📣 Introducing ⭐ StarCoder+ & StarChat Beta!
We trained StarCoder on the Falcon model's English web dataset and Instruction-tuned it. Both models rank high in the LLM leaderboard, with strong natural language performance and coding capabilities.
huggingface.co/HuggingFaceH4/…
We trained StarCoder on the Falcon model's English web dataset and Instruction-tuned it. Both models rank high in the LLM leaderboard, with strong natural language performance and coding capabilities.
huggingface.co/HuggingFaceH4/…

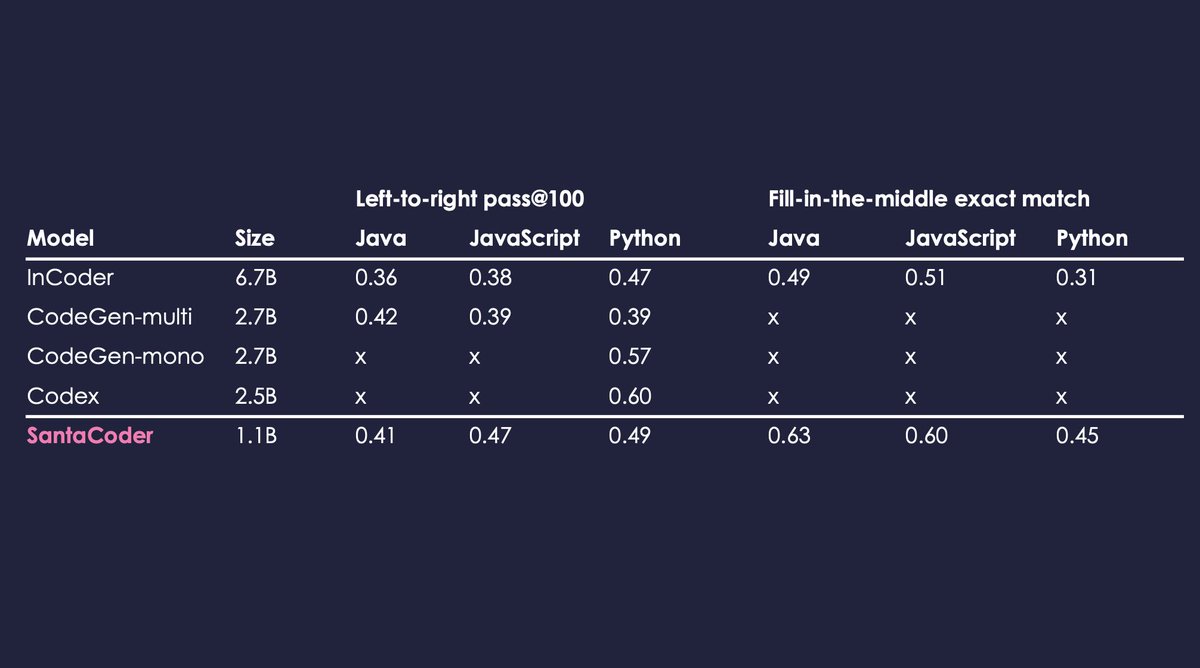
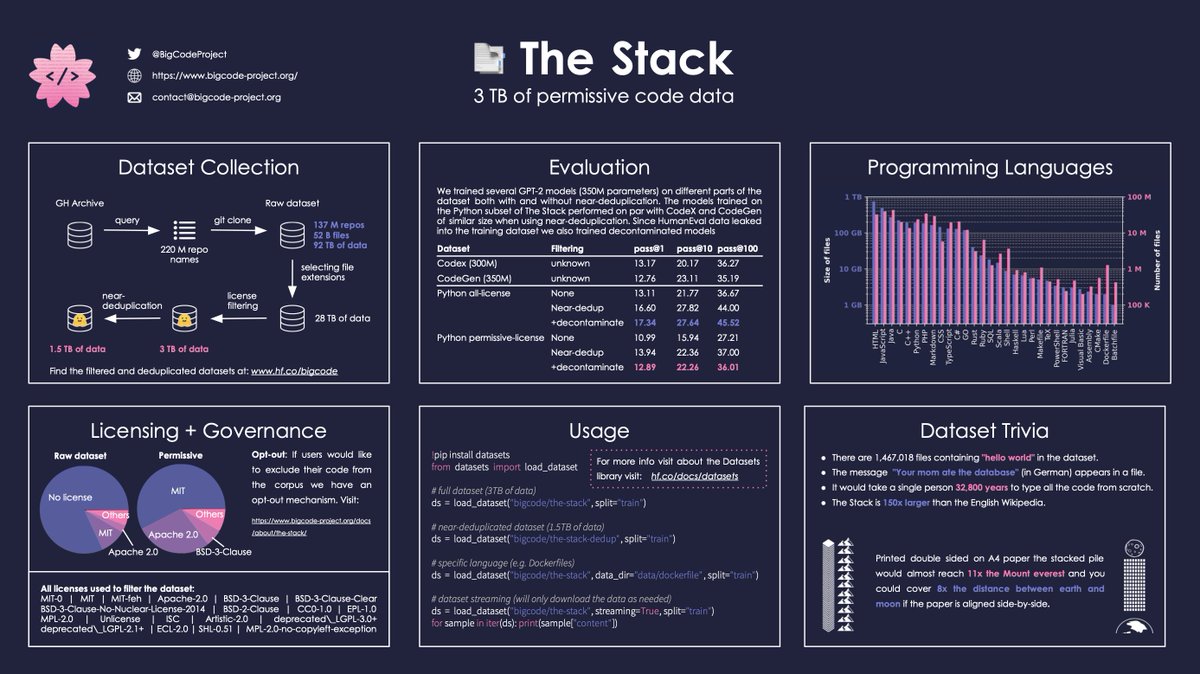
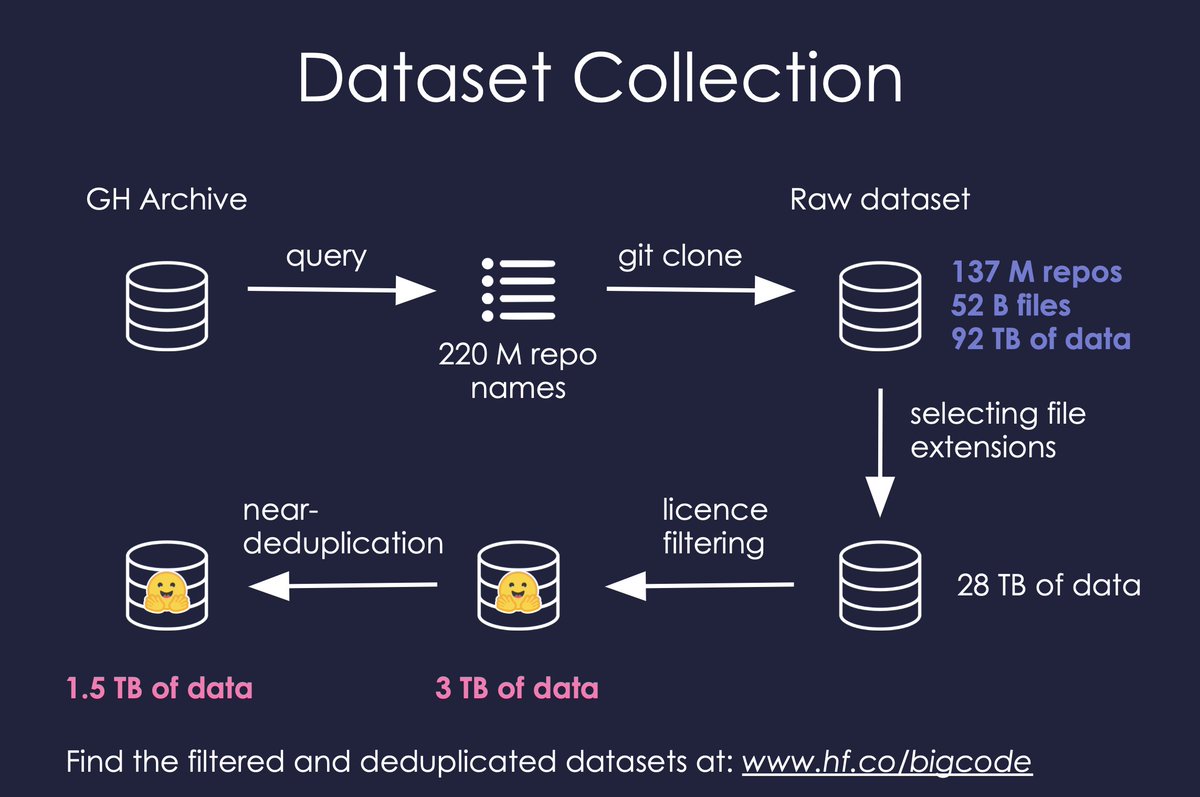
StarCoderBase showed promise in natural language reasoning despite being trained