
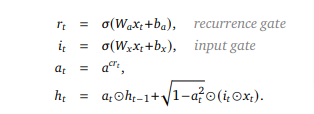
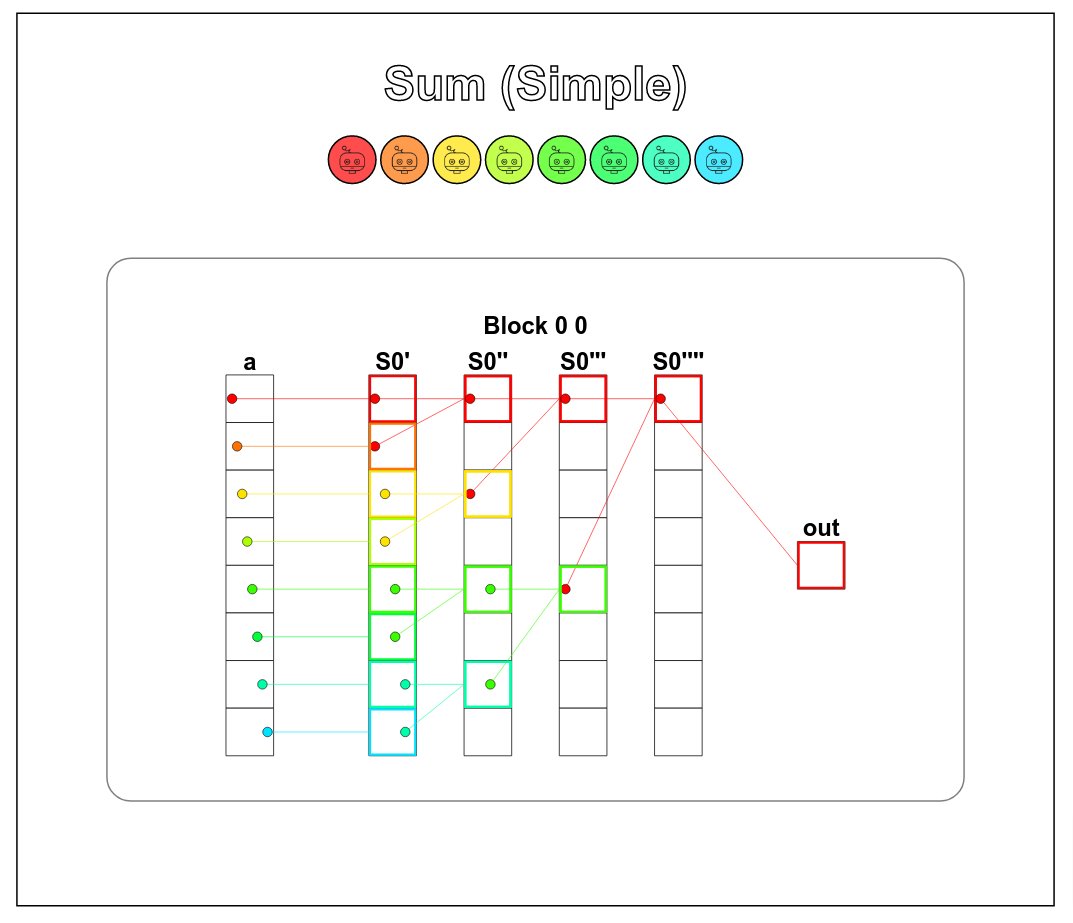
 Core architecture is a state-space model. But that's just a fancy way of parameterizing a 1D CNN. This is the whole thing that replaces attention.
Core architecture is a state-space model. But that's just a fancy way of parameterizing a 1D CNN. This is the whole thing that replaces attention. 
