
Open and responsible research and development of large language models for code. #BigCodeProject run by @huggingface + @ServiceNowRSRCH
 Why does this matter?
Why does this matter?
 StarCoderBase showed promise in natural language reasoning despite being trained solely on GitHub code. So we fine-tuned it on the English web dataset used in Falcon pre-training:
StarCoderBase showed promise in natural language reasoning despite being trained solely on GitHub code. So we fine-tuned it on the English web dataset used in Falcon pre-training: In addition to chatting with StarCoder, it can also help you code in the new VSCode plugin. By pressing CTRL+ESC you can also check if the current code was in the pretraining dataset!
In addition to chatting with StarCoder, it can also help you code in the new VSCode plugin. By pressing CTRL+ESC you can also check if the current code was in the pretraining dataset! SantaCoder is trained on Python, Java, and JavaScript and outperforms other large multilingual models such as InCoder (6.7B) or CodeGen-multi (2.7B) considerably!
SantaCoder is trained on Python, Java, and JavaScript and outperforms other large multilingual models such as InCoder (6.7B) or CodeGen-multi (2.7B) considerably!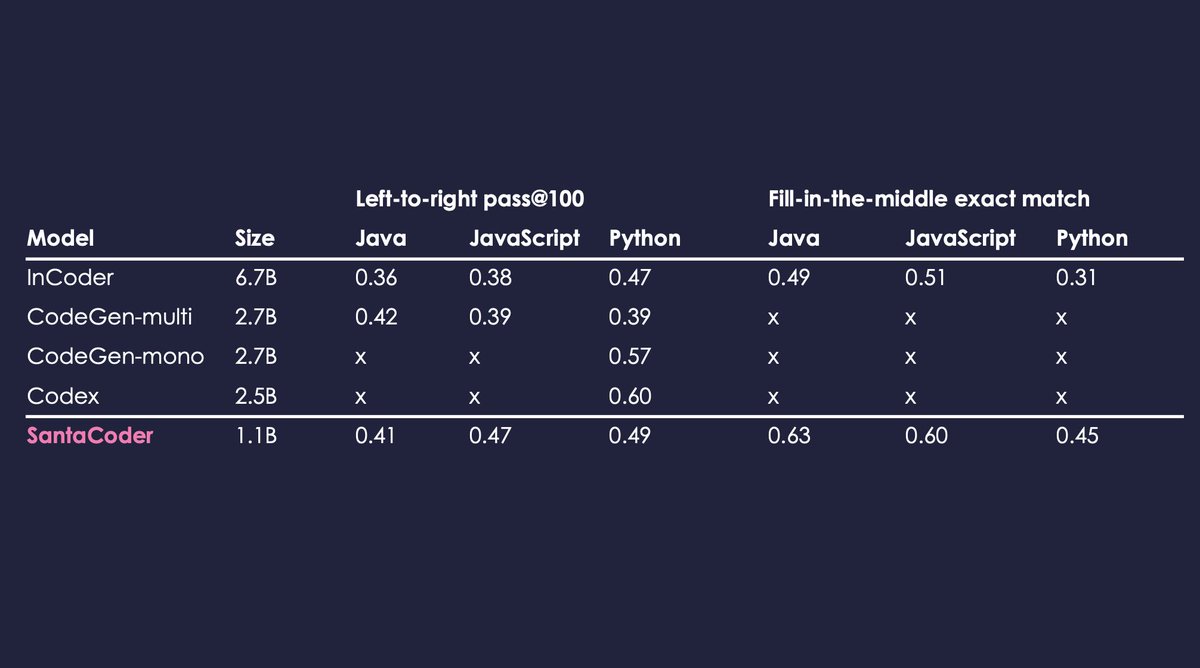
 We are training ~1B parameter models on the Python/Java/JavaScript subset of The Stack. On the architecture side we want to evaluate the Fill-in-the-Middle (FIM) objective, as well as multi-query attention.
We are training ~1B parameter models on the Python/Java/JavaScript subset of The Stack. On the architecture side we want to evaluate the Fill-in-the-Middle (FIM) objective, as well as multi-query attention.
