real life Simpsons, midjourney AI
1. Flanders
1. Flanders

2. Homer

3. Bart

4. Patty & Selma

5. Carl

6. Apu

7. Groundskeeper Willy

8. Smithers

9. Ms. Krabappel

10. Marge
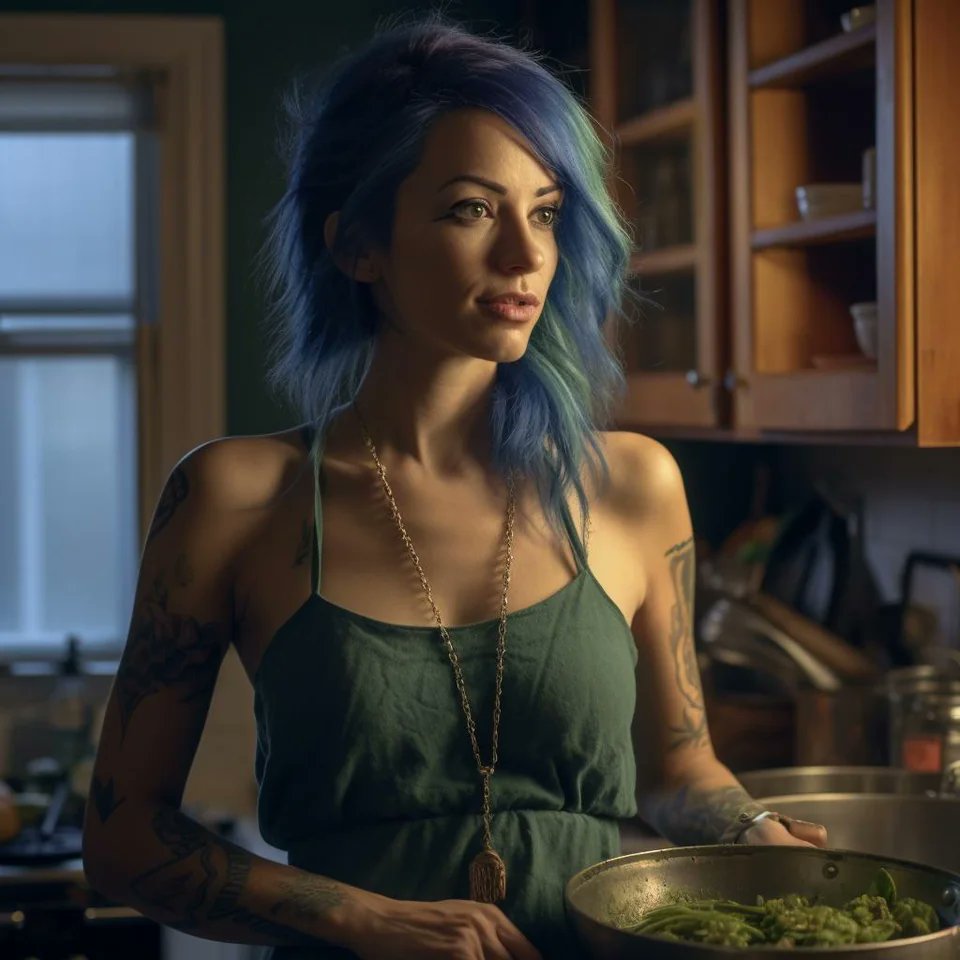
reddit thread: reddit.com/r/midjourney/c…
• • •
Missing some Tweet in this thread? You can try to
force a refresh