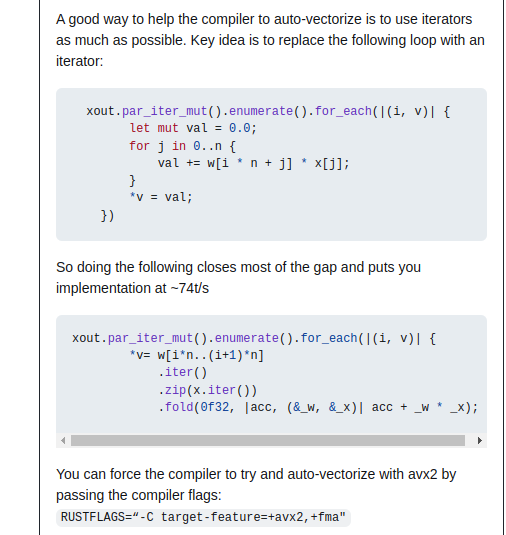
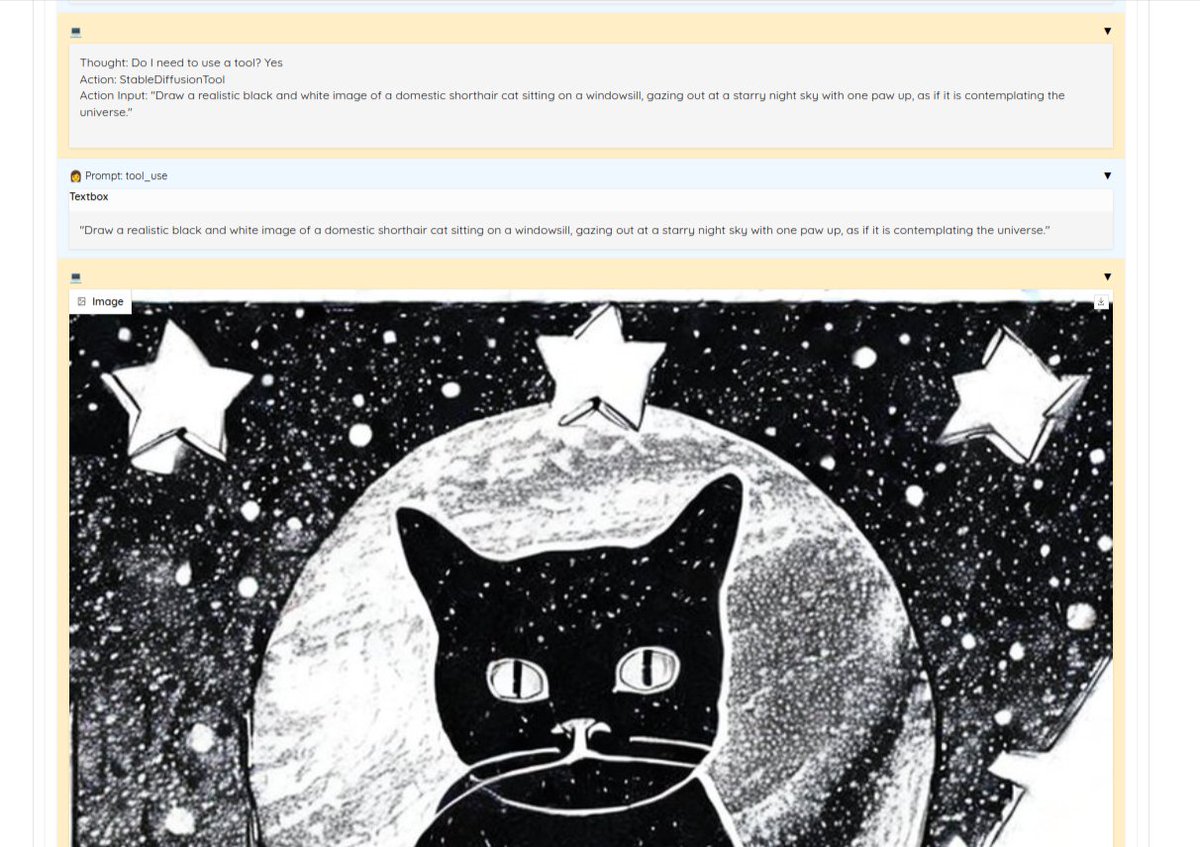 This is mostly an experiment in API design. Trying to keep things explicit and minimal. For example there is no explicit "Agent" or "Tool" abstraction. You build the react agent by just calling functions.
