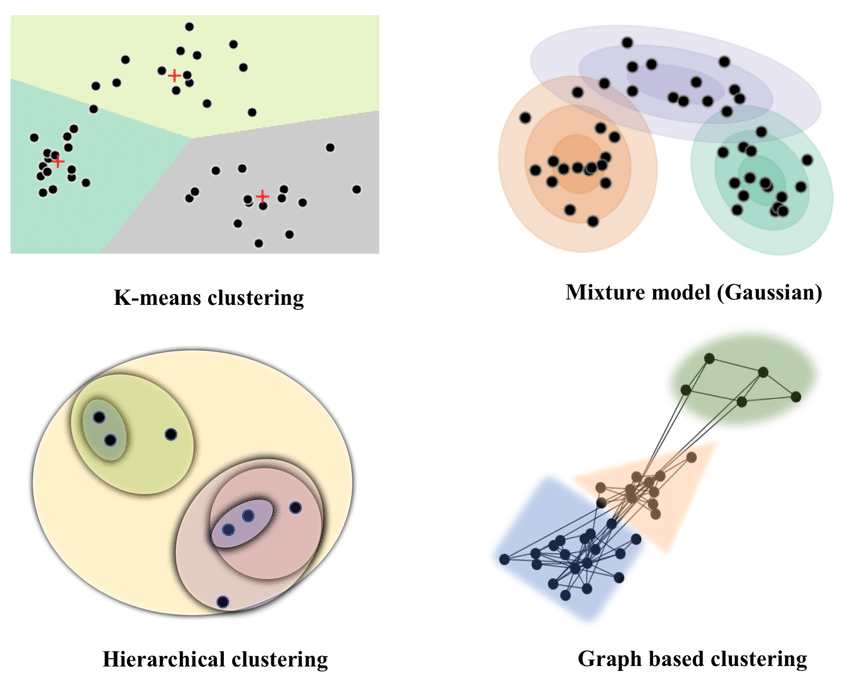
✅Image Classification in ML/Deep Learning- Explained in simple terms with implementation details (code, techniques and best tips).
A quick thread 👇🏻🧵
#MachineLearning #DataScientist #Coding #100DaysofCode #hubofml #deeplearning #DataScience
PC : ResearchGate
A quick thread 👇🏻🧵
#MachineLearning #DataScientist #Coding #100DaysofCode #hubofml #deeplearning #DataScience
PC : ResearchGate

1/ Imagine you have a big box of different toys, like cars, dolls, and animals. You want to sort these toys and put them into different groups based on what they look like.
2/ Just like when you learn to tell the difference between a cat and a dog, the computer learns by looking at the important parts of the pictures, like the shapes and colors. It practices a lot until it gets really good at putting the pictures into the right groups.
3/ Image classification in ML is a task where a model is trained to categorize images into different classes or categories. Each image is represented as a set of numerical values (pixels), and goal of model is to learn patterns and features in these numerical representations.
4/ Uses neural network to analyze the patterns in the pixel values of images. This neural network learns to recognize certain features like shapes, colors, and textures that are common in each class of images.
5/ How its done -
Data Collection and Preprocessing: Collect a dataset of labeled images for different classes. Preprocess the images to ensure they are of consistent size and format.
Data Collection and Preprocessing: Collect a dataset of labeled images for different classes. Preprocess the images to ensure they are of consistent size and format.

6/ Feature Extraction: Extract relevant features from the images. This could involve techniques like resizing, cropping, and converting images to a suitable format for processing.

7/ Feature Representation: Transform the extracted features into a suitable representation for machine learning algorithms. Common representations include raw pixel values or more advanced features extracted from deep neural networks.

8/ Training a Classifier: Use a machine learning algorithm, such as a neural network, to train a model on the labeled training data. The model learns to recognize patterns in the features associated with each class.

9/ Validation and Hyperparameter Tuning: Validate the trained model using a validation dataset. Fine-tune hyperparameters to optimize model performance.

10/ Testing and Evaluation: Test the model on a separate test dataset to evaluate its performance. Common evaluation metrics include accuracy, precision, recall, and F1-score.