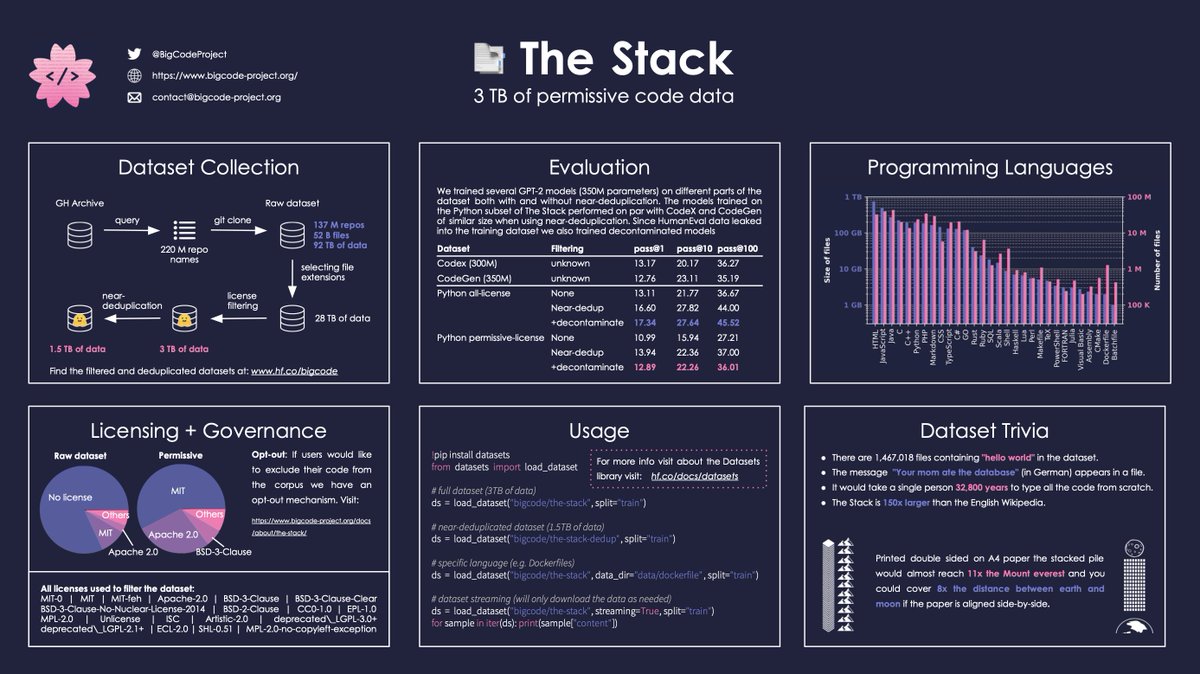 Dataset collection: With gharchive.org over 220M repos were identified and 137M successfully cloned with over 50B files and 90TB of data. Filtered by extension and permissive licenses this yields 3TB of data. We also make a near-deduplicated version (1.5TB) available.
Dataset collection: With gharchive.org over 220M repos were identified and 137M successfully cloned with over 50B files and 90TB of data. Filtered by extension and permissive licenses this yields 3TB of data. We also make a near-deduplicated version (1.5TB) available. 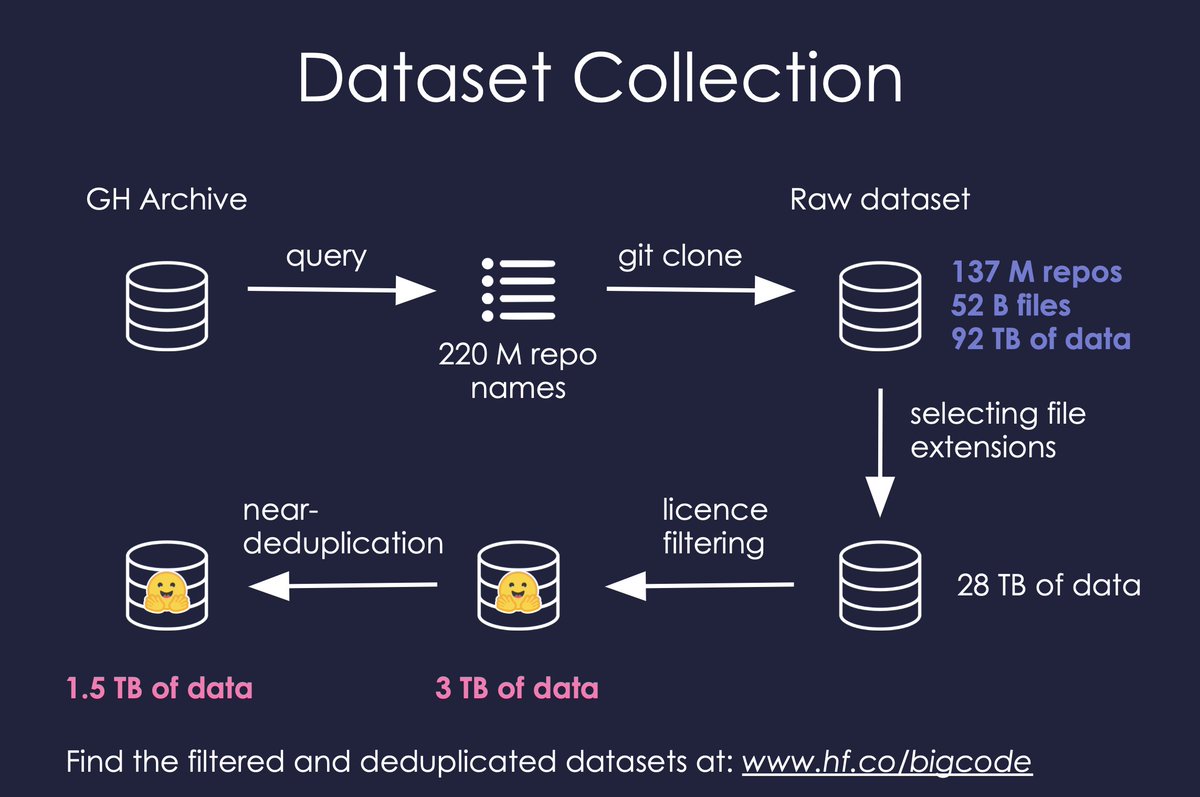
 🌸Language models for code (Codex, CodeGen) and the applications they power (AI assisted programming) are gaining traction. Some models have been released, but there are still questions around data governance, robustness of evaluation benchmarks, and the engineering behind them.
🌸Language models for code (Codex, CodeGen) and the applications they power (AI assisted programming) are gaining traction. Some models have been released, but there are still questions around data governance, robustness of evaluation benchmarks, and the engineering behind them.