
One of the ideas I find most useful from @AnthropicAI's Core Views on AI Safety post (anthropic.com/index/core-vie…) is thinking in terms of a distribution over safety difficulty.
Here's a cartoon picture I like for thinking about it:
Here's a cartoon picture I like for thinking about it:

A lot of AI safety discourse focuses on very specific models of AI and AI safety. These are interesting, but I don't know how I could be confident in any one.
I prefer to accept that we're just very uncertain. One important axis of that uncertainty is roughly "difficulty".
I prefer to accept that we're just very uncertain. One important axis of that uncertainty is roughly "difficulty".
In this lens, one can see a lot of safety research as "eating marginal probability" of things going well, progressively addressing harder and harder safety scenarios.

To be clear: this uncertainty view doesn't justify reckless behavior with future powerful AI systems! But I value being honest about my uncertainty. I'm very concerned about safety, but I don't want to be an "activist scientist" being maximally pessimistic to drive action.
A concrete "easy scenario": LLMs are just straightforwardly generative models over possible writers, and RLHF just selects within that space. We can then select for brilliant, knowledgeable, kind, thoughtful experts on any topic.
I wouldn't bet on this, but it's possible!
I wouldn't bet on this, but it's possible!
(Tangent: Sometimes people say things like "RLHF/CAI/etc aren't real safety research". My own take would be that this kind of work has probably increased the probability of a good outcome by more than anything else so far. I say this despite focusing on interpretability myself.)
In any case, let's say we accept the overall idea of a distribution over difficulty. I think it's a pretty helpful framework for organizing a safety research portfolio.
We can go through the distribution segment by segment.
We can go through the distribution segment by segment.
In easy scenarios, we basically have the methods we need for safety, and the key issues are things like fairness, economic impact, misuse, and potentially geopolitics. A lot of this is on the policy side, which is outside my expertise.

For intermediate scenarios, pushing further on alignment work – discovering safety methods like Constitutional AI which might work in somewhat harder scenarios – may be the most effective strategy.
Scalable oversight and process-oriented learning seem like promising directions.
Scalable oversight and process-oriented learning seem like promising directions.

For the most pessimistic scenarios, safety isn't realistically solvable in the near term. Unfortunately, the worst situations may *look* very similar to the most optimistic situations.
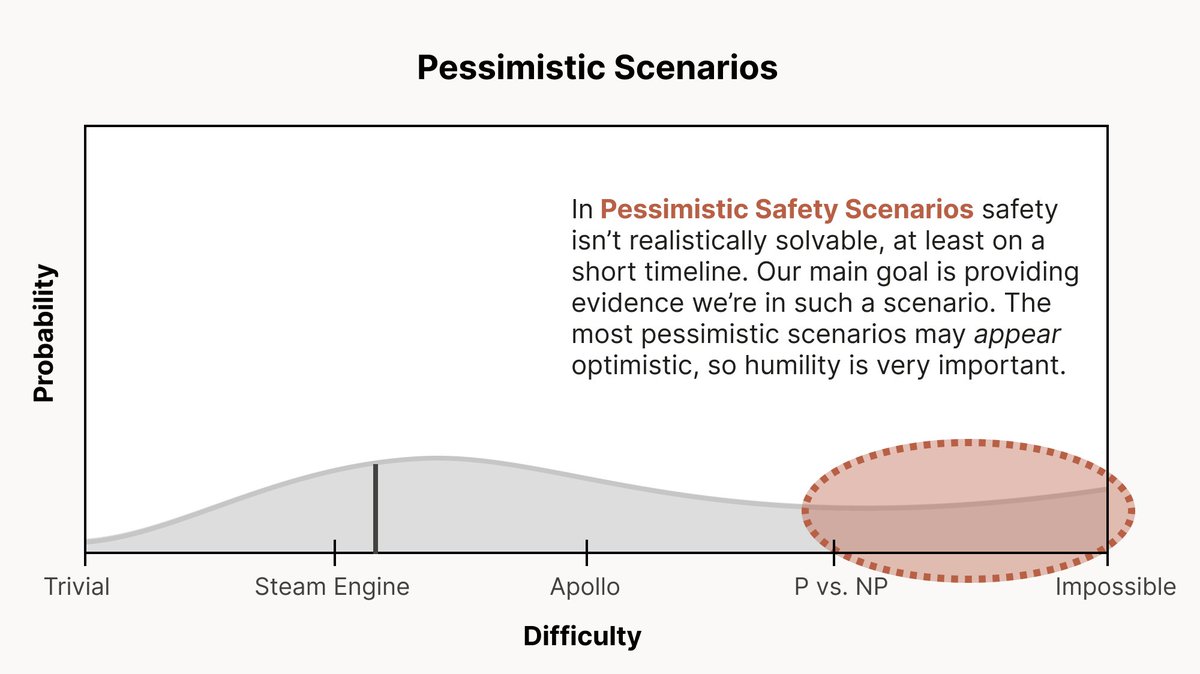
In these scenarios, our goal is to realize and provide strong evidence we're in such a situation (eg. by testing for dangerous failure modes, mechanistic interpretability, understanding generalization, …)
It would be very valuable to reduce uncertainty about the situation.
If we were confidently in an optimistic scenario, priorities would be much simpler.
If we were confidently in a pessimistic scenario (with strong evidence), action would seem much easier.
If we were confidently in an optimistic scenario, priorities would be much simpler.
If we were confidently in a pessimistic scenario (with strong evidence), action would seem much easier.

This thread expresses one way of thinking about all of this…
But the thing I'd really encourage you to ask is what you believe, and where you're uncertain. The discourse often focuses on very specific views, when there are so many dimensions on which one might be uncertain.
But the thing I'd really encourage you to ask is what you believe, and where you're uncertain. The discourse often focuses on very specific views, when there are so many dimensions on which one might be uncertain.

I should mention that there's a lot of other content in the Core Views post that I didn't cover! anthropic.com/index/core-vie…
• • •
Missing some Tweet in this thread? You can try to
force a refresh







