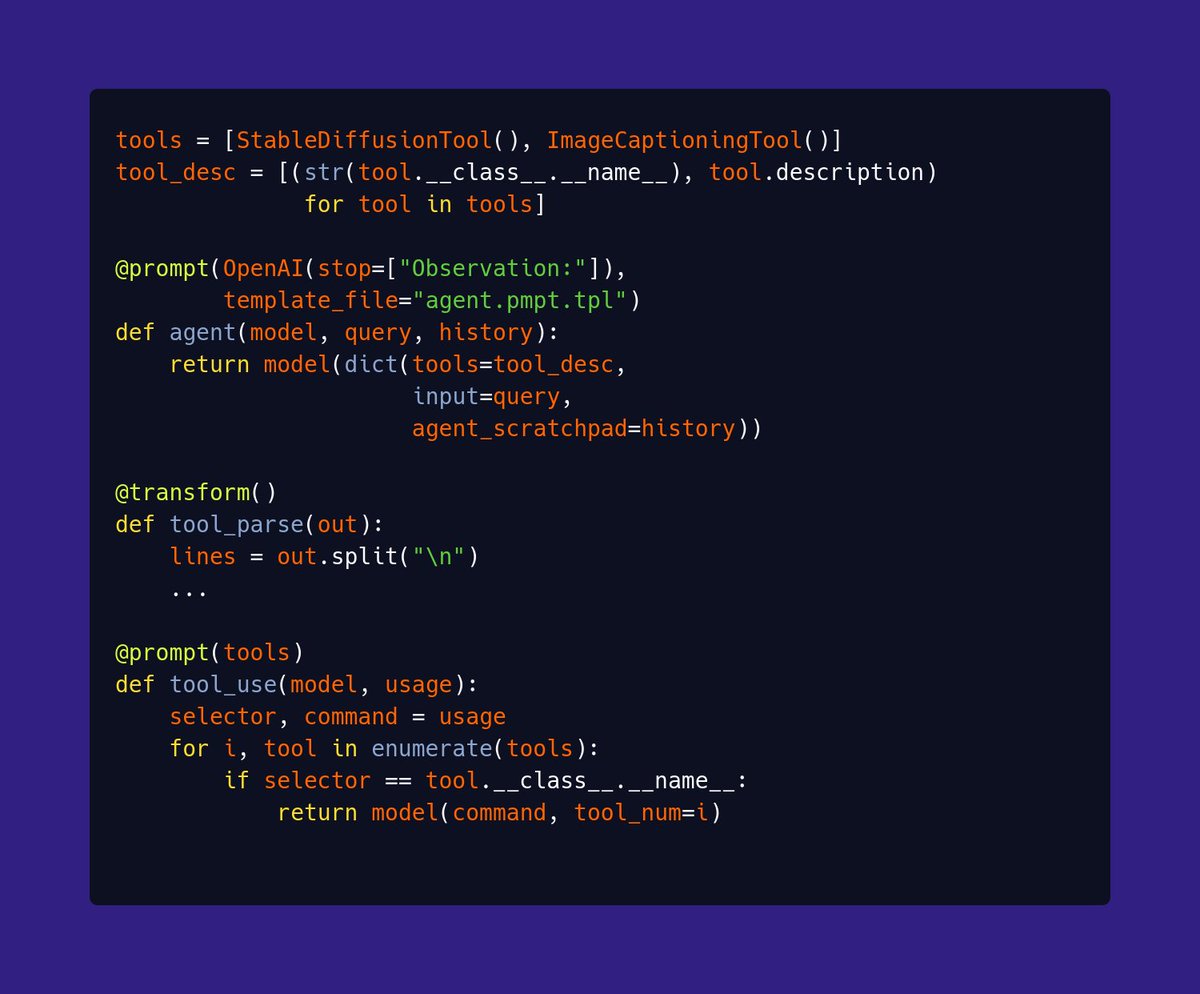
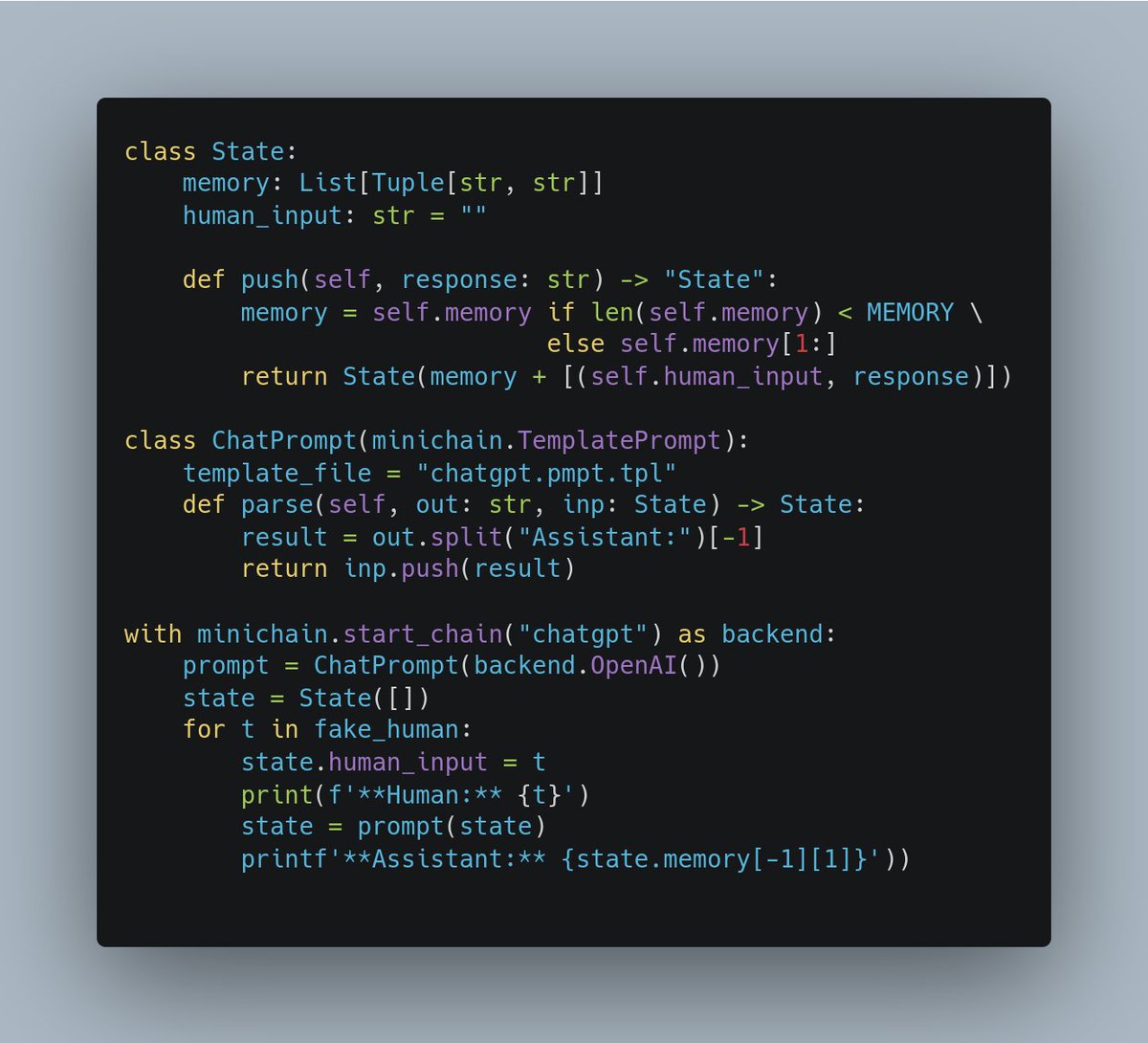
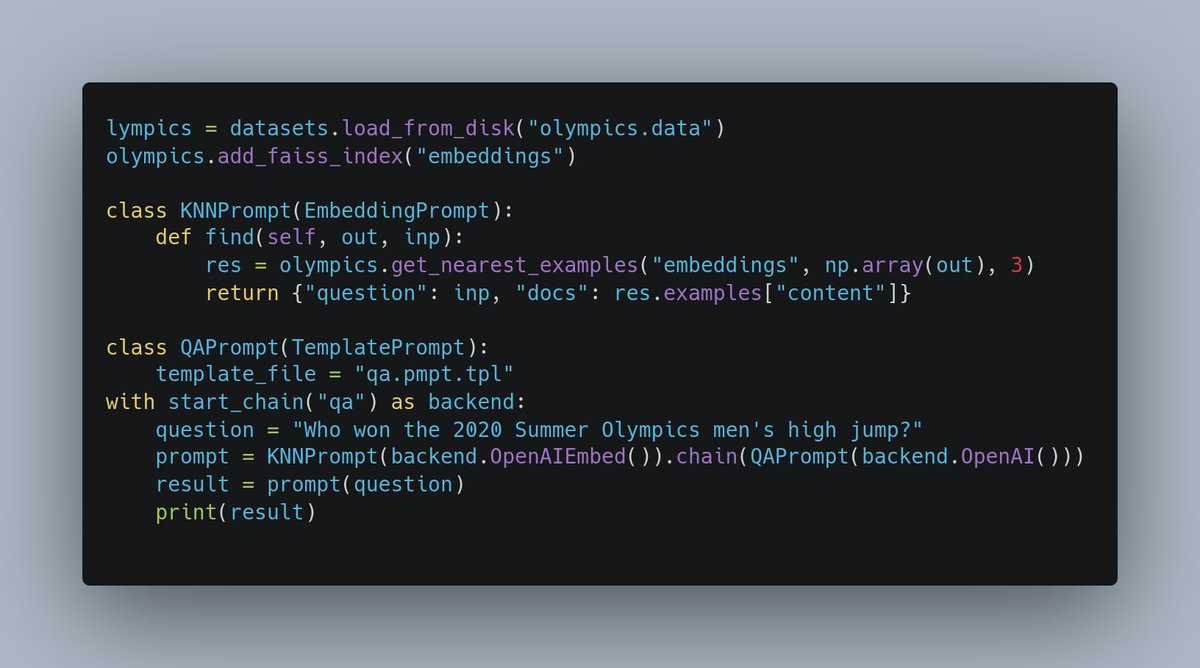
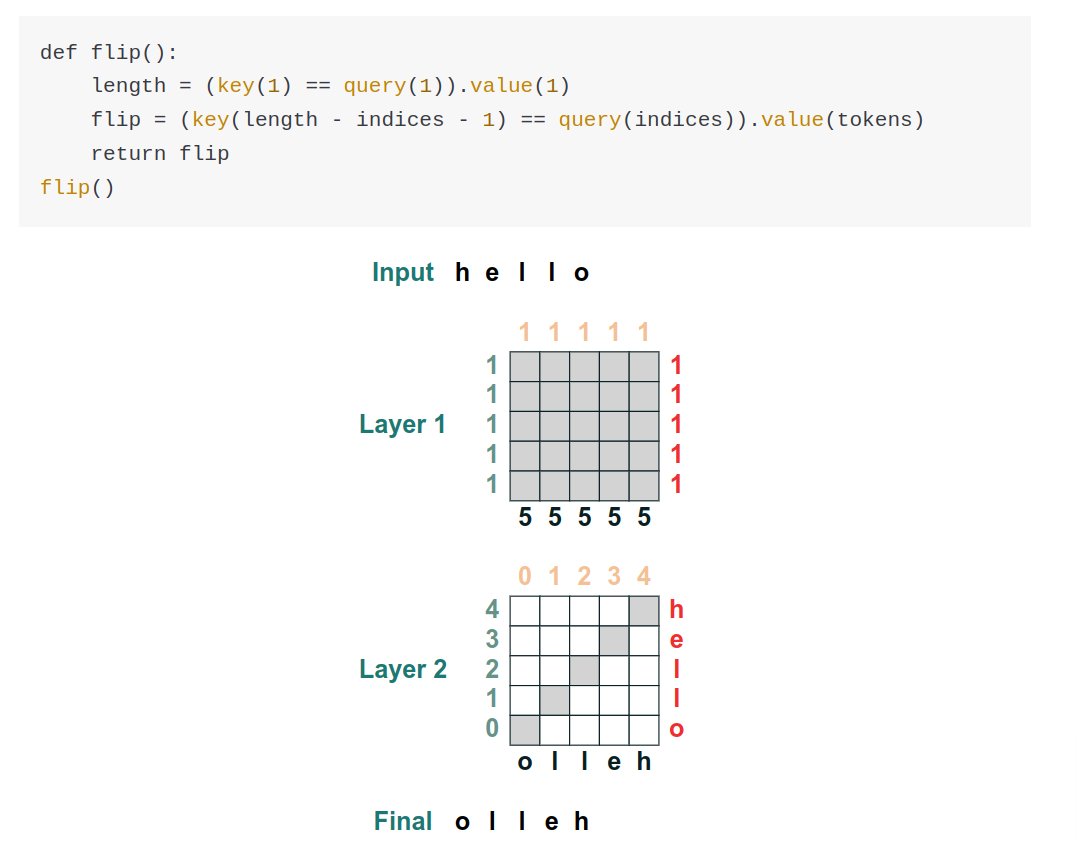
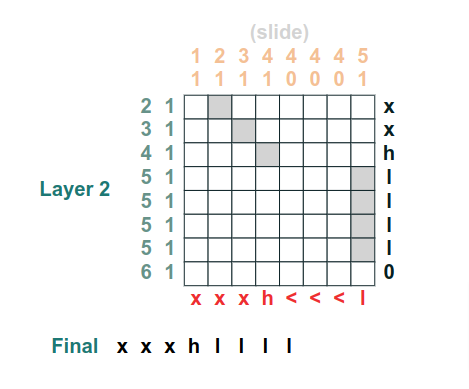
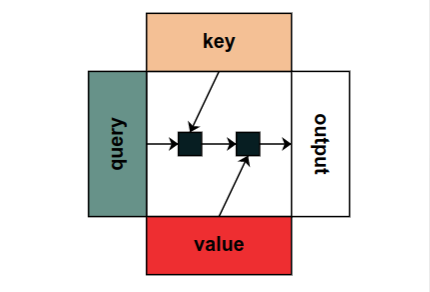
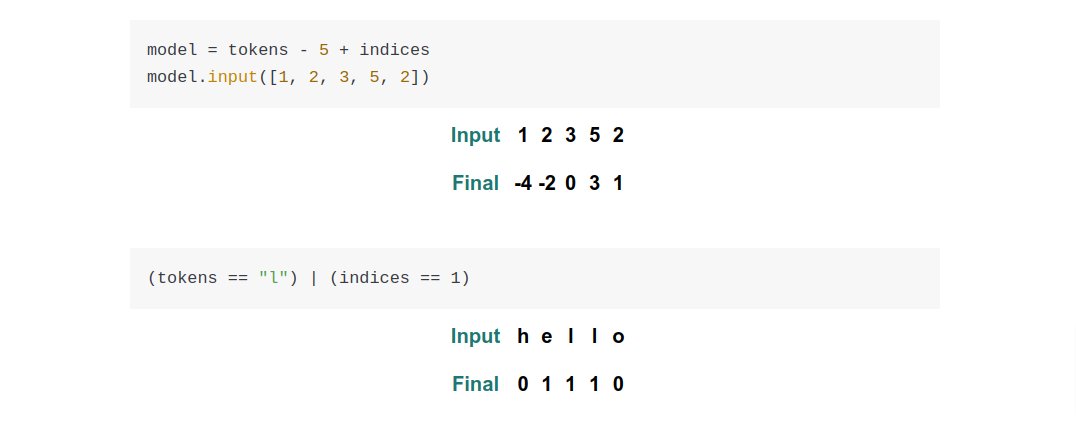
