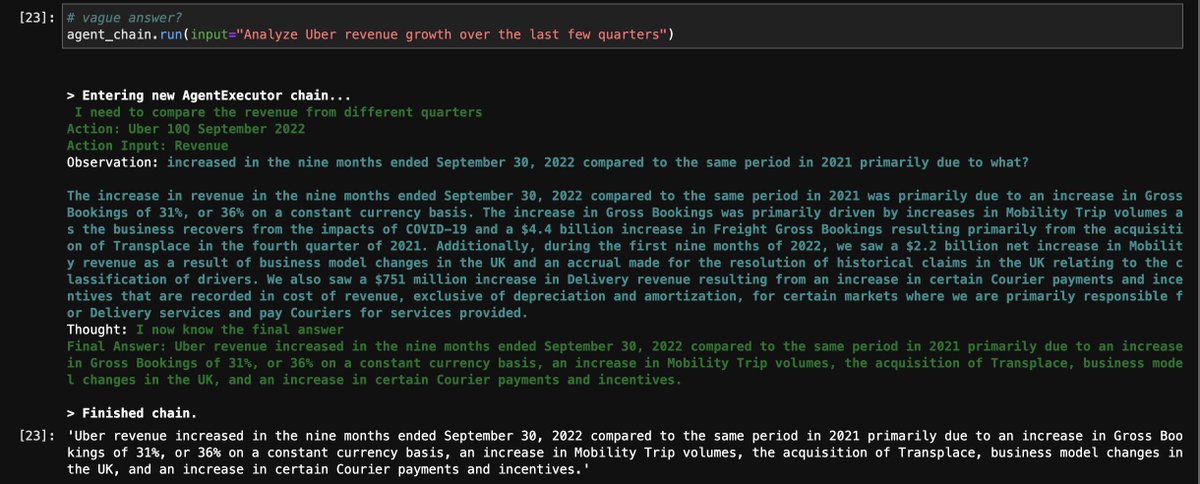
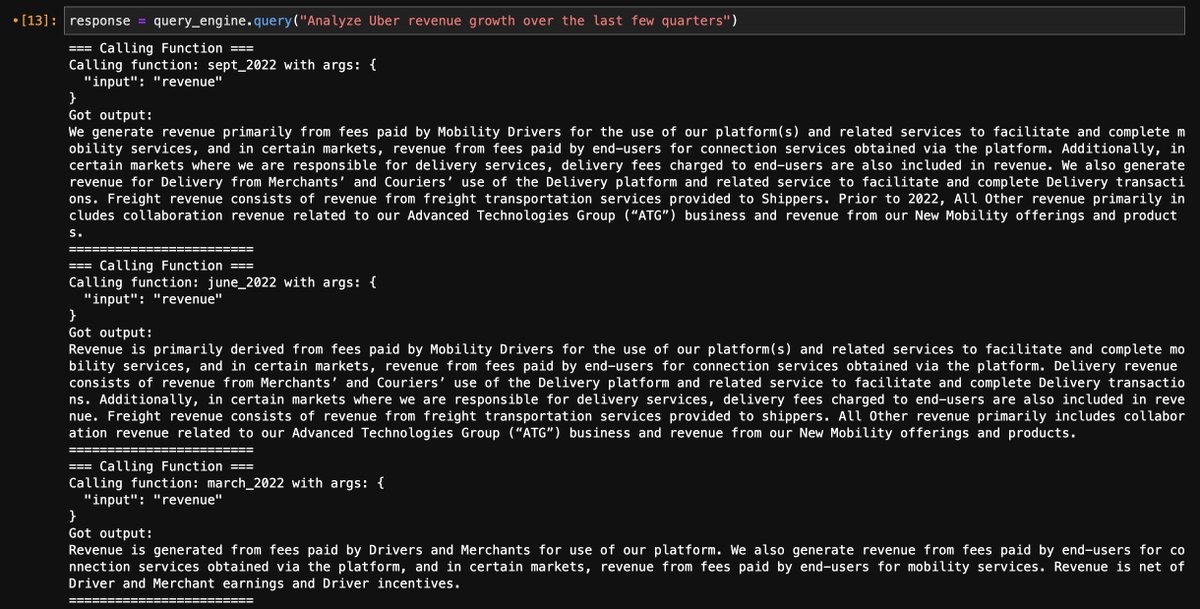
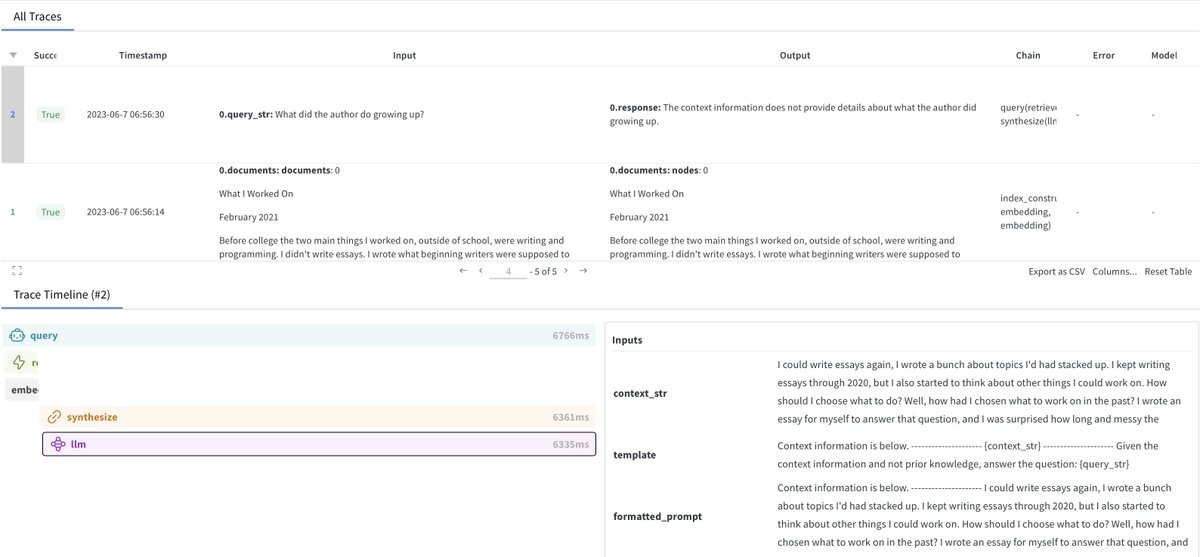
The new OpenAI Function API simplifies agent development by A LOT.
Our latest @llama_index release 🔥shows this:
- Build-an-agent tutorial in ~50 lines of code! ⚡️
- In-house agent on our query tools
Replace ReAct with a simple for-loop 💡👇
github.com/jerryjliu/llam…
Our latest @llama_index release 🔥shows this:
- Build-an-agent tutorial in ~50 lines of code! ⚡️
- In-house agent on our query tools
Replace ReAct with a simple for-loop 💡👇
github.com/jerryjliu/llam…
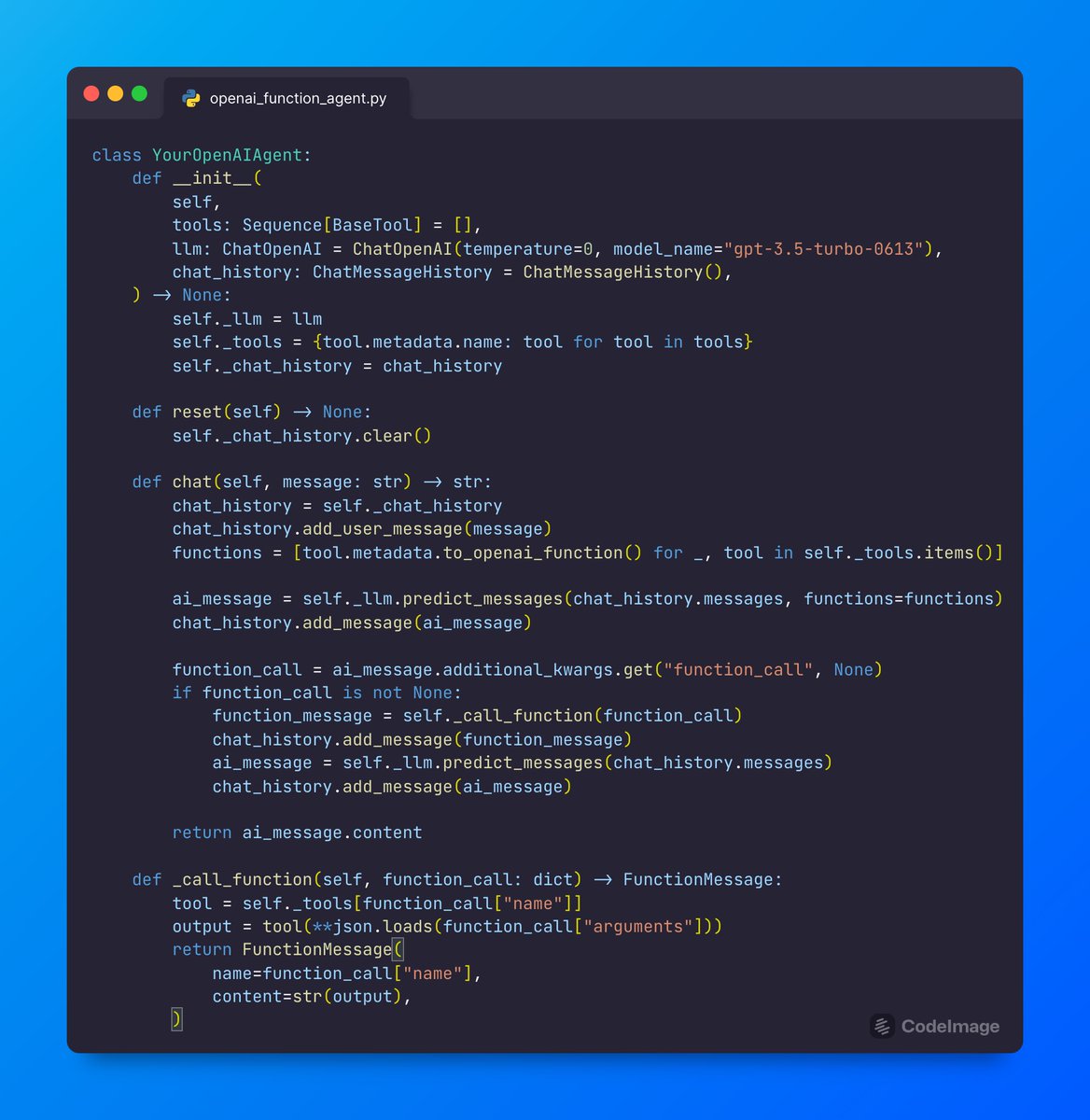
The OpenAI Function API lets the LLM natively take in message history as input to choose functions 🛠️.
Best of all, it can decide whether to keep picking functions, or output a user message.
It can do this all within the API call, w/o explicit prompting 📝
Best of all, it can decide whether to keep picking functions, or output a user message.