11/ Image Classification Techniques -
Histogram of Oriented Gradients (HOG):HOG is a feature descriptor that captures the distribution of gradient orientations in an image. It is particularly useful for object detection and pedestrian detection tasks.
Histogram of Oriented Gradients (HOG):HOG is a feature descriptor that captures the distribution of gradient orientations in an image. It is particularly useful for object detection and pedestrian detection tasks.

12/ Local Binary Patterns (LBP):LBP is a texture descriptor that characterizes the local patterns of pixel intensities in an image. It's commonly used for texture classification and face recognition.

13/ Deep Learning Methods:
Feature Learning: CNNs automatically learn features from raw data, reducing the need for handcrafted feature engineering.
Hierarchical Representations: CNNs learn hierarchical features at different levels of abstraction, capturing complex patterns.
Feature Learning: CNNs automatically learn features from raw data, reducing the need for handcrafted feature engineering.
Hierarchical Representations: CNNs learn hierarchical features at different levels of abstraction, capturing complex patterns.
14/ Scalability: Deep learning models can handle large datasets effectively, leading to better generalization.
Transfer Learning: Pretrained CNNs can be fine-tuned on new tasks, leveraging knowledge learned from large datasets.
Transfer Learning: Pretrained CNNs can be fine-tuned on new tasks, leveraging knowledge learned from large datasets.
15/ CNNs are a class of deep neural networks particularly well-suited for image classification and computer vision tasks. They are composed of convolutional layers, pooling layers, and fully connected layers.
16/ Convolutional Layers: These layers apply convolutional operations to input images. They consist of learnable filters (kernels) that slide over the input, detecting features like edges, corners, and textures.
17/ Pooling Layers: They reduce spatial dimensions of feature maps, retaining important information while reducing computation.
Fully Connected Layers: These layers take the flattened output from previous layers and map it to final class labels using dense connections.
Fully Connected Layers: These layers take the flattened output from previous layers and map it to final class labels using dense connections.
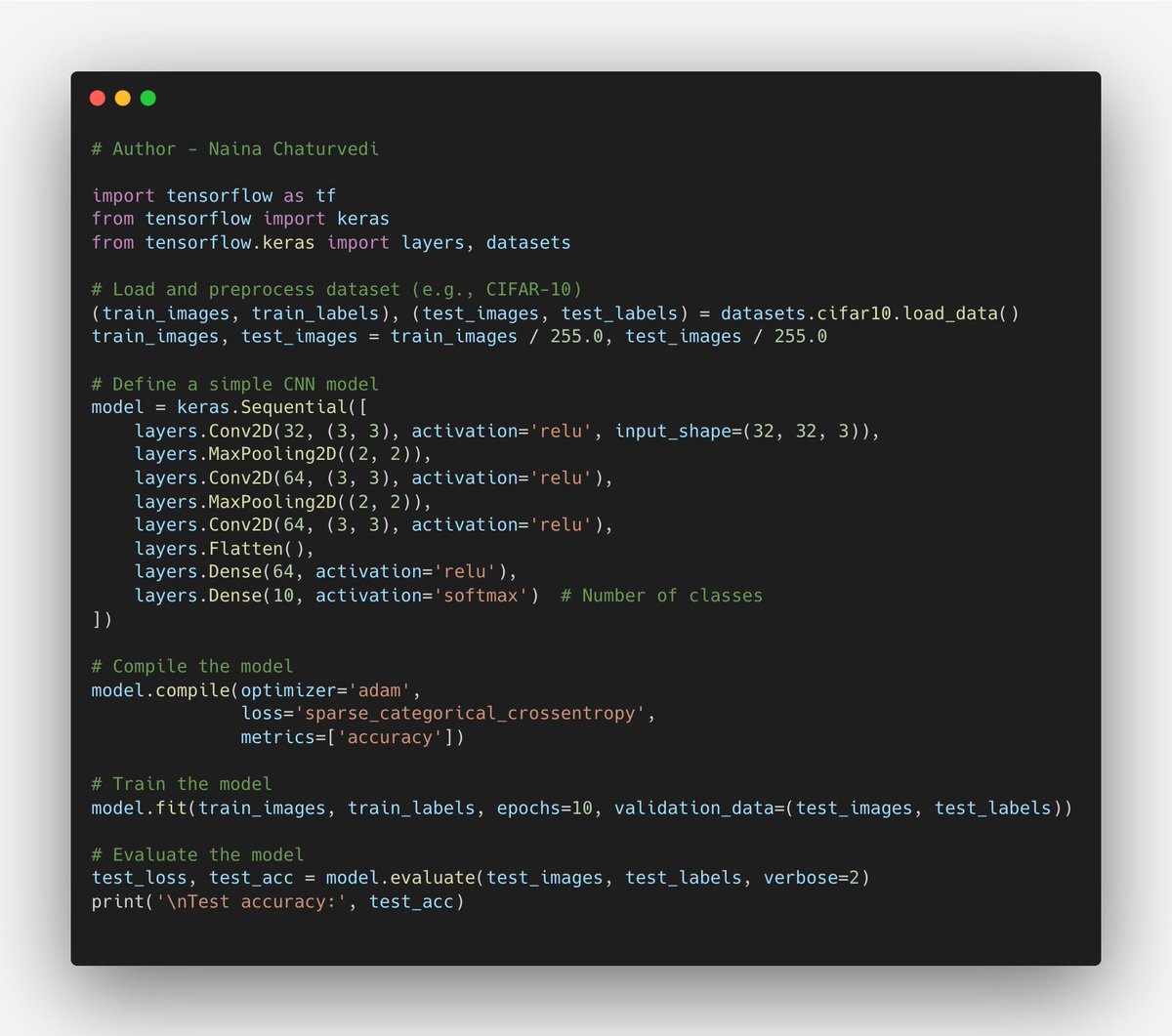
18/ ResNet :ResNet introduced the concept of residual blocks, where the output of a layer is added to the output of a previous layer, allowing the network to learn residual functions. This architecture enabled the training of very deep networks (e.g., ResNet-50, ResNet-101).
19/Inception (GoogLeNet) : Uses multiple filter sizes in parallel within a single layer. It included 1x1, 3x3, and 5x5 convolutional filters in the same layer, capturing features at different scales. Inception also used global average pooling to reduce the number of parameters.

