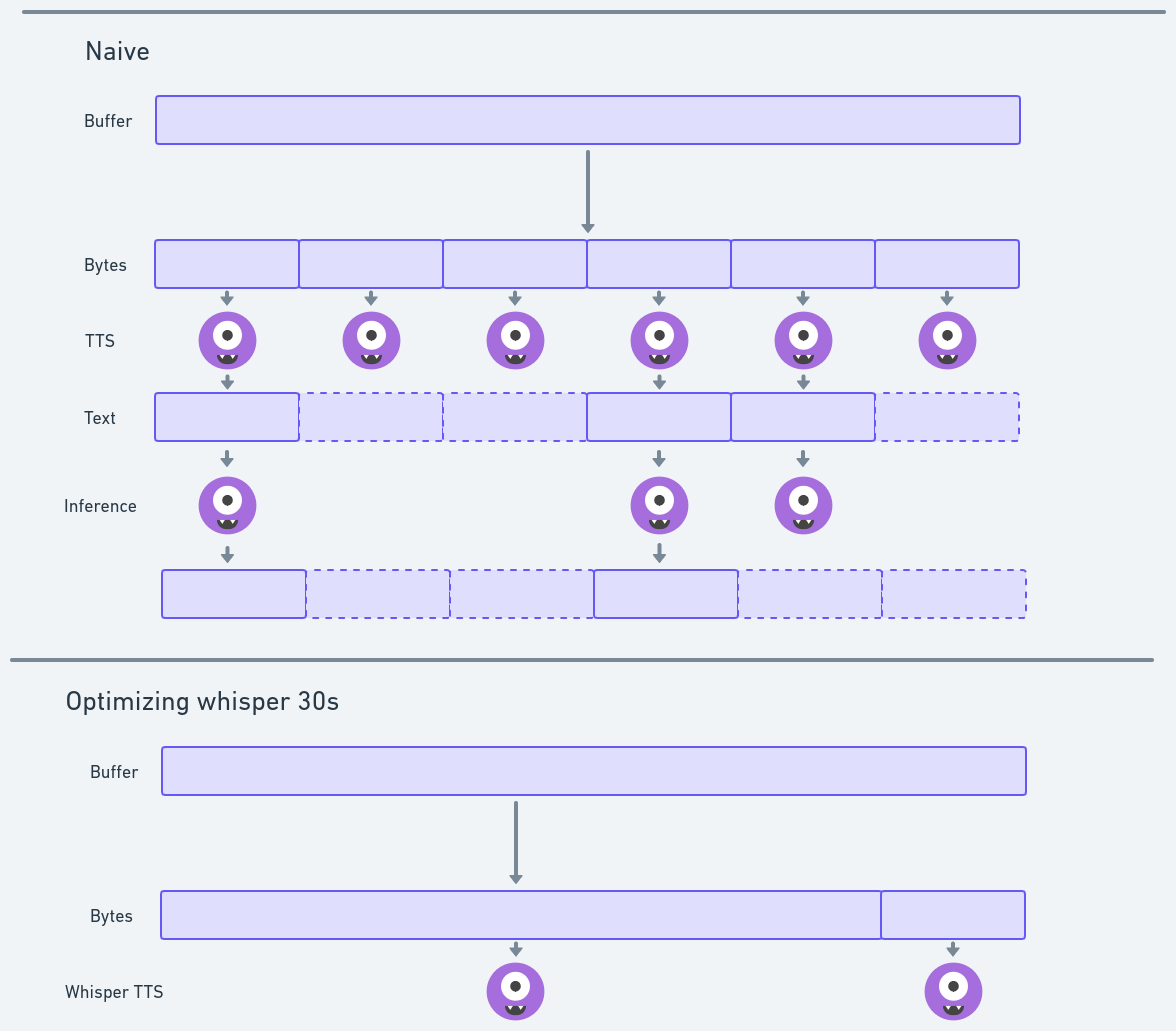
I spent like 3 hours looking at different whisper implementations / ways to run just to come to the conclusion:
wait for gregg to port to c++
every single python implementation abstracts way too much, and just ends up running like dogshit
ggml is WAY faster, and I get probs ez
wait for gregg to port to c++
every single python implementation abstracts way too much, and just ends up running like dogshit
ggml is WAY faster, and I get probs ez

i simply cannot be trusted with node dot js (the best runtime environment for hobby projects) and gpt4 teaching me how to do non standard things
(instead of having a server that I outbound to, I will call a cbinding)
(instead of having a server that I outbound to, I will call a cbinding)

