
RL for coding @xAI @SpaceX Affiliate Assistant Prof @UW. Ex: @allen_ai; Google, Meta FAIR.
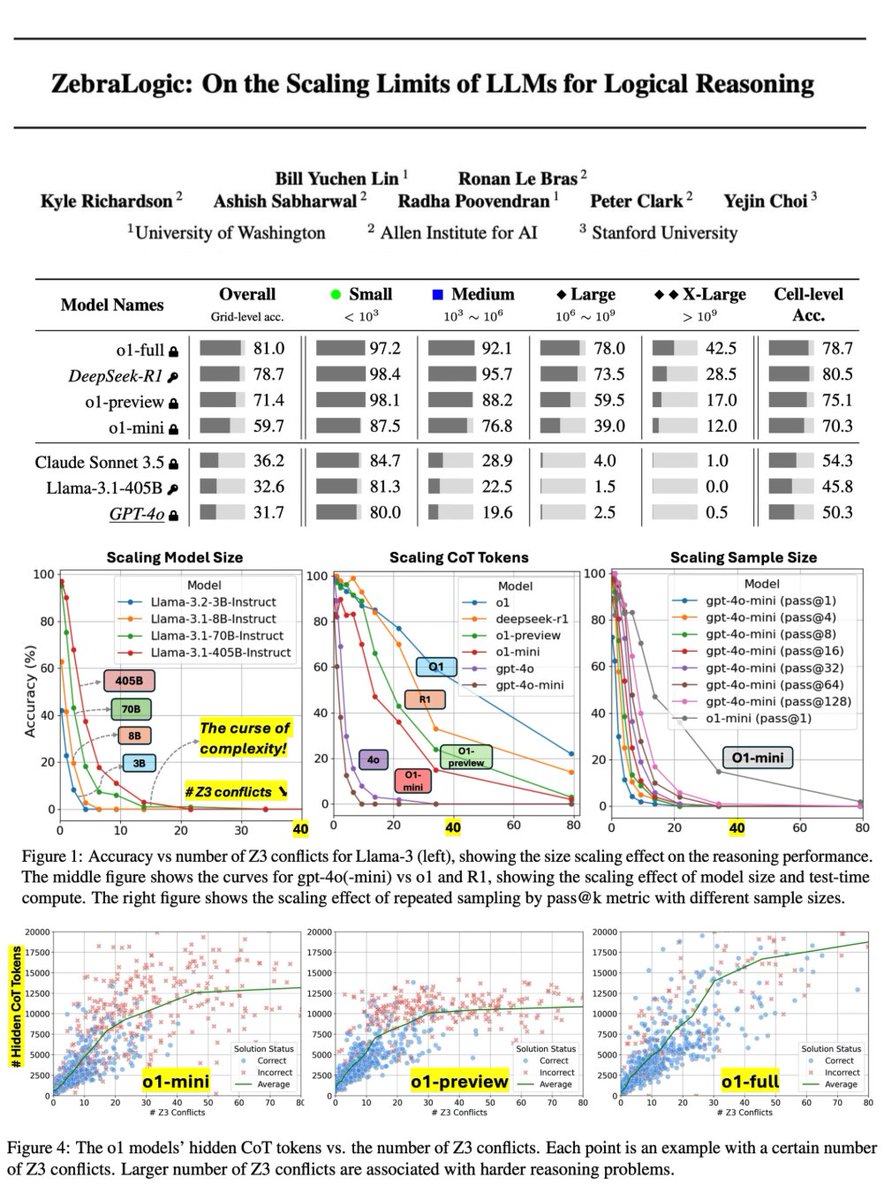 Each ZebraLogic example is a logic grid puzzle with a background scenario and a set of clues that define constraints for assigning values to N houses across M attributes. A reasoning model is tasked with producing a final solution table, correctly filling in all value assignments. Smaller grids or straightforward clues make the problem easier, but complexity grows rapidly with larger grids or trickier clue structures.
Each ZebraLogic example is a logic grid puzzle with a background scenario and a set of clues that define constraints for assigning values to N houses across M attributes. A reasoning model is tasked with producing a final solution table, correctly filling in all value assignments. Smaller grids or straightforward clues make the problem easier, but complexity grows rapidly with larger grids or trickier clue structures. 