20/ Data Augmentation:Data augmentation involves applying various transformations to the original images to create new training examples without changing the underlying labels. This technique helps model become more robust and generalize better to variations in the input data.
21/ data augmentation techniques :
Flipping: Horizontally or vertically flipping the image.
Rotation: Rotating the image by a certain angle.
Zooming: Zooming in or out on the image.
Translation: Shifting the image horizontally or vertically.
Flipping: Horizontally or vertically flipping the image.
Rotation: Rotating the image by a certain angle.
Zooming: Zooming in or out on the image.
Translation: Shifting the image horizontally or vertically.

22/Training Process of a CNN:
Initialization: Initialize the model's weights and biases. Modern CNN architectures are often initialized using techniques like He initialization or Xavier initialization to help with convergence.
Initialization: Initialize the model's weights and biases. Modern CNN architectures are often initialized using techniques like He initialization or Xavier initialization to help with convergence.

23/ Forward Propagation: Pass the input data through the network's layers using forward propagation. Each layer applies transformations (convolution, activation, pooling) to generate feature representations.
24/ Loss Computation: Calculate the loss, which quantifies the difference between the predicted output and the true labels. Common loss functions for classification include categorical cross-entropy and sparse categorical cross-entropy.
25/ Backpropagation: Compute the gradients of the loss with respect to the model's parameters using backpropagation. Gradients indicate how the loss changes concerning each parameter.
26/ Optimization: Update the model's parameters to minimize the loss. Optimization algorithms adjust the weights and biases based on the computed gradients. Popular optimization algorithms include SGD (Stochastic Gradient Descent), Adam, and RMSProp.
27/ Transfer Learning:
It involves using a pre-trained model, trained on a massive dataset (e.g., ImageNet), as a starting point for a new task. The idea is that the features learned by the model on the source task (e.g image classification) are often useful for related tasks
It involves using a pre-trained model, trained on a massive dataset (e.g., ImageNet), as a starting point for a new task. The idea is that the features learned by the model on the source task (e.g image classification) are often useful for related tasks
28/ Fine-Tuning: After loading the pre-trained model, you replace the final layers with new ones tailored to your specific task. These new layers are randomly initialized, and then the entire model is fine-tuned on the target dataset.