solely on GitHub code. So we fine-tuned it on the English web dataset used in Falcon pre-training:
huggingface.co/bigcode/starco…
huggingface.co/datasets/tiiua…
huggingface.co/bigcode/starco…
huggingface.co/datasets/tiiua…
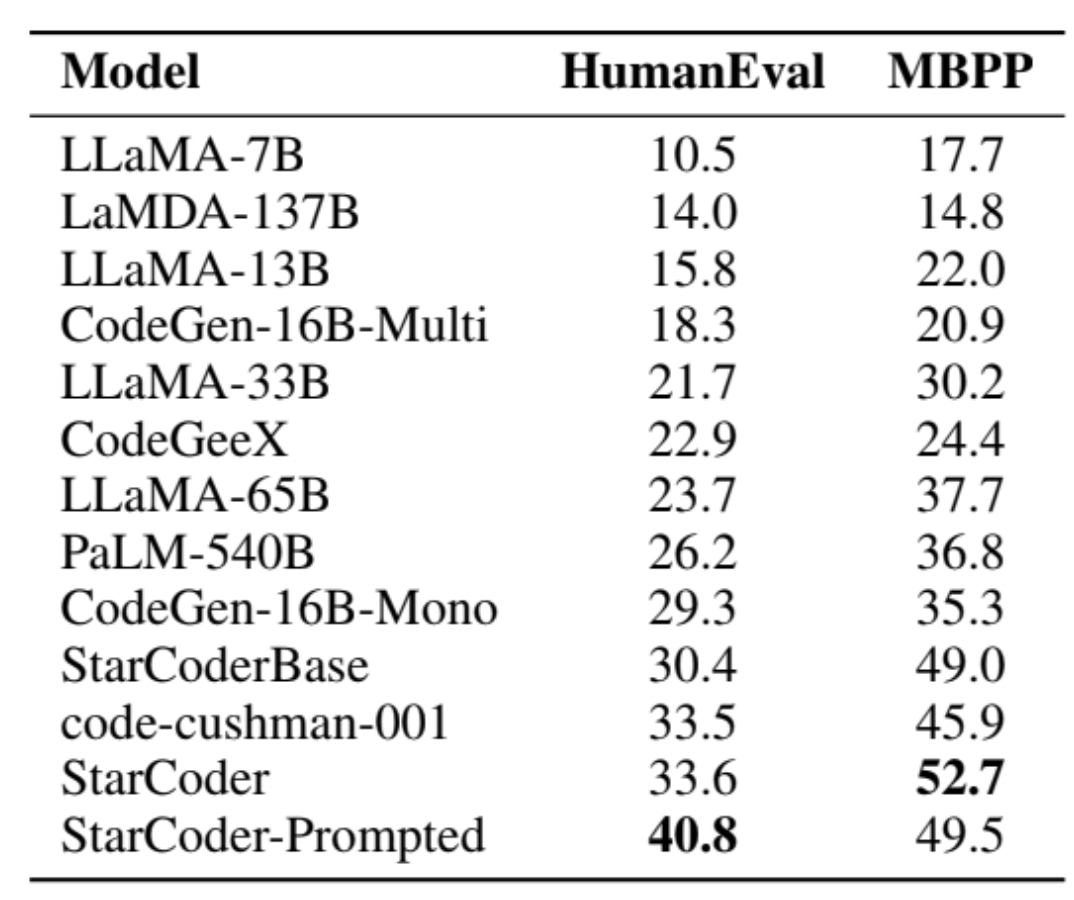
The result: ⭐ StarCoder+ a powerful English Language Model with strong coding abilities.