This is mostly an experiment in API design. Trying to keep things explicit and minimal. For example there is no explicit "Agent" or "Tool" abstraction. You build the react agent by just calling functions. 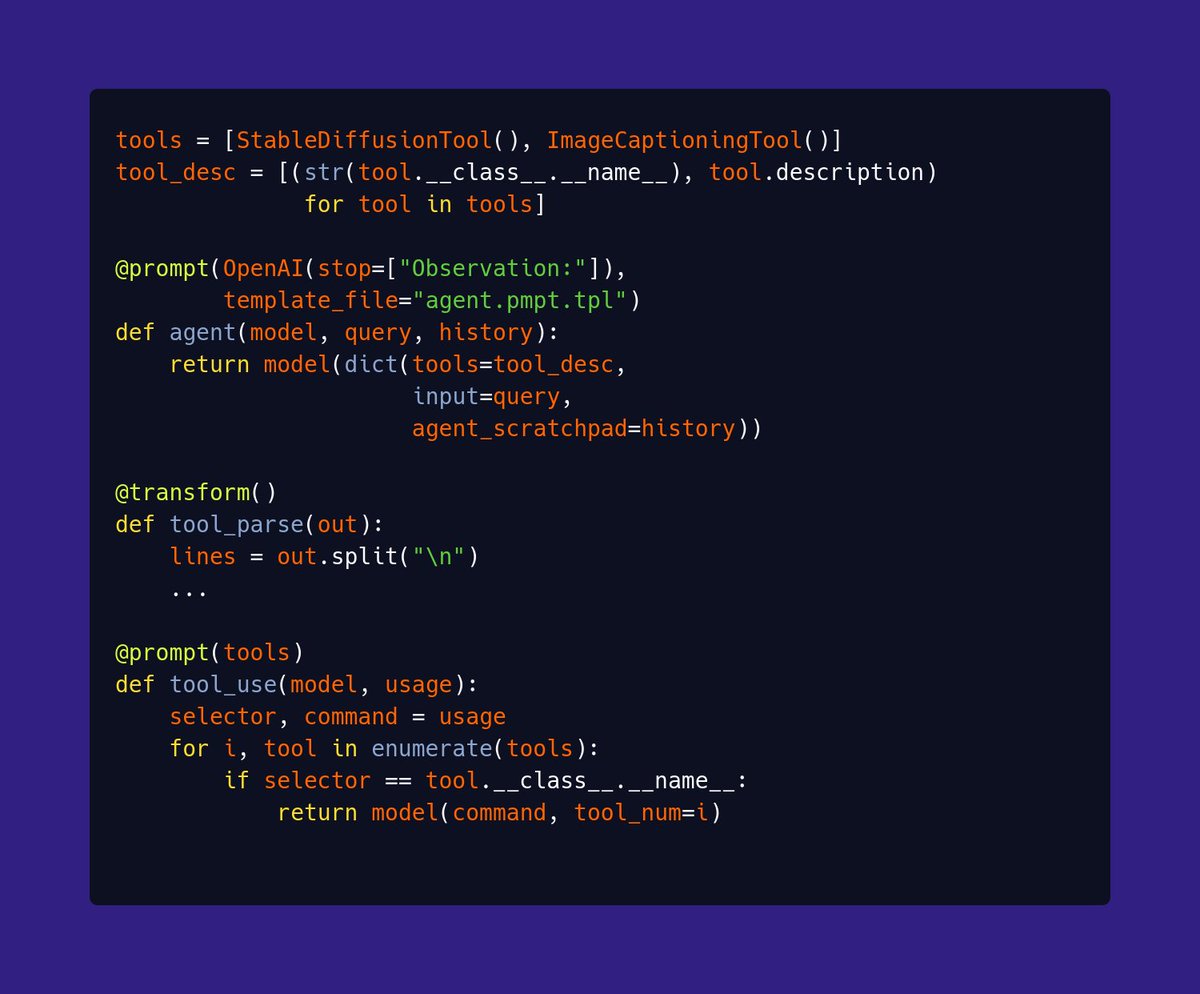