29/ Evaluation Metrics:
Accuracy: Accuracy measures the proportion of correctly predicted instances out of the total instances in the dataset. It's a common metric but may not be suitable for imbalanced datasets.
Accuracy: Accuracy measures the proportion of correctly predicted instances out of the total instances in the dataset. It's a common metric but may not be suitable for imbalanced datasets.
30/Precision: Precision calculates the proportion of true positive predictions out of all positive predictions. It's useful when the cost of false positives is high.
31/Recall (Sensitivity or True Positive Rate): Recall measures the proportion of true positive predictions out of all actual positive instances. It's useful when the cost of false negatives is high.
32/F1-Score: The F1-score is the harmonic mean of precision and recall. It provides a balance between precision and recall, especially when there's an imbalance between classes.
33/ Confusion Matrix: A confusion matrix visualizes the model's performance by showing the counts of true positive, true negative, false positive, and false negative predictions.
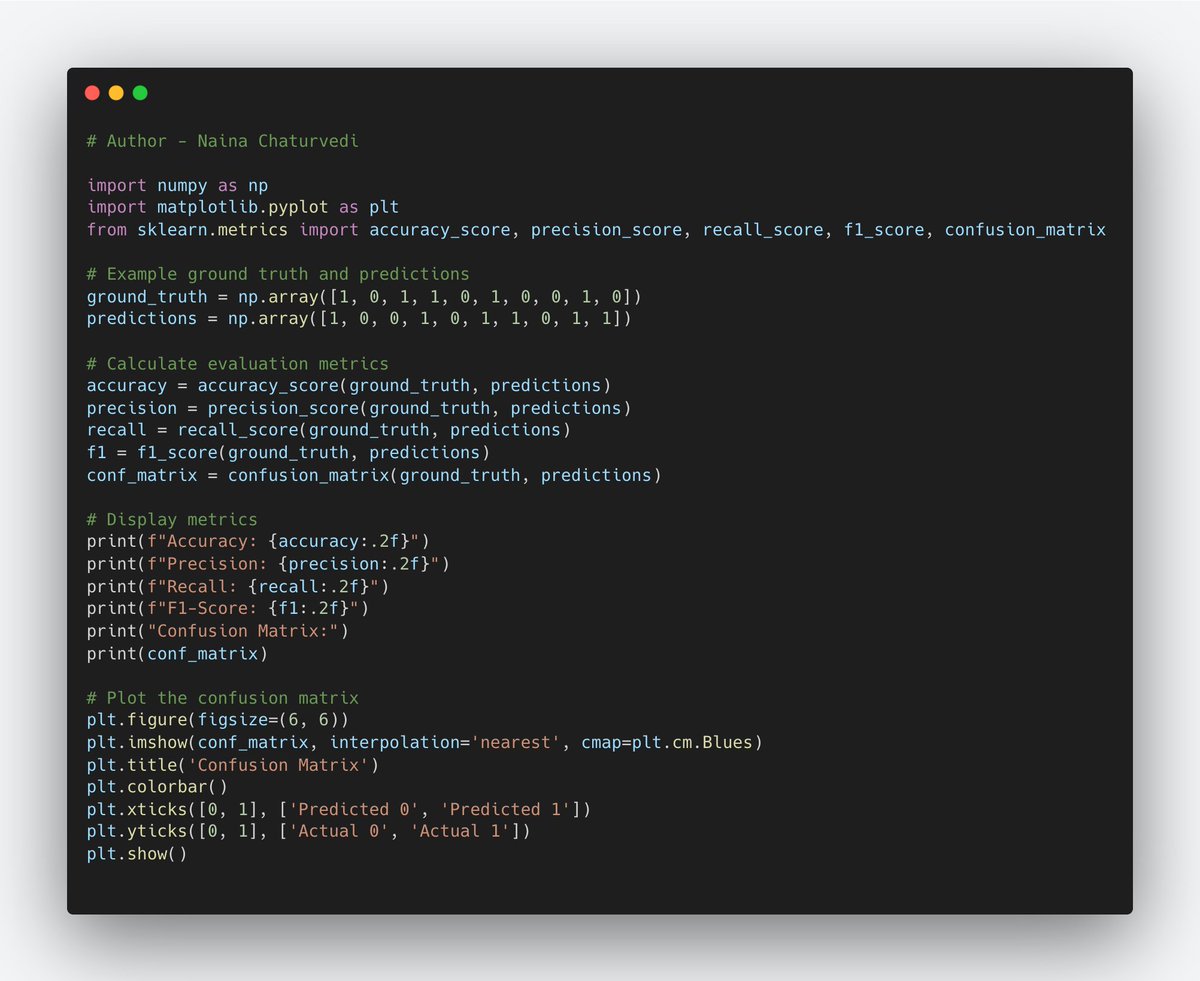
34/The choice of evaluation metric depends on the problem and class distribution:
Accuracy: Suitable for balanced datasets, but it might not be informative for highly imbalanced datasets where one class greatly outnumbers the other(s).
Accuracy: Suitable for balanced datasets, but it might not be informative for highly imbalanced datasets where one class greatly outnumbers the other(s).
35/Precision and Recall: Useful when class distribution is imbalanced. It focuses on minimizing false positives, while recall focuses on minimizing false negatives.
F1-Score: Balances precision and recall, particularly useful when both false positives & false negatives are imp.