2 hours later, I have figured out how node gyp works
👍
switching to mbook to see if it works across machines
👍
switching to mbook to see if it works across machines
I figured out how to link my cuda libraries in, so I can load the model on my GPU
this is the first time I've see node pop up on nvidia-smi. hahahahahaha
we'll see if i can get inference to work
this is the first time I've see node pop up on nvidia-smi. hahahahahaha
we'll see if i can get inference to work
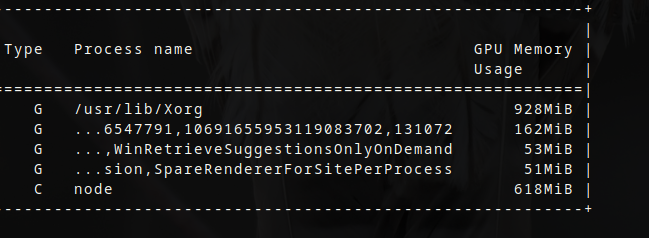
ahahhhaha
the only reasonable thing to do to debug data handoff between node.js & cpp land?
writing the whole buffer to file; and checking md5, comparing to natty whispercpp
the only reasonable thing to do to debug data handoff between node.js & cpp land?
writing the whole buffer to file; and checking md5, comparing to natty whispercpp
pythonistas...
it's over..
..i just got an inference through from a cbinding
(TIL how computers work)
it's over..
..i just got an inference through from a cbinding
(TIL how computers work)

WHAT DOES LITTLE ENDIAN MEAN????
LETS GOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOO
LETS GOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOOO
@teleoflexuous also Alexa sucks
these are the times calling whisper from node.js on a macbook pro max
had to figure out how to compile with coreML and link it to node binding
220 ms per transcription 🤩
had to figure out how to compile with coreML and link it to node binding
220 ms per transcription 🤩

back to it
got it going from my mic
got it going from my mic

NEXT WE ARE MAKING IT THINK

LFG!
found some code that has bindings to llama for node
it was written in rust. did not wake up thinking i would be reading rust today
Thank you @hlhr202! https://t.co/fZA5ttpIYgtwitter.com/i/web/status/1…
found some code that has bindings to llama for node
it was written in rust. did not wake up thinking i would be reading rust today
Thank you @hlhr202! https://t.co/fZA5ttpIYgtwitter.com/i/web/status/1…

@hlhr202 token go brrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrrr 🤩
my node process says hello
my node process says hello
@hlhr202 okay breaks over
lets see what kind of goofy shit we can accomplish now
I want to have some kind of scheduler that doesn't fry gpu
lets see what kind of goofy shit we can accomplish now
I want to have some kind of scheduler that doesn't fry gpu

@hlhr202 okay, I gotta throw the towel in
i tried thinking about scheduler but brain is mush
it is pretty wild that my computer is literally thinking thoughts as I speak to it though. the future is now!
i tried thinking about scheduler but brain is mush
it is pretty wild that my computer is literally thinking thoughts as I speak to it though. the future is now!
@hlhr202 oh ho ho, what do we have here, an unfinished project?
okay, the next step is ripping out the dependency and writing it myself (the llama binding pkg i found) (I do not understand rust nor can i debug it, so I will rawdog the c bindings again)
also it will run on macbook by eod
okay, the next step is ripping out the dependency and writing it myself (the llama binding pkg i found) (I do not understand rust nor can i debug it, so I will rawdog the c bindings again)
also it will run on macbook by eod

@hlhr202 me, looking at the GPT4 generated c plus plus I "wrote" a week ago at a cottage bachelor party 2 beers deep

@hlhr202 it might not look like much but i figured out how to get an event emitter from c plus plus without blocking the main thread
i also know how memory management and threading works on computers a little bit better
i also know how memory management and threading works on computers a little bit better
@hlhr202 yeah im cookin
@hlhr202 LETS GO!
- Init function from node.js which instantiates llama parameters
- Then; startAsync which starts a non blocking inference off of the node.js main worker thread, which calls an event listener on every new token
genuinely can't believe i did it lmao https://t.co/RjvS6DKwevtwitter.com/i/web/status/1…
- Init function from node.js which instantiates llama parameters
- Then; startAsync which starts a non blocking inference off of the node.js main worker thread, which calls an event listener on every new token
genuinely can't believe i did it lmao https://t.co/RjvS6DKwevtwitter.com/i/web/status/1…
@jpmaney
here it is :)
still needs a bit of cleaning, I'll give it another pass later before I point the diff at the master origin
but it should be runnable now
Progress update: Added locks, because later, I want to do goofy things from my caller node https://t.co/syu3ifBGtxgithub.com/yacineMTB/llam…
here it is :)
still needs a bit of cleaning, I'll give it another pass later before I point the diff at the master origin
but it should be runnable now
Progress update: Added locks, because later, I want to do goofy things from my caller node https://t.co/syu3ifBGtxgithub.com/yacineMTB/llam…

