
VP@Alibaba
Professor at SMU (on leave). Founder & Ex-CEO@HyperGAI. Ex-MD of Salesforce Research Asia, Ex-VP@Salesforce AI; Ex-AP at NTU; IEEE Fellow.


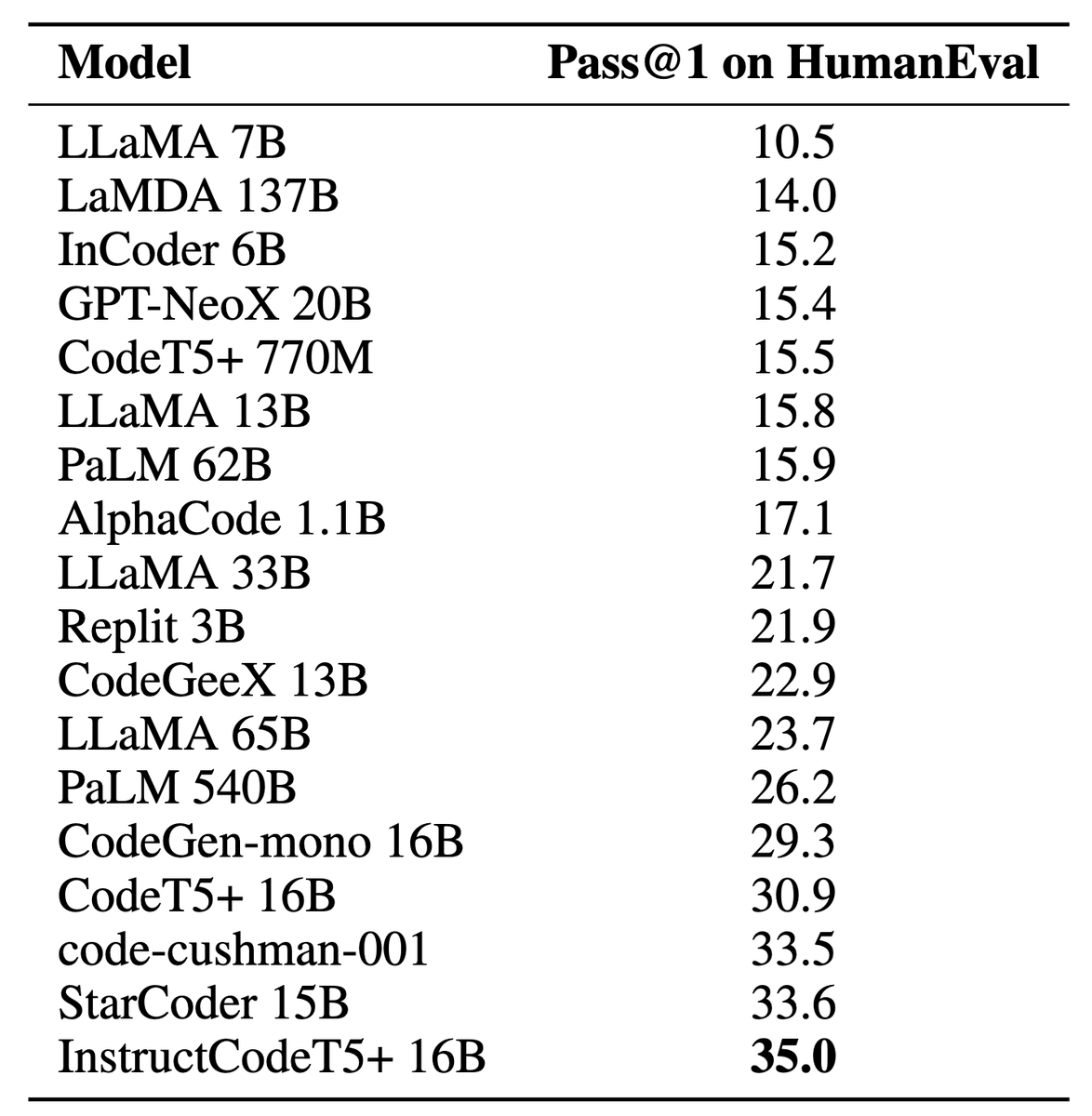 CodeT5+ proposes a flexible model architecture of encoder-decoder with a mixture of varied pretraining tasks, which can flexibly operate in different modes (i.e., encoder-only, decoder-only, and encoder-decoder) for a wide range of code understanding and generation tasks.
CodeT5+ proposes a flexible model architecture of encoder-decoder with a mixture of varied pretraining tasks, which can flexibly operate in different modes (i.e., encoder-only, decoder-only, and encoder-decoder) for a wide range of code understanding and generation tasks. 