F1-Score: Balances precision and recall, particularly useful when both false positives & false negatives are imp.
36/ Overfitting -
Overfitting occurs when a model captures noise and random variations in the training data, leading to overly complex and tailored solutions. The implications of overfitting include:
Overfitting occurs when a model captures noise and random variations in the training data, leading to overly complex and tailored solutions. The implications of overfitting include:
37/Poor Generalization: The model's performance on new, unseen data is significantly worse.
High Variance: The model's predictions vary greatly when exposed to different samples from the same distribution.
High Variance: The model's predictions vary greatly when exposed to different samples from the same distribution.
38/ Regularization Techniques:
Dropout: It randomly deactivates a fraction of neurons during each training iteration. This prevents individual neurons from becoming overly specialized and encourages network to learn more robust features. Dropout helps prevent co-adaptation.
Dropout: It randomly deactivates a fraction of neurons during each training iteration. This prevents individual neurons from becoming overly specialized and encourages network to learn more robust features. Dropout helps prevent co-adaptation.
39/Weight Decay (L2 Regularization): Weight decay involves adding a penalty term to the loss function based on the magnitude of the model's weights. This encourages the model to learn smaller weights, which reduces the complexity of the model and prevents overfitting.
40/Early Stopping: It involves monitoring the model's performance on a validation dataset during training. If the validation performance starts to degrade, training is halted early to prevent overfitting. This helps find the optimal point where the model generalizes well.