@jpmaney 2 hours later i got it working on my linux machine as well
i now know how cMakeLists.txt works :|
never give up
thanks gpt4 for the help
i now know how cMakeLists.txt works :|
never give up
thanks gpt4 for the help
@jpmaney I redid the build system for whisper.cpp to use the same system i'm using for llama cpp
works
also made it actually async
works
also made it actually async
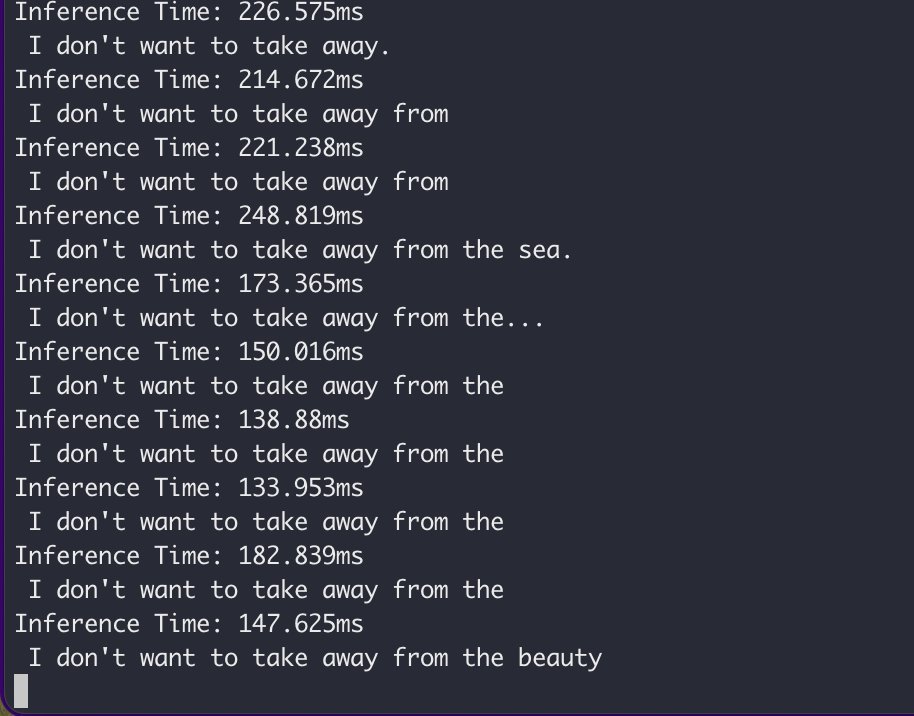
@jpmaney okay, this is running on my macbook on battery
Basically, my laptop is thinking thoughts while it listens to a yt video
It's still sync, waits for whisper, then does llama inference. But now that i have my grubby hands on it I can do little tricks to make it fast :)
gn
Basically, my laptop is thinking thoughts while it listens to a yt video
It's still sync, waits for whisper, then does llama inference. But now that i have my grubby hands on it I can do little tricks to make it fast :)
gn
@jpmaney ok
i'm focused
I have three hours
today's the day
it's time to clutch it
i'm focused
I have three hours
today's the day
it's time to clutch it

@jpmaney Picking up an old design i had
A strategy to minimize latency on responses
A strategy to minimize latency on responses

