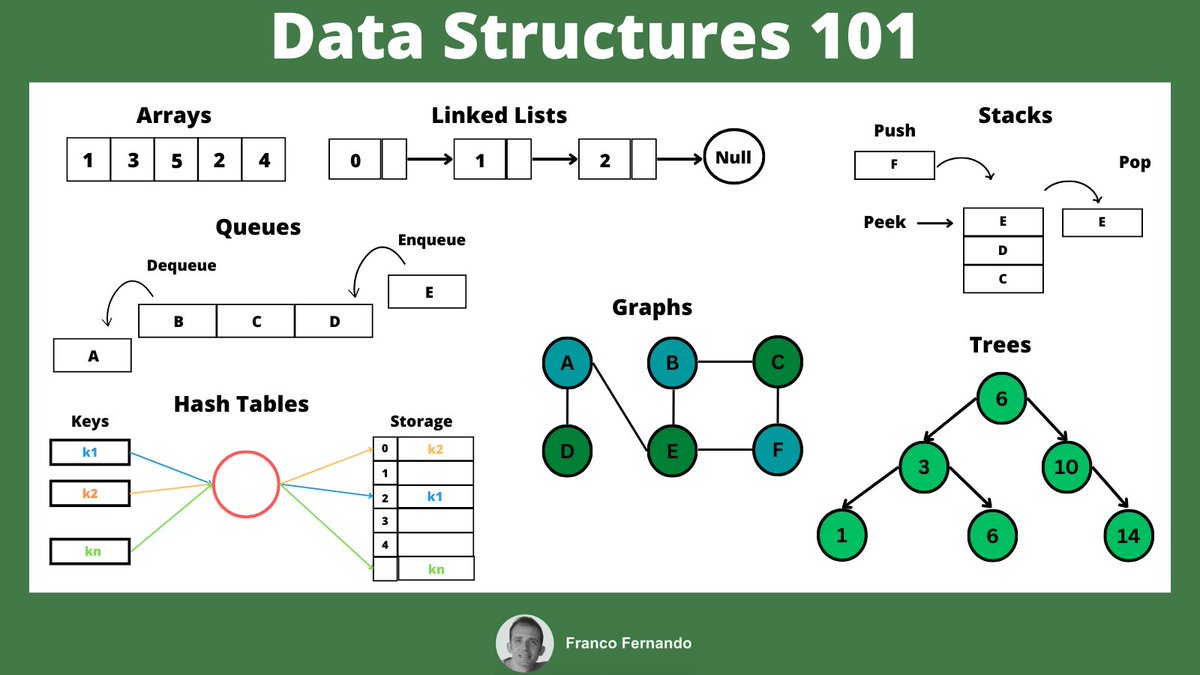
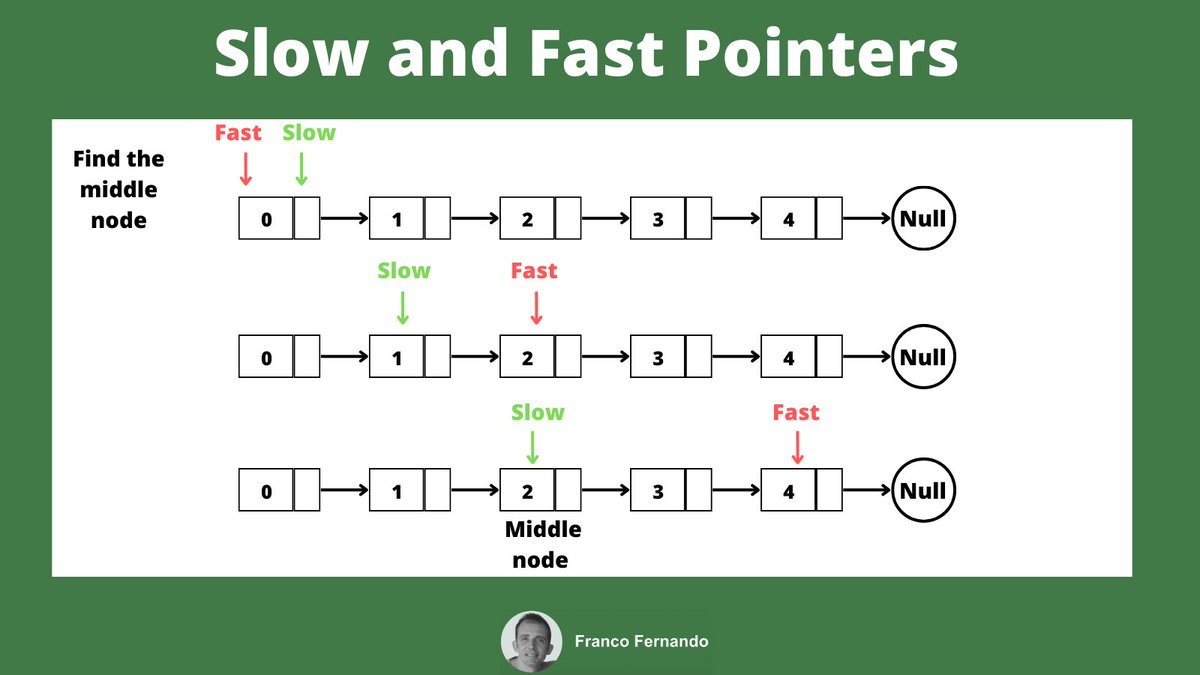
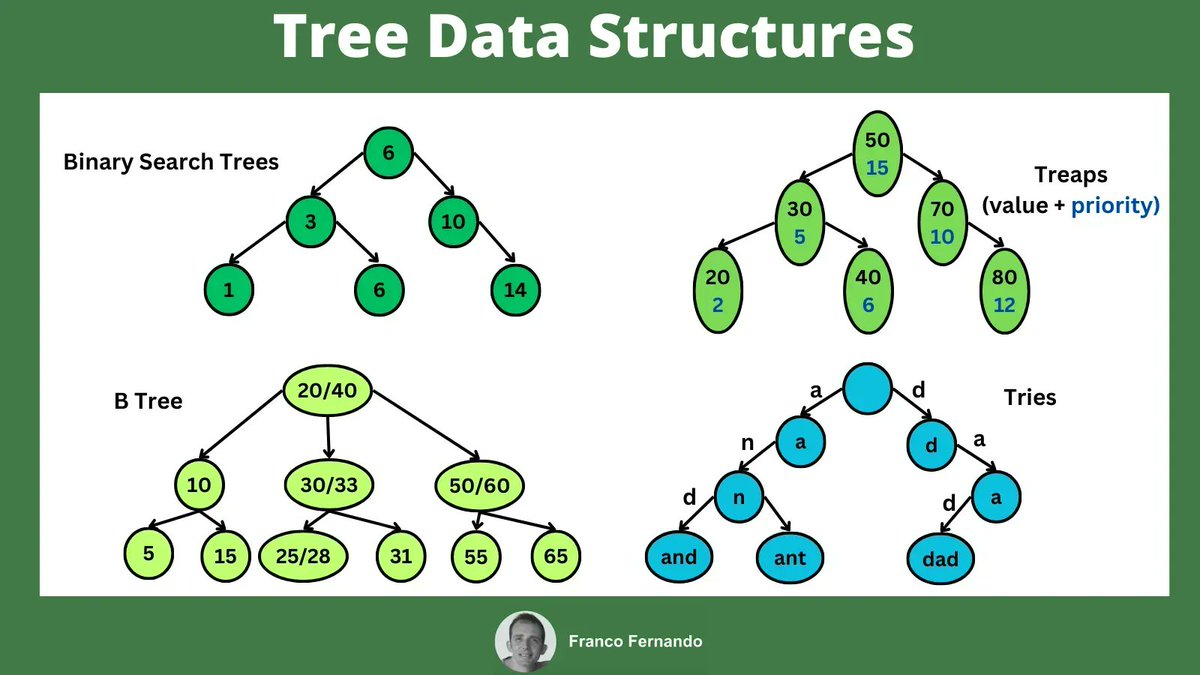
Many applications requires to generate unique IDs in their backend.
This is an easy task in a single server, but it's harder at large-scale.
Here are 3 effective strategies you can use:
{1/9} ↓
This is an easy task in a single server, but it's harder at large-scale.
Here are 3 effective strategies you can use:
{1/9} ↓
Generating unique identifiers isn't difficult in a single server.
For example you can use an incremental ID or a function getting the time of the day.
These strategies fail in a distributed scenario, since they create duplicates.
{2/9}
For example you can use an incremental ID or a function getting the time of the day.
These strategies fail in a distributed scenario, since they create duplicates.
