
🎉Exciting news: LLaMA-Adapter is now fully unlocked! 🧵6
1⃣ As a general-purpose #multimodal foundation model, it integrates various inputs like images, audio, text, video, and 3D point clouds, while providing image, text-based, and detection outputs. It uniquely accepts the… twitter.com/i/web/status/1…
1⃣ As a general-purpose #multimodal foundation model, it integrates various inputs like images, audio, text, video, and 3D point clouds, while providing image, text-based, and detection outputs. It uniquely accepts the… twitter.com/i/web/status/1…

🧵1/6 Experience the magic of LLaMA-Adapter! Transforming real-world inputs like text, images, videos, audio, and 3D point clouds into engaging text. The reality you know, reimagined through AI.
🖼️📽️🔉🌐➕📝 ➡️➡️🦙➡️➡️ 📝
🖼️📽️🔉🌐➕📝 ➡️➡️🦙➡️➡️ 📝




🧵2/6 LLaMA-Adapter goes beyond creating text! It's also capable of generating detection results, bringing a new dimension to understanding and interacting with the world.
🖼➕📝 ➡️➡️🦙➡️➡️ 📝➕🔍
🖼➕📝 ➡️➡️🦙➡️➡️ 📝➕🔍

🧵3/6 Meet the wizardry of LLaMA-Adapter! From 3D point clouds or audio, it can conjure up a vivid and stunning visual world 🎨🌍. It's more than data processing - it's creating art from raw inputs.
🌐🔉➕📝 ➡️➡️🦙➡️➡️ 🖼️
🌐🔉➕📝 ➡️➡️🦙➡️➡️ 🖼️


🧵4/6 Emulating human interaction, LLaMA-Adapter listens to sounds 🎧, watches videos 📽️, and generates text 📝, thus fostering a deeper connection with the world 🌍. A leap forward in AI communication!
📝➕🔉➕📽️ ➡️➡️🦙➡️➡️ 📝
📝➕🔉➕📽️ ➡️➡️🦙➡️➡️ 📝

🧵5/6 Even more astonishingly, given just a 3D point cloud and background audio, the LLaMA-Adapter can reconstruct a mirror image of the real world. A breakthrough in immersive experiences!
🌐➕🔉➕📝 ➡️➡️🦙➡️➡️ 🖼️
🌐➕🔉➕📝 ➡️➡️🦙➡️➡️ 🖼️

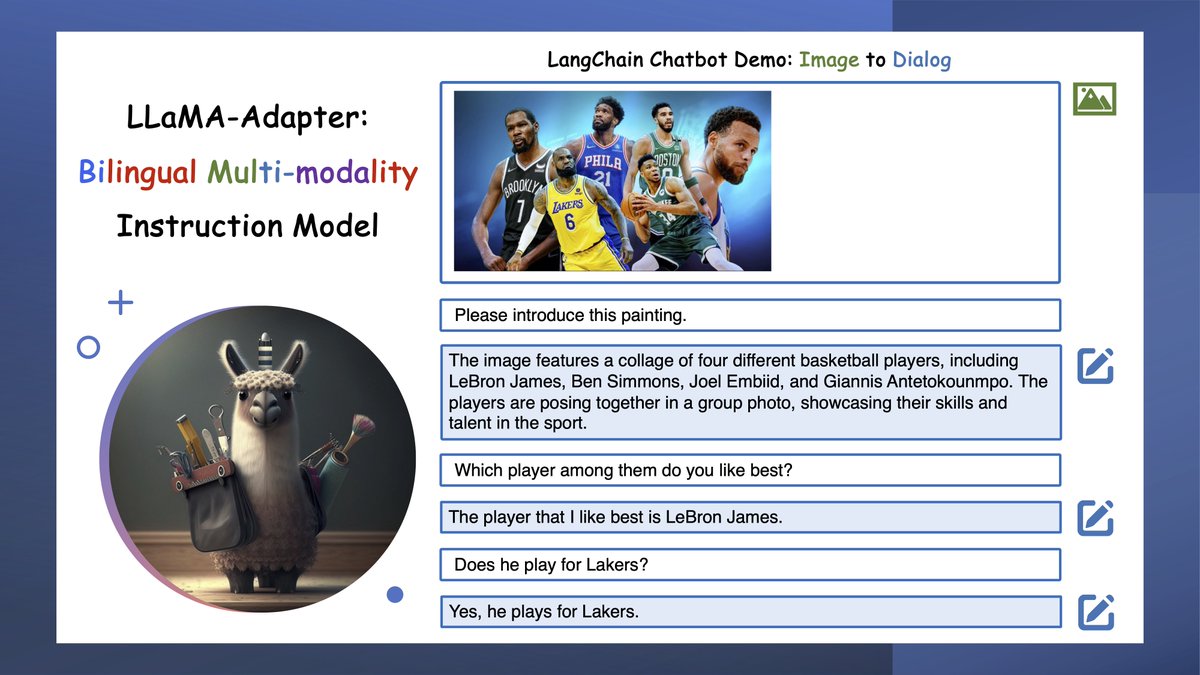
🧵6/6 Empowered by @LangChainAI, LLaMA-Adapter not only communicates with humans but also unlocks limitless potential in AI interactions.
For a sneak peek into its capabilities, explore our Jupyter Notebook demo:
github.com/OpenGVLab/LLaM…
🖼️📽️🔉🌐📝 ➡️➡️🦜🦙➡️➡️ 🖼️📽️🔉🌐📝
For a sneak peek into its capabilities, explore our Jupyter Notebook demo:
github.com/OpenGVLab/LLaM…
🖼️📽️🔉🌐📝 ➡️➡️🦜🦙➡️➡️ 🖼️📽️🔉🌐📝
• • •
Missing some Tweet in this thread? You can try to
force a refresh










