📢Introducing 🔥#CodeTF🔥, a one-stop Transformer Library for Code Large Language Models (CodeLLM), with a unified interface for training & inference on code tasks (code generation,summarization,translation,etc)
Paper: arxiv.org/abs/2306.00029
Code: github.com/salesforce/Cod…
(1/n)
Paper: arxiv.org/abs/2306.00029
Code: github.com/salesforce/Cod…
(1/n)
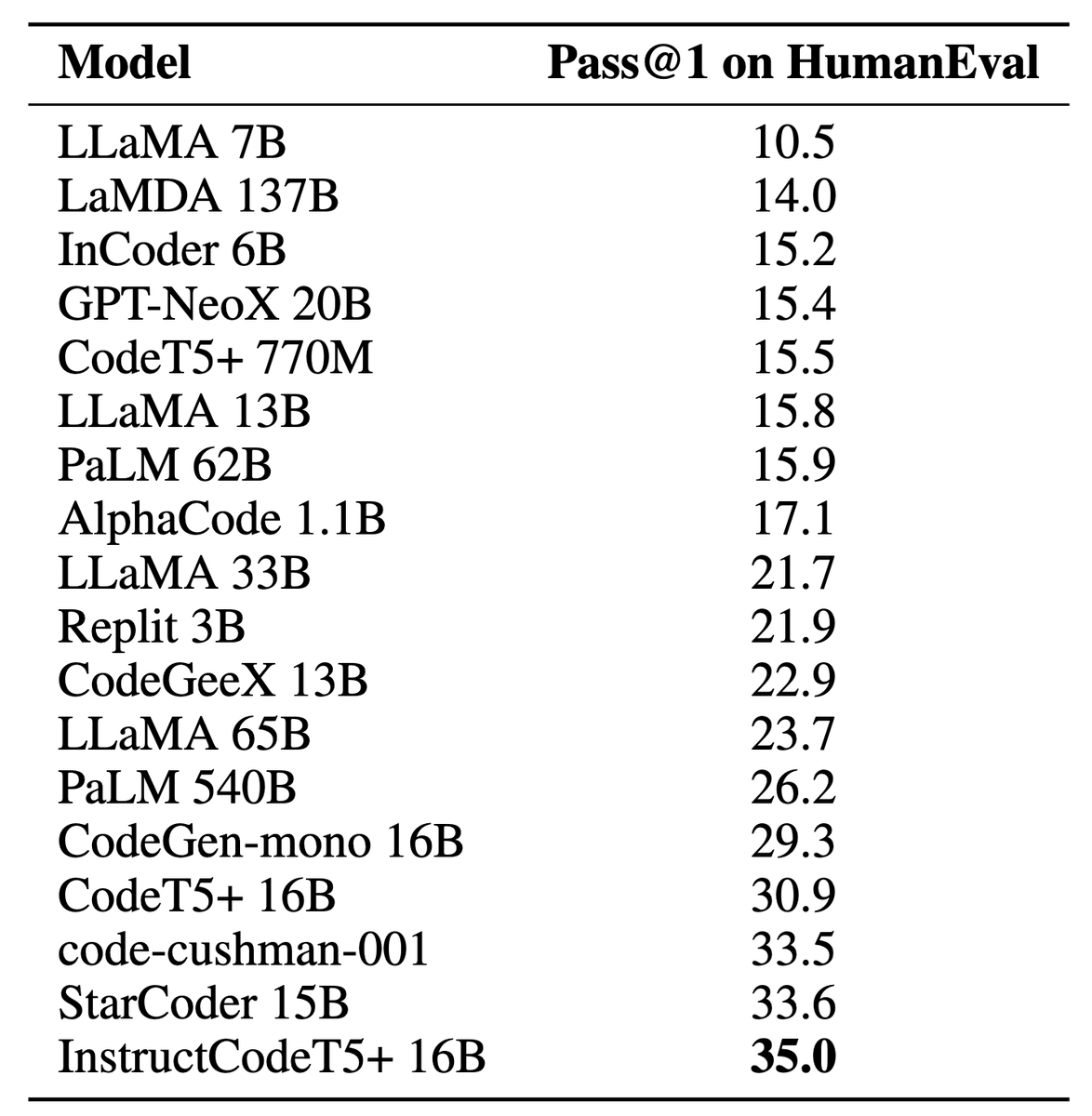
CodeTF library supports both the development and deployment of Code LLMs for code intelligence tasks. The library can support both training and serving code LLM models, code utilities to process code data, and popular research benchmarks to evaluate the model performance.
(2/n)
(2/n)

CodeTF is designed with key principles to provide a user-friendly and easy-to-use platform for code intelligence tasks. It follows a modular architecture, enhancing its extensibility by allowing seamless integration of additional programming languages, models & utilities.
(3/n)
(3/n)

Find out more details from our technical report here:
CodeTF: One-stop Transformer Library for State-of-the-art Code LLM
Another great open-source library with our amazing AI Research team: Nghi, @LHung1610 @ayueei @LiJunnan0409 @AkhileshGotmare at @SFResearch.
(4/n)
CodeTF: One-stop Transformer Library for State-of-the-art Code LLM
Another great open-source library with our amazing AI Research team: Nghi, @LHung1610 @ayueei @LiJunnan0409 @AkhileshGotmare at @SFResearch.
(4/n)
arxiv.org/abs/2306.00029 (5/n)
• • •
Missing some Tweet in this thread? You can try to
force a refresh