 now available in ai-gradio
now available in ai-gradio context without exceeding the token budget of commonly used LLMs. This is realized by using a two-stream SlowFast design of inputs for Video LLMs to aggregate features from sampled video frames in an effective way. Specifically, the Slow pathway extracts features
context without exceeding the token budget of commonly used LLMs. This is realized by using a two-stream SlowFast design of inputs for Video LLMs to aggregate features from sampled video frames in an effective way. Specifically, the Slow pathway extracts features
 language models alongside textual tokens. However, when dealing with long sequences of visual signals or inputs such as videos, the self-attention mechanism of language models can lead to significant computational overhead. Additionally, using single-layer ViT features
language models alongside textual tokens. However, when dealing with long sequences of visual signals or inputs such as videos, the self-attention mechanism of language models can lead to significant computational overhead. Additionally, using single-layer ViT features
 architecture in terms of language acceptance. We contend that this is an ill-suited problem in the study of language models (LMs), which are definitionally probability distributions over strings. In this paper, we focus on the relationship between transformer LMs and n-gram
architecture in terms of language acceptance. We contend that this is an ill-suited problem in the study of language models (LMs), which are definitionally probability distributions over strings. In this paper, we focus on the relationship between transformer LMs and n-gram
 In this work, we argue that one of the primary vulnerabilities underlying these attacks is that LLMs often consider system prompts (e.g., text from an application developer) to be the same priority as text from untrusted users and third parties. To address this, we propose an
In this work, we argue that one of the primary vulnerabilities underlying these attacks is that LLMs often consider system prompts (e.g., text from an application developer) to be the same priority as text from untrusted users and third parties. To address this, we propose an
 unpredictable tasks demanded by users. This paper introduces a novel approach, FlowMind, leveraging the capabilities of Large Language Models (LLMs) such as Generative Pretrained Transformer (GPT), to address this limitation and create an automatic workflow generation
unpredictable tasks demanded by users. This paper introduces a novel approach, FlowMind, leveraging the capabilities of Large Language Models (LLMs) such as Generative Pretrained Transformer (GPT), to address this limitation and create an automatic workflow generation
 state space models exist, they empirically underperform Transformers in pretraining efficiency and downstream task accuracy. We introduce Megalodon, a neural architecture for efficient sequence modeling with unlimited context length. Megalodon inherits the architecture of Mega
state space models exist, they empirically underperform Transformers in pretraining efficiency and downstream task accuracy. We introduce Megalodon, a neural architecture for efficient sequence modeling with unlimited context length. Megalodon inherits the architecture of Mega
 without any additional training or gradient updates. Our findings reveal that several large language models (e.g., GPT-4, Claude 3) are able to perform regression tasks with a performance rivaling (or even outperforming) that of traditional supervised methods such as
without any additional training or gradient updates. Our findings reveal that several large language models (e.g., GPT-4, Claude 3) are able to perform regression tasks with a performance rivaling (or even outperforming) that of traditional supervised methods such as
 user interface (UI) screens. In this paper, we present Ferret-UI, a new MLLM tailored for enhanced understanding of mobile UI screens, equipped with referring, grounding, and reasoning capabilities. Given that UI screens typically exhibit a more elongated aspect ratio
user interface (UI) screens. In this paper, we present Ferret-UI, a new MLLM tailored for enhanced understanding of mobile UI screens, equipped with referring, grounding, and reasoning capabilities. Given that UI screens typically exhibit a more elongated aspect ratio
 Diffusion for image generation. However, it is unclear how meaningful the notion of "zero-shot" generalization is for such multimodal models, as it is not known to what extent their pretraining datasets encompass the downstream concepts targeted for during "zero-shot"
Diffusion for image generation. However, it is unclear how meaningful the notion of "zero-shot" generalization is for such multimodal models, as it is not known to what extent their pretraining datasets encompass the downstream concepts targeted for during "zero-shot"
