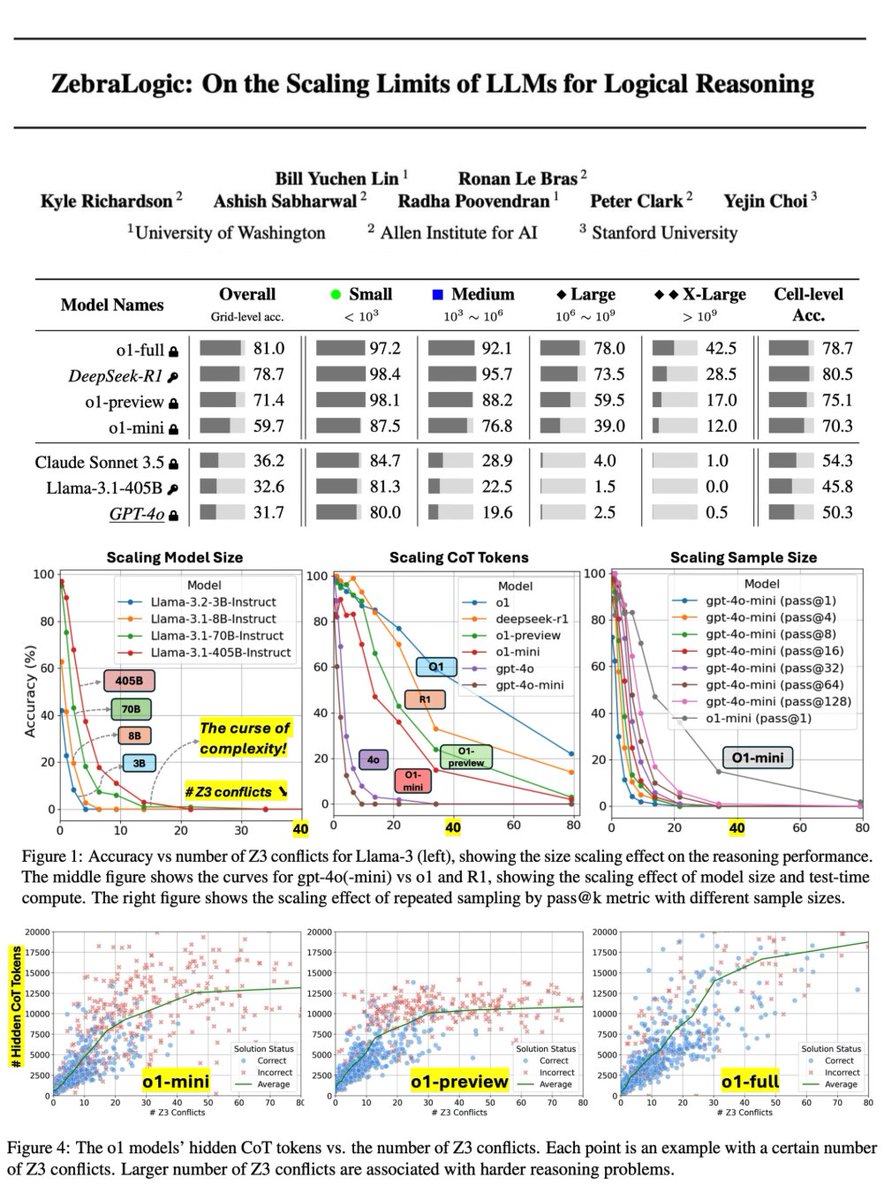
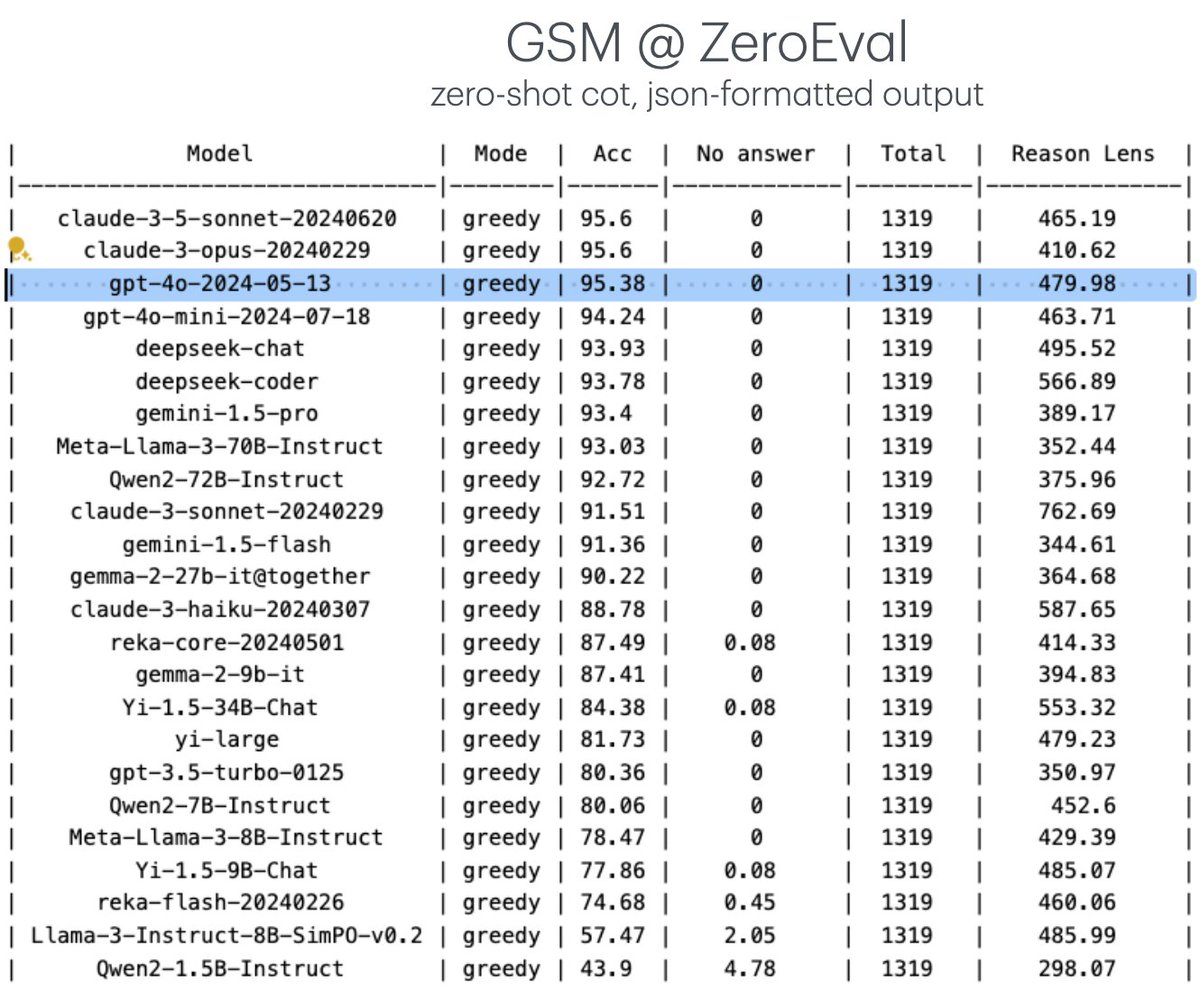
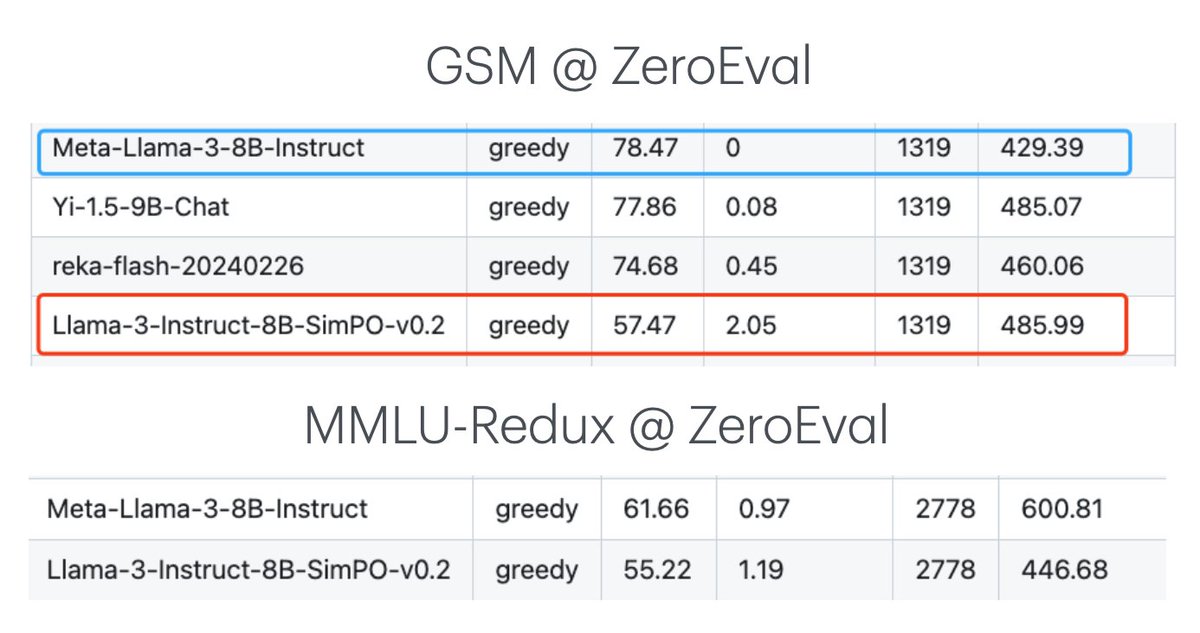
How should we maximize the planning ability of #LLM while reducing the computation cost? 🚀 Introducing SwiftSage, an agent inspired by “fast & slow thinking”, which solves complex interactive tasks much better than prior agents (e.g., DRRN, SayCan, ReAct, and Reflexion). [1/n] 