It outperforms all LLaMa models and PaLM-540B on HumanEval and stands out in the LLM leaderboard for < 30B models with a 45.1 MMLU score!
huggingface.co/spaces/Hugging…
It outperforms all LLaMa models and PaLM-540B on HumanEval and stands out in the LLM leaderboard for < 30B models with a 45.1 MMLU score!
huggingface.co/spaces/Hugging…
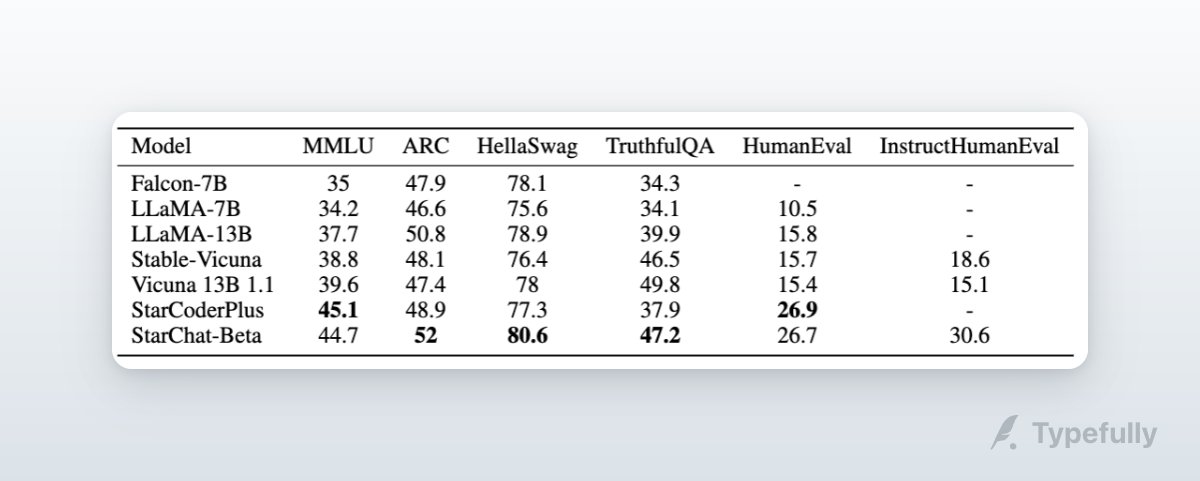
We instruction-tuned StarCoder+ on the OpenAssistant Guanaco dataset to get StarChat-beta: a strong chat assistant
Model: huggingface.co/HuggingFaceH4/…
Demo: huggingface.co/spaces/Hugging…
Model: huggingface.co/HuggingFaceH4/…
Demo: huggingface.co/spaces/Hugging…

It can build HTML websites and much more...
Give it a try 🚀
Give it a try 🚀

📔 Resources:
StarCoderPlus: huggingface.co/bigcode/starco…
StarChat Beta: huggingface.co/HuggingFaceH4/…
StarChat demo: huggingface.co/spaces/Hugging…
StarCoderPlus demo: huggingface.co/spaces/bigcode…
StarCoderPlus: huggingface.co/bigcode/starco…
StarChat Beta: huggingface.co/HuggingFaceH4/…
StarChat demo: huggingface.co/spaces/Hugging…
StarCoderPlus demo: huggingface.co/spaces/bigcode…
Back to the start:
https://twitter.com/BigCodeProject/status/1666856107665666048
• • •
Missing some Tweet in this thread? You can try to
force a refresh