 FLOPs (or compute) to specific positions in a sequence, optimising the allocation along the sequence for different layers across the model depth. Our method enforces a total compute budget by capping the number of tokens (k) that can participate in the self-attention and
FLOPs (or compute) to specific positions in a sequence, optimising the allocation along the sequence for different layers across the model depth. Our method enforces a total compute budget by capping the number of tokens (k) that can participate in the self-attention and
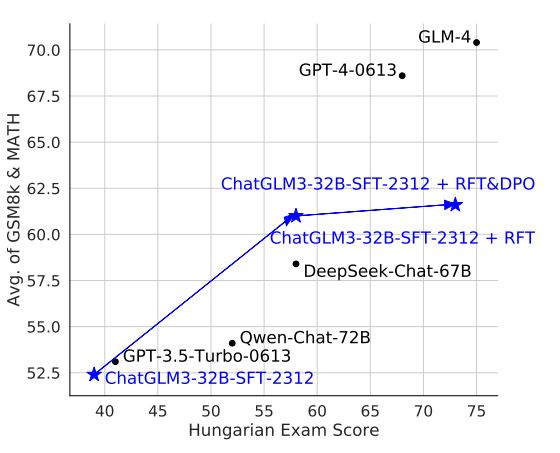 strategies and datasets to enhance LLMs' mathematics are developed, it remains a challenge to simultaneously maintain and improve both language and mathematical capabilities in deployed LLM systems. In this work, we tailor the Self-Critique pipeline, which addresses the
strategies and datasets to enhance LLMs' mathematics are developed, it remains a challenge to simultaneously maintain and improve both language and mathematical capabilities in deployed LLM systems. In this work, we tailor the Self-Critique pipeline, which addresses the
 in tasks involving video instruction-following, providing informative feedback, especially for detecting hallucinations in generated responses, remains a significant challenge. Previous studies have explored using large large multimodal models (LMMs) as reward models to
in tasks involving video instruction-following, providing informative feedback, especially for detecting hallucinations in generated responses, remains a significant challenge. Previous studies have explored using large large multimodal models (LMMs) as reward models to
 components, gradients of memorized paragraphs have a distinguishable spatial pattern, being larger in lower model layers than gradients of non-memorized examples. Moreover, the memorized examples can be unlearned by fine-tuning only the high-gradient weights. We localize a
components, gradients of memorized paragraphs have a distinguishable spatial pattern, being larger in lower model layers than gradients of non-memorized examples. Moreover, the memorized examples can be unlearned by fine-tuning only the high-gradient weights. We localize a
 exhibits quadratic time and space in input size, limiting their scalability for long-sequence modeling. Despite recent attempts to design efficient and effective architecture backbone for multi-dimensional data, such as images and multivariate time series, existing models are
exhibits quadratic time and space in input size, limiting their scalability for long-sequence modeling. Despite recent attempts to design efficient and effective architecture backbone for multi-dimensional data, such as images and multivariate time series, existing models are
 Visual Document Understanding are equipped with text recognition ability but lack general structure understanding abilities for text-rich document images. In this work, we emphasize the importance of structure information in Visual Document Understanding and propose the
Visual Document Understanding are equipped with text recognition ability but lack general structure understanding abilities for text-rich document images. In this work, we emphasize the importance of structure information in Visual Document Understanding and propose the
 careful and comprehensive ablations of the image encoder, the vision language connector, and various pre-training data choices, we identified several crucial design lessons. For example, we demonstrate that for large-scale multimodal pre-training using a careful mix of
careful and comprehensive ablations of the image encoder, the vision language connector, and various pre-training data choices, we identified several crucial design lessons. For example, we demonstrate that for large-scale multimodal pre-training using a careful mix of
 with common pre-training already exhibits strong mathematical abilities, as evidenced by its impressive accuracy of 97.7% and 72.0% on the GSM8K and MATH benchmarks, respectively, when selecting the best response from 256 random generations. The primary issue with the current
with common pre-training already exhibits strong mathematical abilities, as evidenced by its impressive accuracy of 97.7% and 72.0% on the GSM8K and MATH benchmarks, respectively, when selecting the best response from 256 random generations. The primary issue with the current
 of multiple algorithms that learn from feedback (Expert Iteration, Proximal Policy Optimization (PPO), Return-Conditioned RL) on improving LLM reasoning capabilities. We investigate both sparse and dense rewards provided to the LLM both heuristically and via a learned reward
of multiple algorithms that learn from feedback (Expert Iteration, Proximal Policy Optimization (PPO), Return-Conditioned RL) on improving LLM reasoning capabilities. We investigate both sparse and dense rewards provided to the LLM both heuristically and via a learned reward