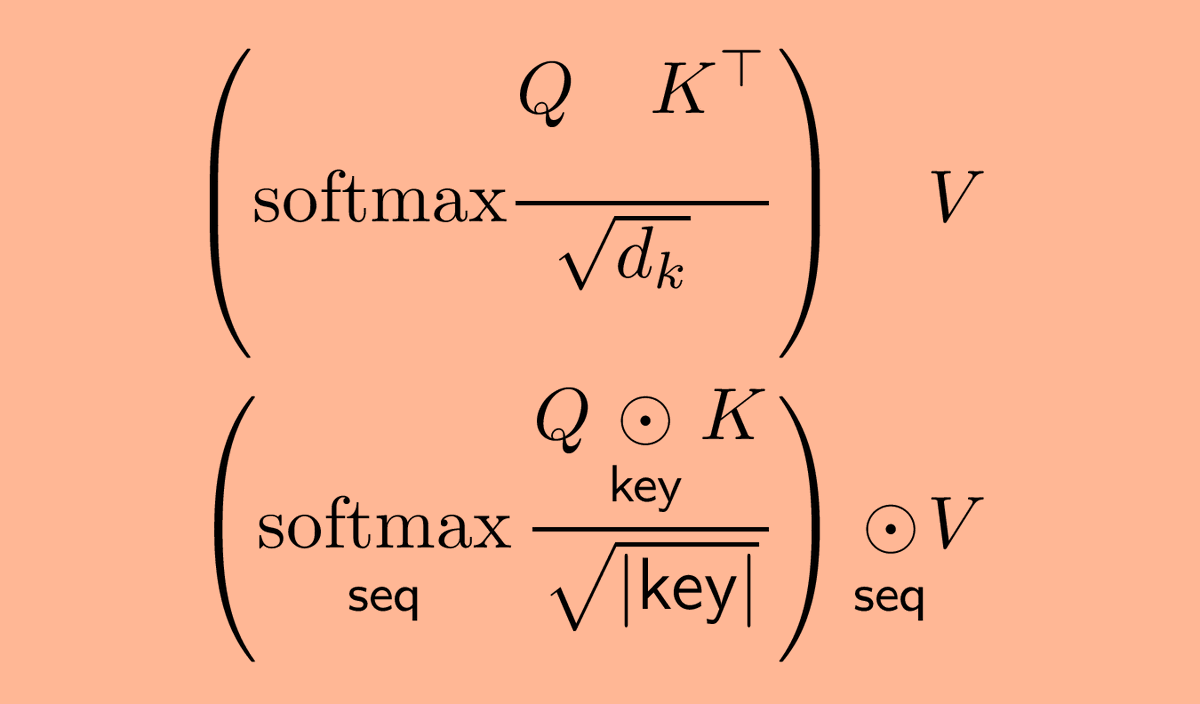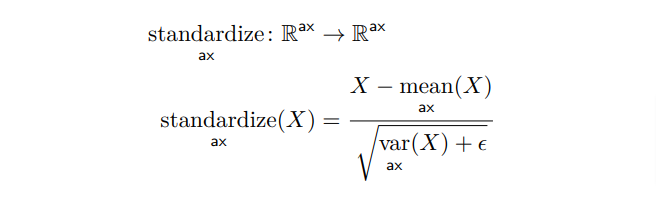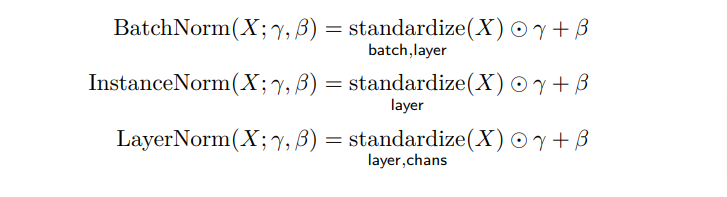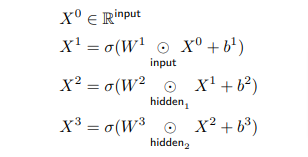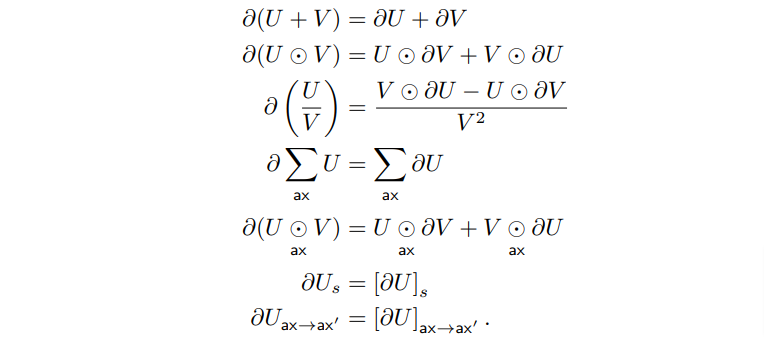Lots of folks reached out to me yesterday about the Rust ML and LLM community. Seems like supportive and intellectually-curious community, so I wanted to highlight some of the projects that you should check out 🧵