{2/9}
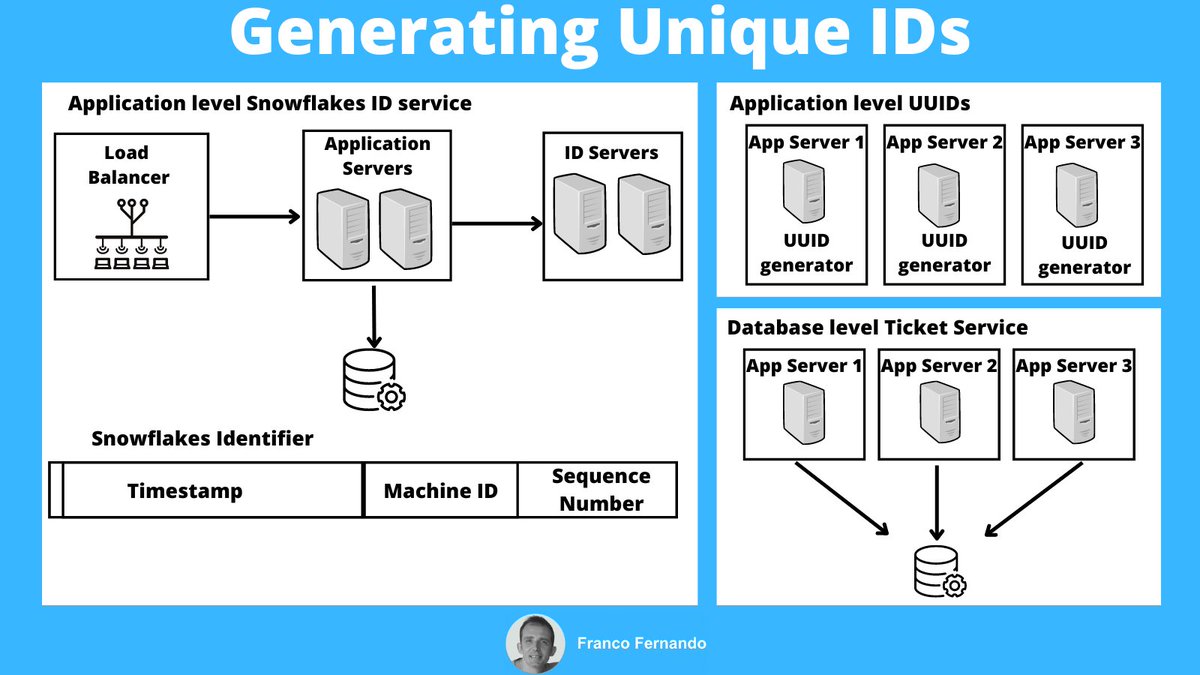
1. Application level Universal Unique Identifiers (UUIDs).
UUIDs are 128-bit numbers that the application can generate in different ways.
For example, it can combine time, the server’s MAC address, or an MD5 hash.
{3/9}
UUIDs are 128-bit numbers that the application can generate in different ways.
For example, it can combine time, the server’s MAC address, or an MD5 hash.
{3/9}
The main benefits of UUIDs are:
• servers don't need to be in sync
• large ID space and low number of collisions
The main drawbacks are:
• big size (128 bit)
• IDs are not sequential
{4/9}
• servers don't need to be in sync
• large ID space and low number of collisions
The main drawbacks are:
• big size (128 bit)
• IDs are not sequential
{4/9}
2. Database level UUIDs.
Many databases provide an auto increment feature.
So a database server can be used to generate unique IDs.
This approach is also known as ticket service and has been used by Flickr.
{5/9}
Many databases provide an auto increment feature.
So a database server can be used to generate unique IDs.
This approach is also known as ticket service and has been used by Flickr.
{5/9}
The main benefits of database generated IDs are:
• the application code gets simpler
• IDs are sequential and short in size
The main drawbacks are:
• the additional round trip to get the IDs from the database
• the database becomes a single point of failures
{6/9}
• the application code gets simpler
• IDs are sequential and short in size
The main drawbacks are:
• the additional round trip to get the IDs from the database
• the database becomes a single point of failures
{6/9}
3. Snowflake ID generation service.
This form of unique IDs has been used at Twitter, and Instagram.
The idea is to generate the IDs composing multiple fields:
• 41-bit timestamp
• 10-bit worker ID
• 12-bit sequence number
• 1-bit reserved for future usage
{7/9}
This form of unique IDs has been used at Twitter, and Instagram.
The idea is to generate the IDs composing multiple fields:
• 41-bit timestamp
• 10-bit worker ID
• 12-bit sequence number
• 1-bit reserved for future usage
{7/9}
Some observations:
• the timestamp with ms resolution can work for 70 years after a starting epoch
• a coordination service (Zookeeper) assigns the worker ID considering both data center and server ID
• the sequence number support up to 4096 unique IDs per ms
{8/9}
• the timestamp with ms resolution can work for 70 years after a starting epoch
• a coordination service (Zookeeper) assigns the worker ID considering both data center and server ID
• the sequence number support up to 4096 unique IDs per ms
{8/9}
Such a way of generating IDs has many advantages:
• it's available since can be implemented by 1024 machines
• it's scalable since each machine can generate 4096 IDs per ms
• IDs are time sortable since the timestamp is in the higher-order bits
{9/9}
• it's available since can be implemented by 1024 machines
• it's scalable since each machine can generate 4096 IDs per ms
• IDs are time sortable since the timestamp is in the higher-order bits
{9/9}
Every week I write about algorithms, distributed systems and software engineering.
If you liked this thread, you can check my newsletter as well.
Your support encourages me to keep writing!
polymathicengineer.com
If you liked this thread, you can check my newsletter as well.
Your support encourages me to keep writing!
polymathicengineer.com
• • •
Missing some Tweet in this thread? You can try to
force a refresh