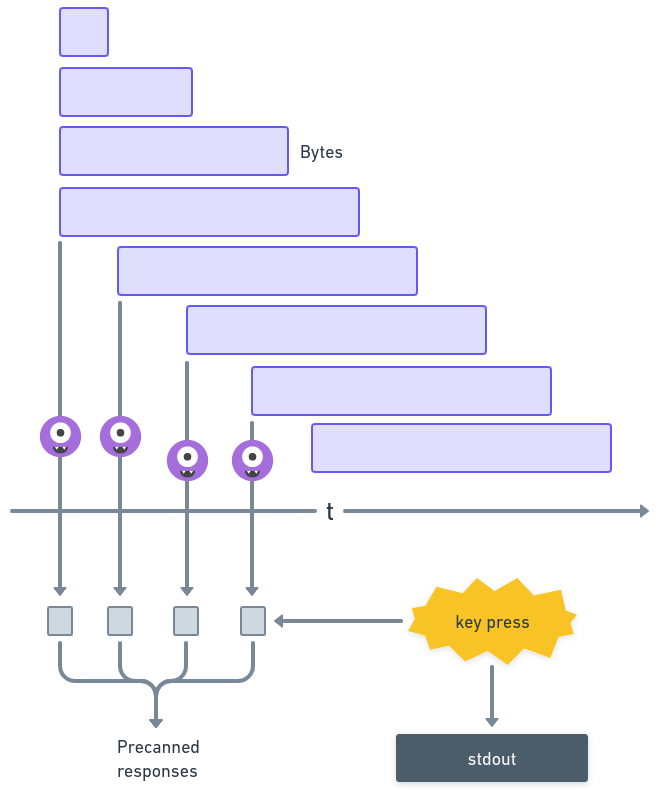
@jpmaney also here's the "architecture"

@jpmaney Running the inferences on whisper.cpp & llama.cpp at the same time. This works pretty well!
Using @Teknium1's hermes-13b model
audio warning - tried to time it honestly to give a feel for the latency. Next; I'm going to start testing me actually talking to it
Using @Teknium1's hermes-13b model
audio warning - tried to time it honestly to give a feel for the latency. Next; I'm going to start testing me actually talking to it
@jpmaney @Teknium1
@jpmaney @Teknium1

