I'm really excited to share @MedARC_AI's first paper since our public launch 🥳
🧠👁️ MindEye!
Our state-of-the-art fMRI-to-image approach that retrieves and reconstructs images from brain activity!
Project page: medarc-ai.github.io/mindeye/
arXiv: arxiv.org/abs/2305.18274
🧠👁️ MindEye!
Our state-of-the-art fMRI-to-image approach that retrieves and reconstructs images from brain activity!
Project page: medarc-ai.github.io/mindeye/
arXiv: arxiv.org/abs/2305.18274

We train an MLP using contrastive learning to map fMRI signals to CLIP image embeddings.
The generated embeddings can be used for retrieval, & the exact original image can be retrieved among highly similar candidates, showing that the embeddings retain fine-grained information.
The generated embeddings can be used for retrieval, & the exact original image can be retrieved among highly similar candidates, showing that the embeddings retain fine-grained information.

Scaling up the retrieval to a large database like LAION-5B allows MindEye to output realistic images from brain activity without using any generative model.

But we can do classic reconstruction too, with SOTA results!
For this purpose, we found it necessary to train a diffusion prior to further "align" the generated CLIP-fMRI embeddings with standard CLIP embeddings.
For this purpose, we found it necessary to train a diffusion prior to further "align" the generated CLIP-fMRI embeddings with standard CLIP embeddings.
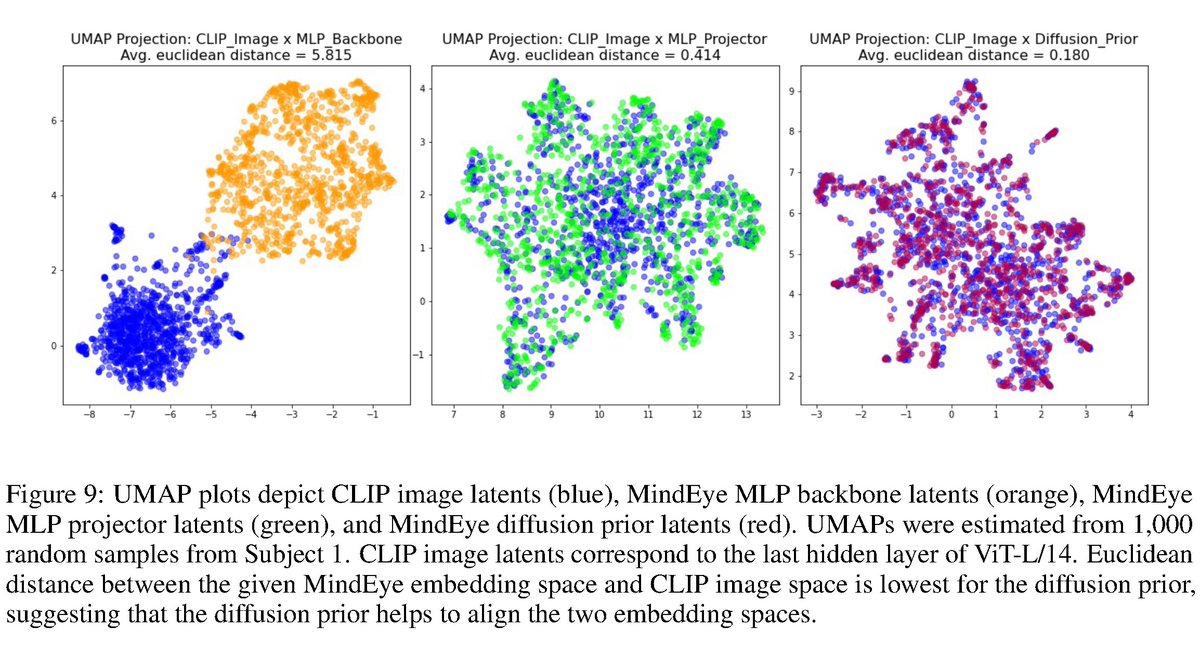
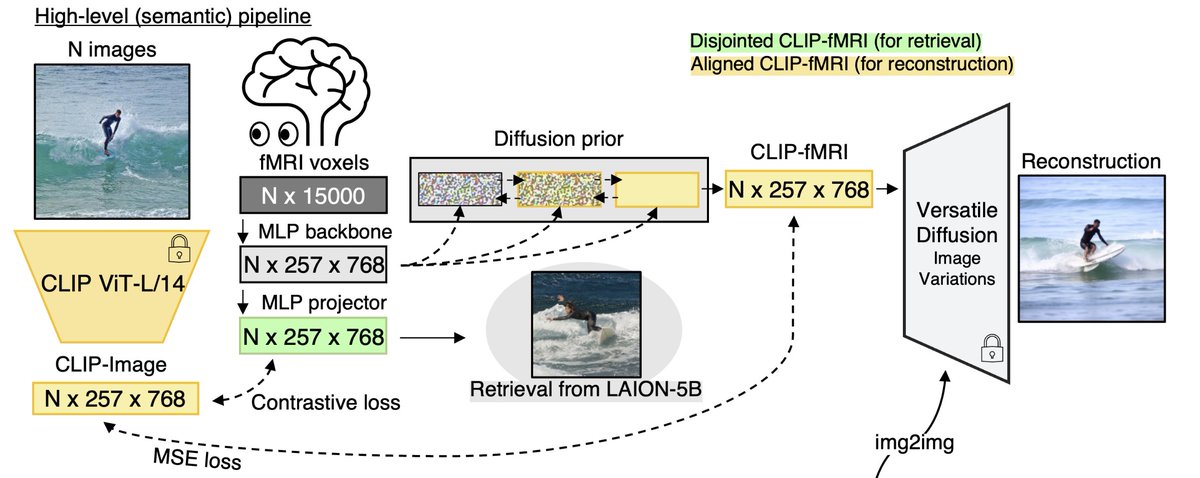
Once we obtain aligned CLIP image embeddings, we can pass it into any pretrained diffusion model that accepts CLIP image embeddings to perform reconstruction!
We find Versatile Diffusion gives best performance. Better image generation models in the future may give better recons!
We find Versatile Diffusion gives best performance. Better image generation models in the future may give better recons!