dfdx is a static shape-typed tensor library . Uses lots of Rust features and supports full backprop.github.com/coreylowman/df…
candle is an inference time tensor library with similar numpy/pytorch syntax. Check out their full LLM inference example
https://t.co/Mh1bmC5Fhogithub.com/LaurentMazare/…
github.com/LaurentMazare/…
https://t.co/Mh1bmC5Fhogithub.com/LaurentMazare/…
github.com/LaurentMazare/…
smelte is a low-dependency nn model inference library for rust (think more flexible ggml)
github.com/Narsil/smelte-…
github.com/Narsil/smelte-…
faer-rs and its gemms are an entire linear algebra implementation (think blas) in rust.
https://t.co/MWNfPvA1qhgithub.com/sarah-ek/faer-…
github.com/sarah-ek/gemm
https://t.co/MWNfPvA1qhgithub.com/sarah-ek/faer-…
github.com/sarah-ek/gemm
Several others have also ported over and reached out to give tips for the process.
https://t.co/zJHUsxfZ58
https://t.co/ne6VDW0H1Hllama2.rs
github.com/gaxler/llama2.…
github.com/leo-du/llama2.…
https://t.co/zJHUsxfZ58
https://t.co/ne6VDW0H1Hllama2.rs
github.com/gaxler/llama2.…
github.com/leo-du/llama2.…
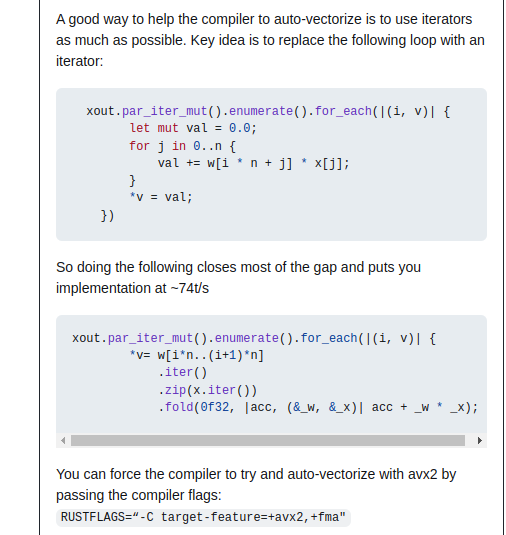
This was a really interesting tip about rust internals from gaxler 
• • •
Missing some Tweet in this thread? You can try to
force a refresh