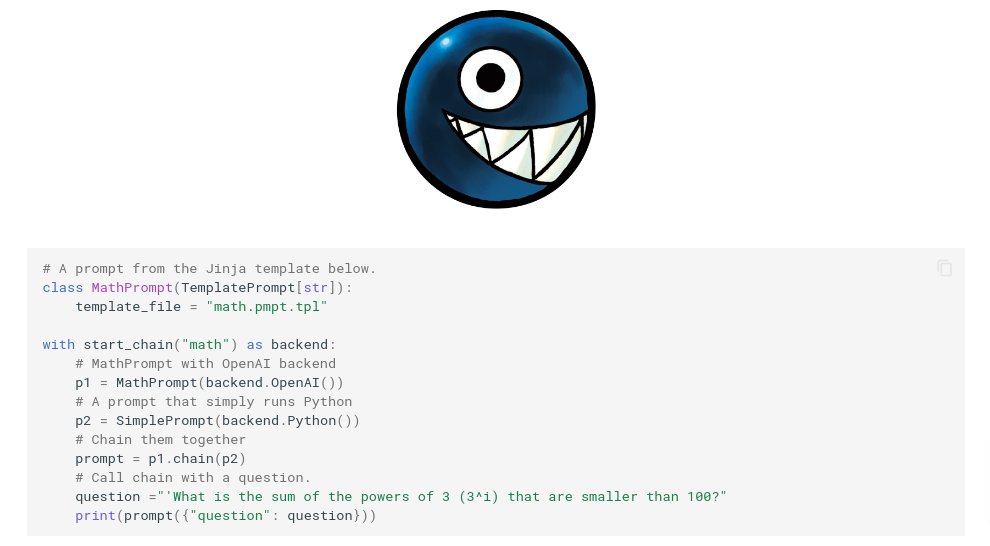 Full "ChatGPT" example with memory
Full "ChatGPT" example with memory 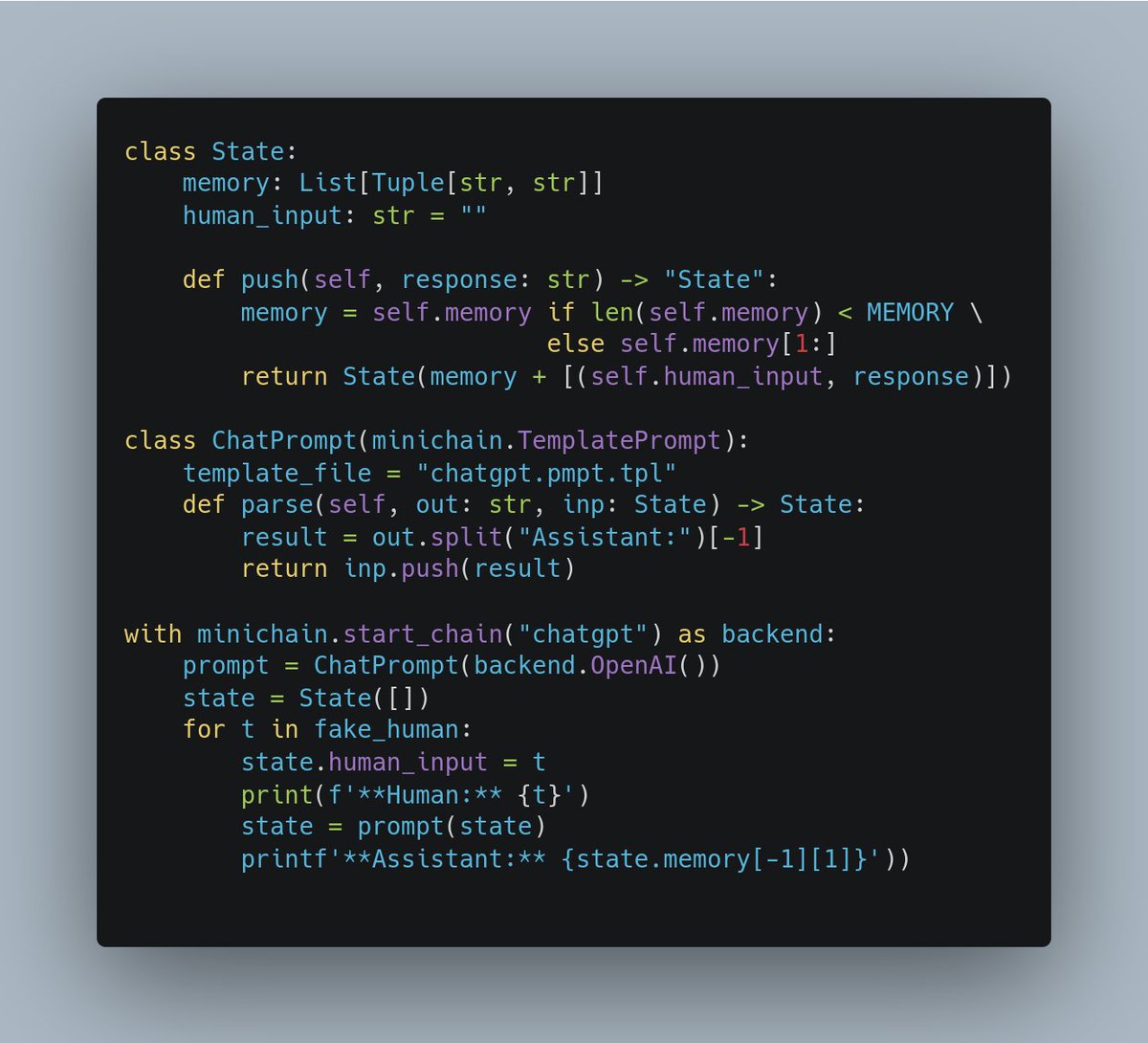
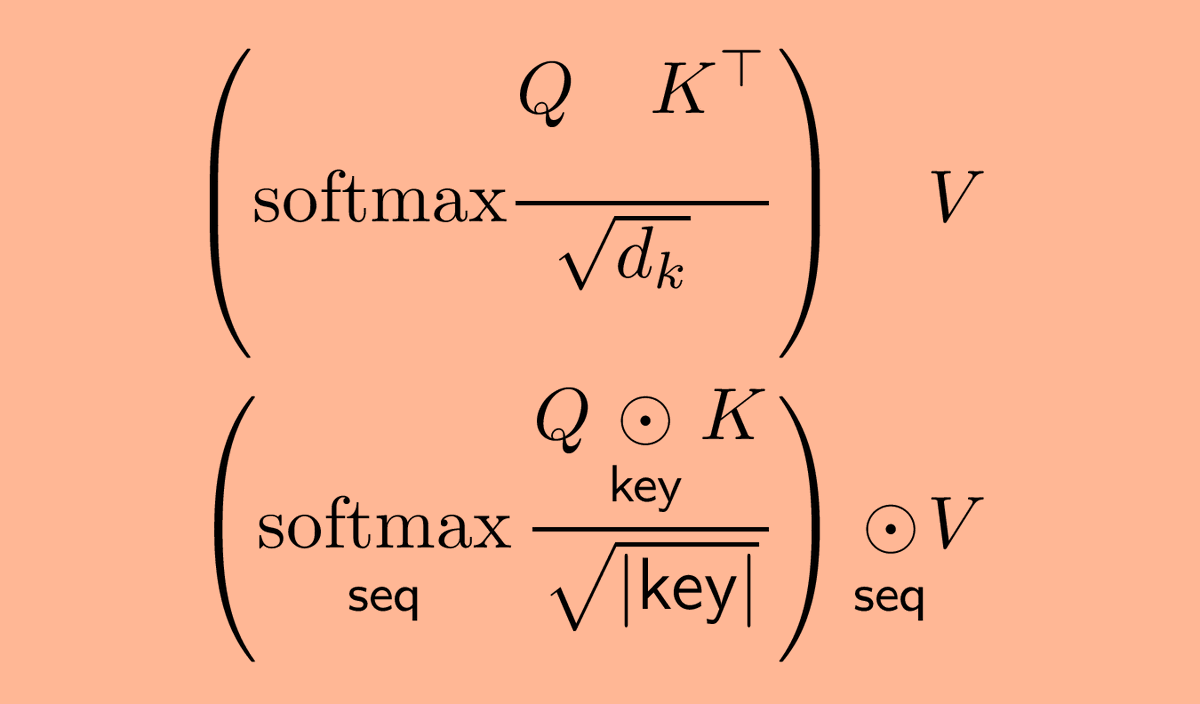 Named Tensor Notation is an attempt to define a mathematical notation with named axes. The central conceit is that deep learning is not linear algebra. And that by using linear algebra we leave many technical details ambiguous to readers.