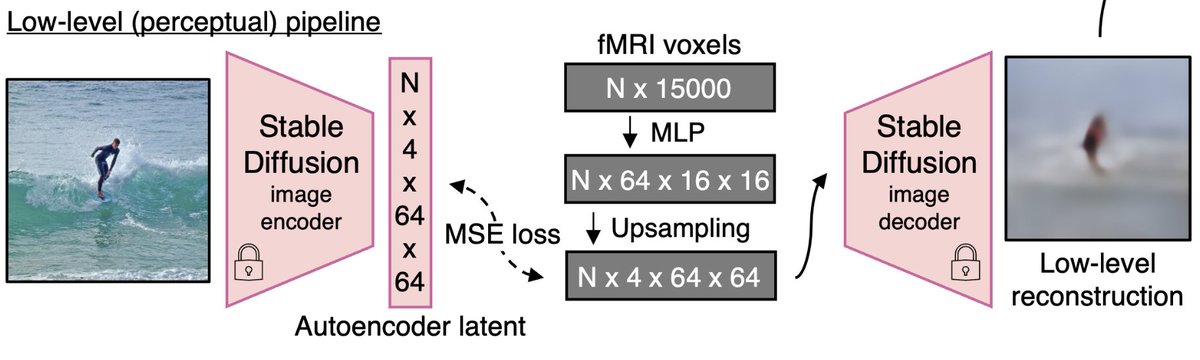
Low-level features are also appropriately reconstructed by mapping the fMRI signals to Stable Diffusion VAE latents and using that as a starting point for img2img.
Using this dual pipeline approach, MindEye obtains SOTA results on both high-level and low-level metrics (table of results in preprint)!
Here is a comparison to previous methods in the literature:
Here is a comparison to previous methods in the literature:

I started this project about a year ago, and it originally started out in @laion_ai.
We were lucky that @humanscotti joined and took the lead on this project, he's done a great job moving this project forward!
Check out his thread on the paper:
We were lucky that @humanscotti joined and took the lead on this project, he's done a great job moving this project forward!
Check out his thread on the paper:
https://twitter.com/humanscotti/status/1663356107966824451
This project was openly developed via volunteer contributions in the @MedARC_AI Discord server and GitHub.
Open-source/decentralized research initiatives have been successful in AI (@AiEleuther, @laion_ai, @openbioml, @ml_collective) & our project further demonstrates that!
Open-source/decentralized research initiatives have been successful in AI (@AiEleuther, @laion_ai, @openbioml, @ml_collective) & our project further demonstrates that!
This isn't the end of our mind reading projects, we have lots of interesting ideas to explore in this space!
If you are interested in contributing, check out:
Discord server: discord.com/invite/CqsMthn…
More info about our mind reading projects: medarc-ai.github.io/mind-reading
If you are interested in contributing, check out:
Discord server: discord.com/invite/CqsMthn…
More info about our mind reading projects: medarc-ai.github.io/mind-reading
• • •
Missing some Tweet in this thread? You can try to
force a refresh