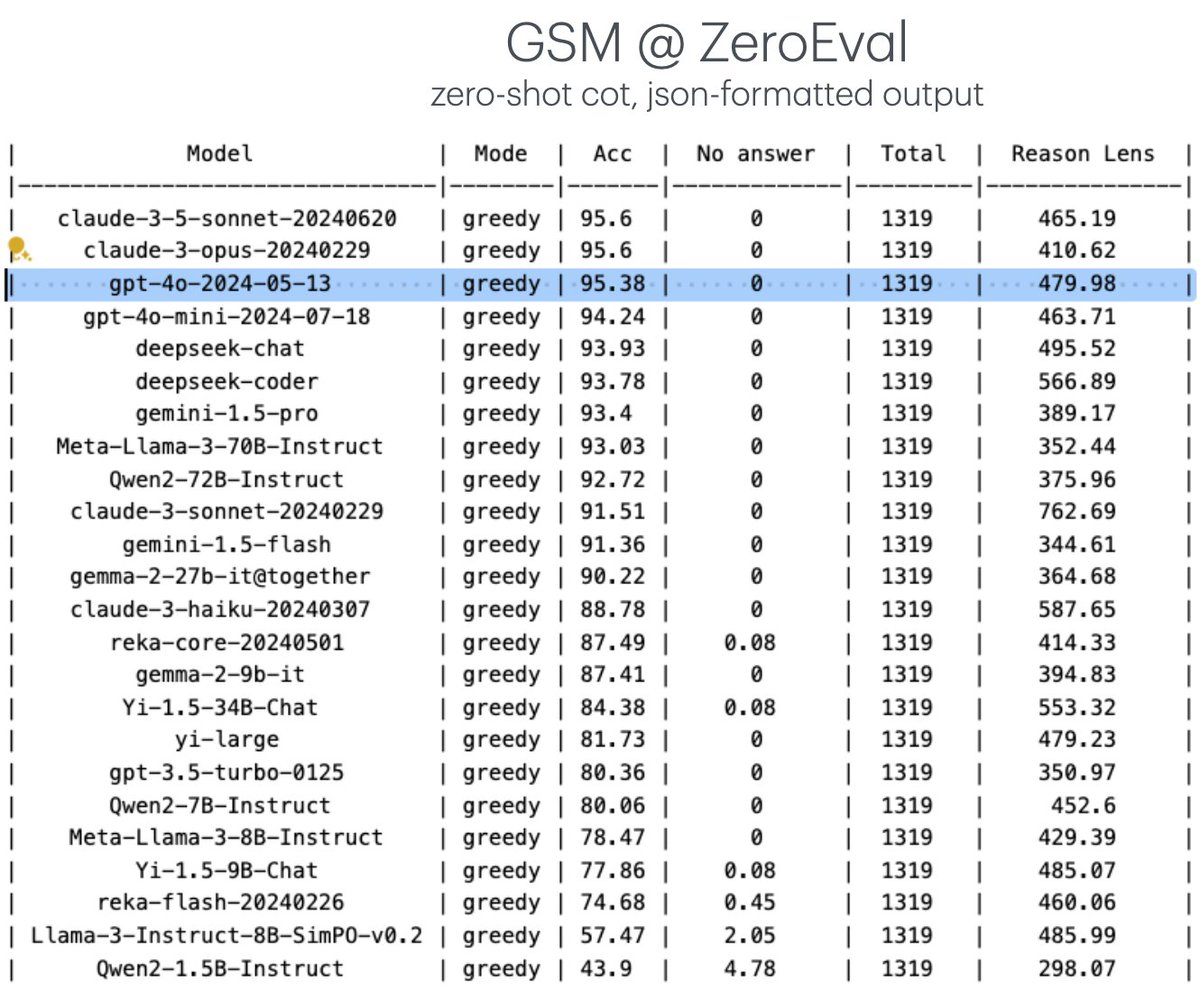 In ZeroEval, we perform zero-shot prompting, and instruct LM to output both reasoning and answer in a json-formatted output. We are actively adding new tasks. Contributions are welcome! [2/n]
In ZeroEval, we perform zero-shot prompting, and instruct LM to output both reasoning and answer in a json-formatted output. We are actively adding new tasks. Contributions are welcome! [2/n] 
 💡 Let’s compare SwiftSage w/ prior agents: SayCan reranks actions w/ affordance; ReAct has subgoal planning; Reflexion adds self-reflection. However, these methods can be expensive and yet brittle. It’s also hard to execute & ground their error-prone actions/plans in env. [2/n]
💡 Let’s compare SwiftSage w/ prior agents: SayCan reranks actions w/ affordance; ReAct has subgoal planning; Reflexion adds self-reflection. However, these methods can be expensive and yet brittle. It’s also hard to execute & ground their error-prone actions/plans in env. [2/n] 
 The FedNLP platform supports various task formulations (e.g., classification, seq tagging, reading comprehension, seq2seq, etc.) for realistic NLP applications. We implement many non-IID partitioning strategies (wrt. label, quantity, feature) that are common for FL. [2/4]
The FedNLP platform supports various task formulations (e.g., classification, seq tagging, reading comprehension, seq2seq, etc.) for realistic NLP applications. We implement many non-IID partitioning strategies (wrt. label, quantity, feature) that are common for FL. [2/4] 