Named Tensor Notation is an attempt to define a mathematical notation with named axes. The central conceit is that deep learning is not linear algebra. And that by using linear algebra we leave many technical details ambiguous to readers. 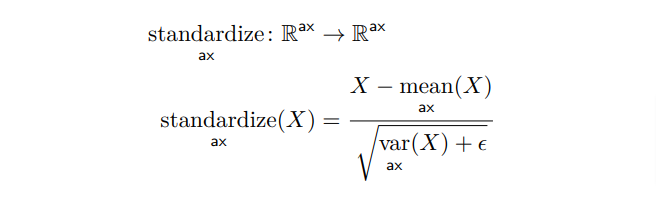
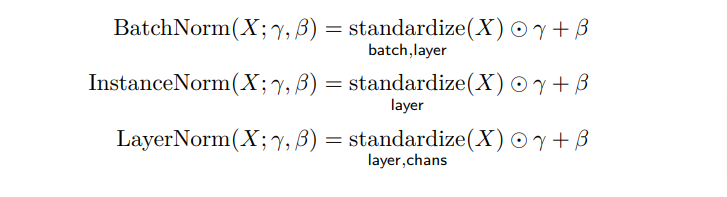

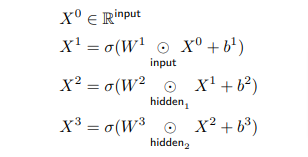
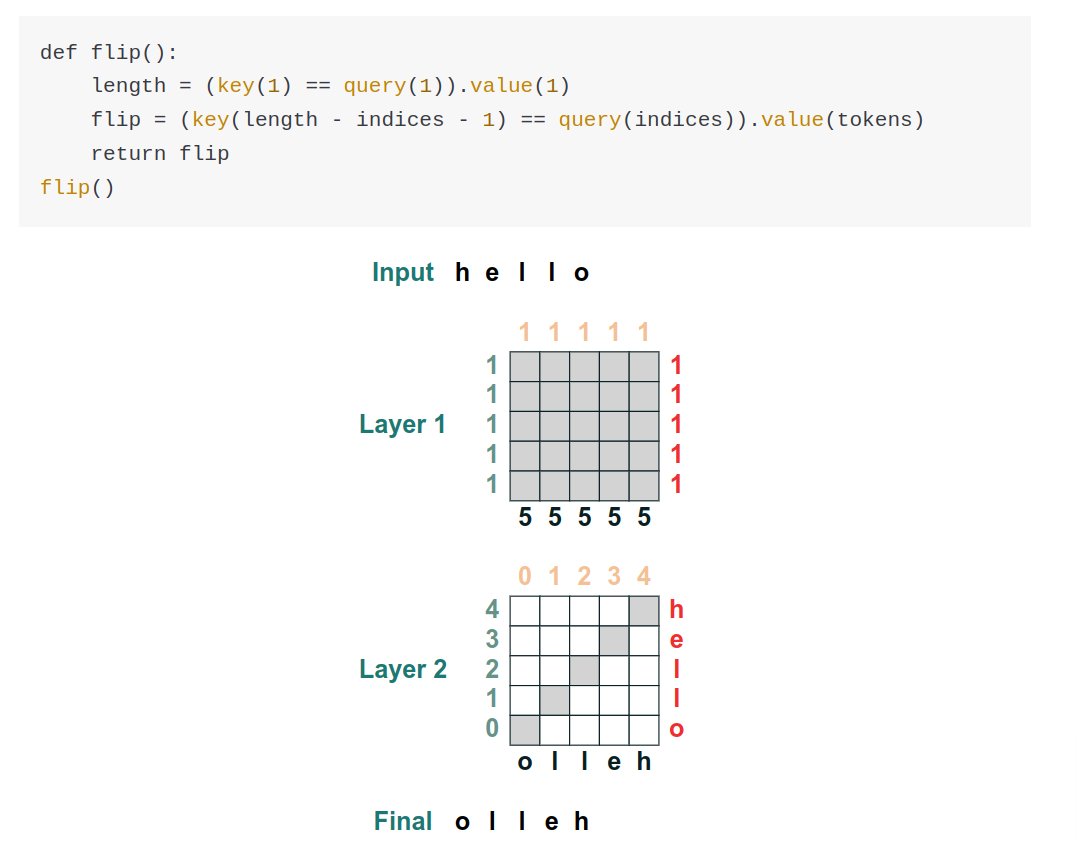
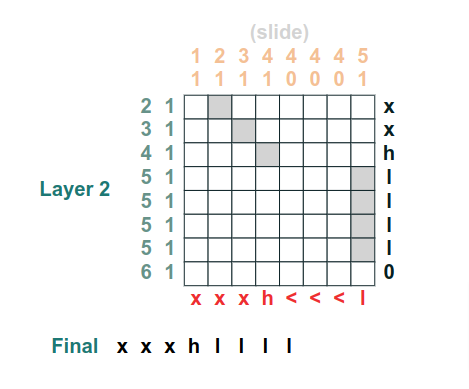
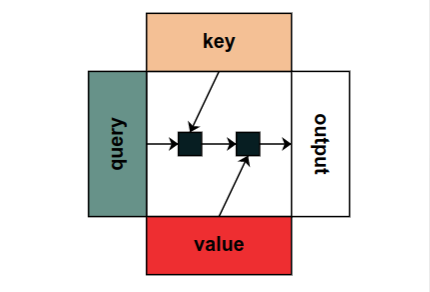
 The blog post walks through the constructs of building a computational model reflecting the transformer architecture.