It can do this all within the API call, w/o explicit prompting 📝
This is HUGE for a few reasons:
- No more prompt hacking for structured outputs
- No extra API calls/tokens to choose Tools
Also…if the API itself can decide whether to keep going, then…there’s no more need to complex ReAct loops? 🤔❓ (to be determined!)
- No more prompt hacking for structured outputs
- No extra API calls/tokens to choose Tools
Also…if the API itself can decide whether to keep going, then…there’s no more need to complex ReAct loops? 🤔❓ (to be determined!)
We’ve landed some HUGE feature changes and tutorials highlighting the power of this function calling API:
Tutorial showing how you can build an agent in 50 lines of code: github.com/jerryjliu/llam…
Tutorial showing agent on top of our query tools: github.com/jerryjliu/llam…
Tutorial showing how you can build an agent in 50 lines of code: github.com/jerryjliu/llam…
Tutorial showing agent on top of our query tools: github.com/jerryjliu/llam…
We now have a (slightly more sophisticated) in-house `OpenAIAgent` implementation🔥:
- More seamless integrations with LlamaIndex chat engine/query engine
- Supports multiple/sequential function calls
- Async endpoints
- Callbacks/tracing
- More seamless integrations with LlamaIndex chat engine/query engine
- Supports multiple/sequential function calls
- Async endpoints
- Callbacks/tracing

We used @LangChainAI for the latest LLM abstraction (big s/o for the speed), and some initial memory modules.
The big takeaway here is that it’s easier than ever to build your own agent loop.
Can unlock a LOT of value on the query tools that LlamaIndex provides 🦙
The big takeaway here is that it’s easier than ever to build your own agent loop.
Can unlock a LOT of value on the query tools that LlamaIndex provides 🦙
• • •
Missing some Tweet in this thread? You can try to
force a refresh