@jpmaney @Teknium1
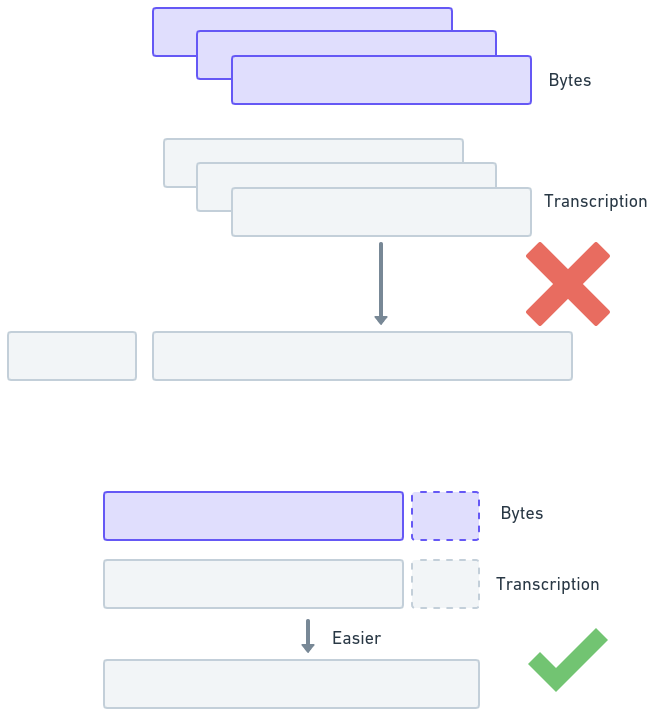
@jpmaney @Teknium1 Diff in
didn't get to the code that chooses when to have the bot begin responding, which I'm calling the "speech reflex" event (right now i'ts just a hotkey press)
Also created issues
https://t.co/AQlH1nwKj0
https://t.co/YXSgRX8eyngithub.com/yacineMTB/talk…
github.com/yacineMTB/talk…
github.com/yacineMTB/talk…
didn't get to the code that chooses when to have the bot begin responding, which I'm calling the "speech reflex" event (right now i'ts just a hotkey press)
Also created issues
https://t.co/AQlH1nwKj0
https://t.co/YXSgRX8eyngithub.com/yacineMTB/talk…
github.com/yacineMTB/talk…
github.com/yacineMTB/talk…
@jpmaney @Teknium1 okay, I've decided
I will be using synesthesiam's mimicv3 and
thank you for the contribution <3github.com/rhasspy/piper
I will be using synesthesiam's mimicv3 and
thank you for the contribution <3github.com/rhasspy/piper
@jpmaney @Teknium1 I wrote an audio player manager in ts, that spawns a script
Eventually, will replace with binding, but I don't have time for that right now. I should write the binding because most of the inference time (80% by my estimation) is loading the model weights
video demo of audio gen
Eventually, will replace with binding, but I don't have time for that right now. I should write the binding because most of the inference time (80% by my estimation) is loading the model weights
video demo of audio gen
@jpmaney @Teknium1 I've got a good conversational state tracker.
The speed of the TTS + llama makes it such that chunking out things greedily from token stream makes it extremely fast. See latency between keeb press and "well" being voiced
Therefore will avoid using "precanned thoughts"
The speed of the TTS + llama makes it such that chunking out things greedily from token stream makes it extremely fast. See latency between keeb press and "well" being voiced
Therefore will avoid using "precanned thoughts"
@jpmaney @Teknium1 Changing strategy, ditched the node bindings on llamacpp (getting seg fault and don't have time to debug), running server as side car instead.
It was a good effort! I understand the forward pass better now
Really fast with new llama cuda pr. like really, really, really fast
It was a good effort! I understand the forward pass better now
Really fast with new llama cuda pr. like really, really, really fast
@jpmaney @Teknium1 mulling over architecture
I know I want events
However; something feels wrong about the state that I am carrying forward
I know I want events
However; something feels wrong about the state that I am carrying forward
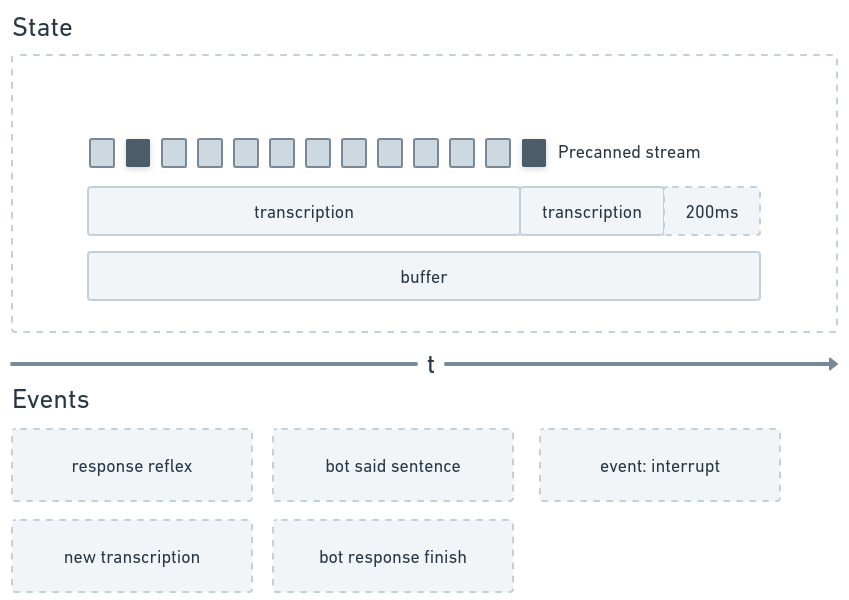
@jpmaney @Teknium1 I think what felt wrong is the event generating isn't that clear
This is better; if everything is constant, an event log generated from some buffer should be deterministic
I have been guided in the direction of designing a finite state machine, which maybe is a DAG
This is better; if everything is constant, an event log generated from some buffer should be deterministic
I have been guided in the direction of designing a finite state machine, which maybe is a DAG

@jpmaney @Teknium1

@jpmaney @Teknium1 btw i finished this and it works exceptionally better
@jpmaney @Teknium1 Here's a demo! Reworked with an event based architecture shared earlier. Some of the events are logging through too!
It's getting uncanny :)
Still have some weird state loop things, I'll give it another edit cycle at some point this week
@cto_junior https://t.co/4ODL9ph2UUgithub.com/yacineMTB/talk…
It's getting uncanny :)
Still have some weird state loop things, I'll give it another edit cycle at some point this week
@cto_junior https://t.co/4ODL9ph2UUgithub.com/yacineMTB/talk…
@ggerganov @jpmaney @Teknium1 @cto_junior I've actually learned a ton just walking through the cpp code the past few weeks, looking at LoRA, etc. It's all demystified when it's just code you're staring at. The big secret is that it's really actually kind of simple!
@moonares @jpmaney @Teknium1 @cto_junior the reason i'm building this is because I"m trying to higher bitrate interface with my computer
eventually, I want my whole screen captured, and provided as context to the godlike QA agent
eventually, I want my whole screen captured, and provided as context to the godlike QA agent

• • •
Missing some Tweet in this thread? You can try to
force a refresh