The blog post walks through the constructs of building a computational model reflecting the transformer architecture. 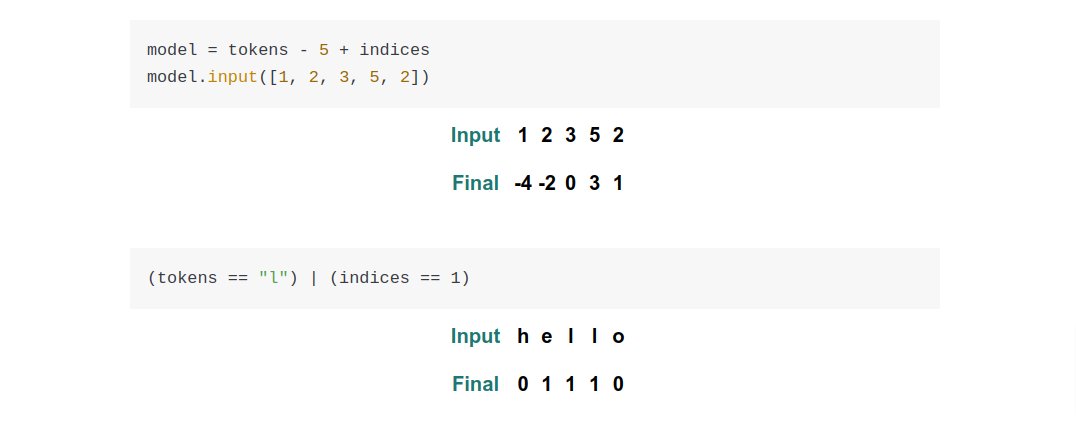
 1) Know the scaling details of the models
1) Know the scaling details of the models


 Last year I taught CUDA in my ML class (because I think it is super important), and it was the closest I have ever come to a full class revolution. For whatever reason parallel programming is just a hard thing to think about.
Last year I taught CUDA in my ML class (because I think it is super important), and it was the closest I have ever come to a full class revolution. For whatever reason parallel programming is just a hard thing to think about.
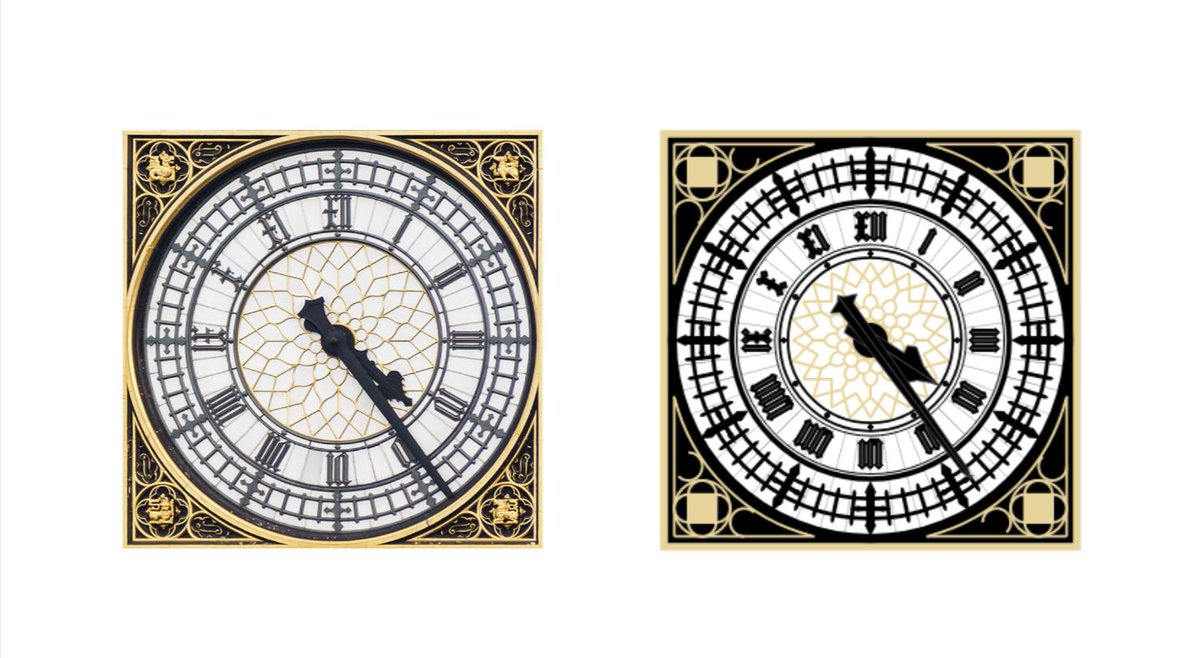 The introduction covers design and specifications of the Roman numerals (I promised it was obsessive).