💡 Let’s compare SwiftSage w/ prior agents: SayCan reranks actions w/ affordance; ReAct has subgoal planning; Reflexion adds self-reflection. However, these methods can be expensive and yet brittle. It’s also hard to execute & ground their error-prone actions/plans in env. [2/n]

🌠 A closer look at the 2 parts of SwfitSage: The Swift is a small LM (770m) for fast thinking. It’s super familiar with target env by imitation learning. The Sage prompts LLMs for slow thinking in two stages: plan & ground, and get an action buffer for interacting w/ env. [3/n]



✨ SwiftSage’s features: 1⃣️ Use imitation learning to train a small LM for fast thinking. 2⃣️ Only prompt LLMs when needed (e.g., no reward after 5 steps). 3⃣️ Separate planning and grounding subgoals when prompting LLMs. 4⃣️ Get multiple actions (~5) per LLM call.[4/n]

🏆 We use ScienceWorld for evaluation. It’s a text-based engine, has 30 types of tasks, 10 locations, 200+ objects, and 25 actions. The tasks can be super complex and long-horizon. It also requires exception handling. SwiftSage is 2x better and costs much less than others! [5/n]




🔥SwiftSage implies the paradigm of small+large LMs is super promising for complex tasks! Work done w/ @allen_ai & @nlp_usc folks: @YejinChoinka @xiangrenNLP @chandra_bhagav @rajammanabrolu @faeze_brh et al.
🔗 Website: yuchenlin.xyz/swiftsage/
🔗 Paper: arxiv.org/abs/2305.17390
🔗 Website: yuchenlin.xyz/swiftsage/
🔗 Paper: arxiv.org/abs/2305.17390
• • •
Missing some Tweet in this thread? You can try to
force a refresh