The introduction covers design and specifications of the Roman numerals (I promised it was obsessive). 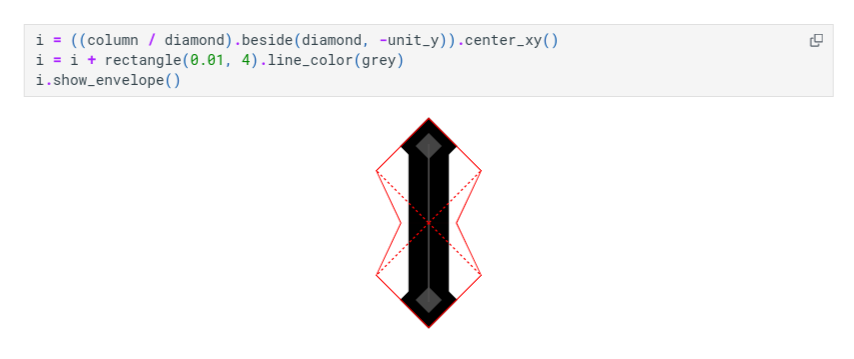


 AI, we are told, is about agents. Like most functions, they look like this.
AI, we are told, is about agents. Like most functions, they look like this. 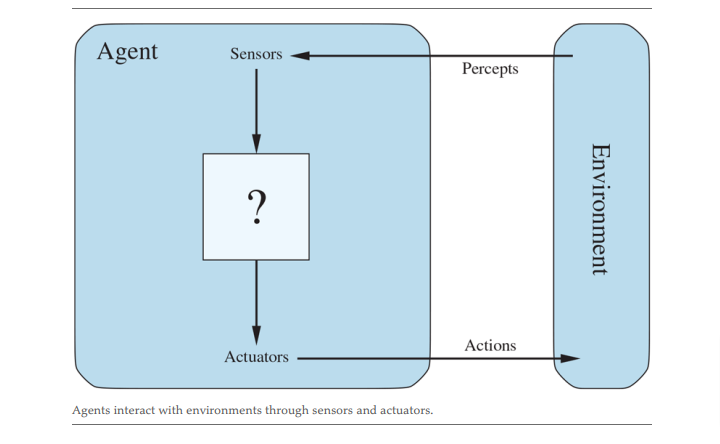



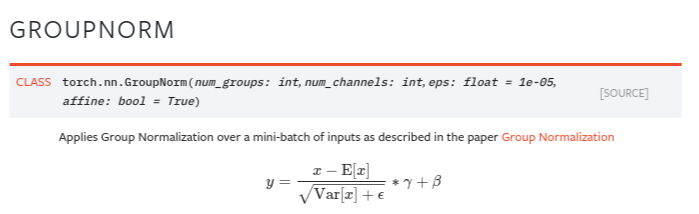 What's the difference between 1d, 2d, and 3d convolutions?
What's the difference between 1d, 2d, and 3d convolutions? 



 The state of benchmarking in NLP right now is so strange. These goofy websites keep precisely-curated leaderboards (paperswithcode.com/sota/language-…), and hardworking grad students cannot get within 2x! these reported results.
The state of benchmarking in NLP right now is so strange. These goofy websites keep precisely-curated leaderboards (paperswithcode.com/sota/language-…), and hardworking grad students cannot get within 2x! these reported results.