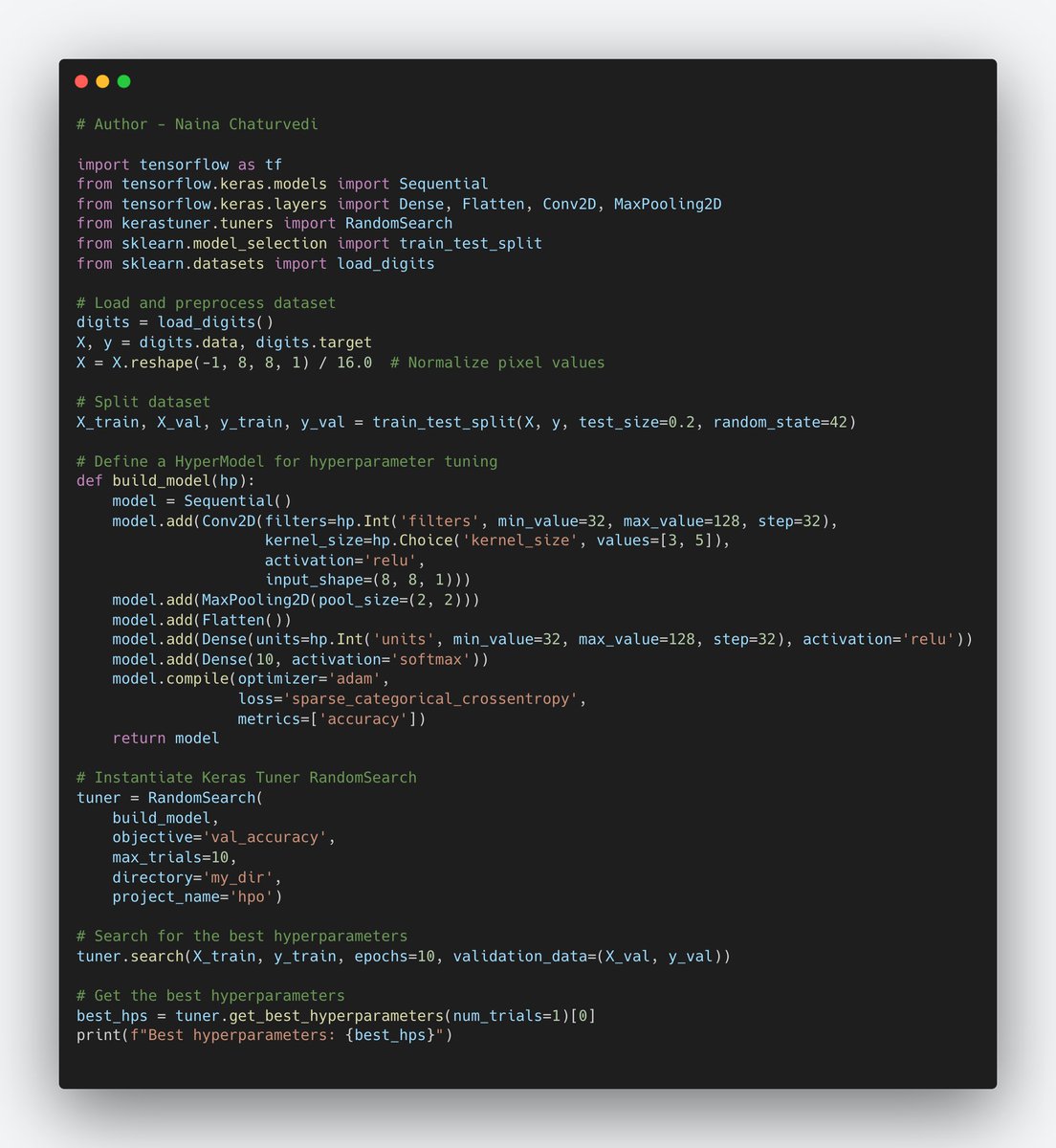
41/ Hyperparameters play a crucial role in performance of ML models, including deep neural networks. They define the settings of the training process and impact how the model learns. Finding optimal hyperparameter values can greatly influence the model's performance.
42/ Significance of Hyperparameters:
Learning Rate: Determines the step size in the optimization algorithm. Too high of a learning rate might lead to divergence, while too low might result in slow convergence. It's a crucial hyperparameter to balance for efficient training.
Learning Rate: Determines the step size in the optimization algorithm. Too high of a learning rate might lead to divergence, while too low might result in slow convergence. It's a crucial hyperparameter to balance for efficient training.
43/Batch Size: The batch size defines how many samples are processed together before updating the model's weights. Smaller batch sizes might lead to noisy gradients, while larger ones might require more memory. It also affects the convergence speed.
44/Network Architecture: Hyperparameters like the number of layers, units per layer, activation functions, dropout rates, etc., define the architecture of the neural network. These choices influence the model's complexity and capacity to learn.
45/Finding Optimal Hyperparameters:
Grid Search and Random Search: Exhaustively searching a predefined range of hyperparameter values or randomly sampling from those ranges can help find good combinations. However, they can be computationally expensive.
Grid Search and Random Search: Exhaustively searching a predefined range of hyperparameter values or randomly sampling from those ranges can help find good combinations. However, they can be computationally expensive.
46/Bayesian Optimization: Bayesian optimization builds a probabilistic model of the function to optimize (in this case, the model's performance) and iteratively suggests new hyperparameters to try based on previous results.

47/ Activation Functions and Normalization Techniques:
Activation Functions (ReLU, ): It introduces non-linearity to the network, allowing it to learn complex relationships in data. Rectified Linear Unit (ReLU) is widely used due to its simplicity and effectiveness.
Activation Functions (ReLU, ): It introduces non-linearity to the network, allowing it to learn complex relationships in data. Rectified Linear Unit (ReLU) is widely used due to its simplicity and effectiveness.
48/ Batch Normalization: helps stabilize and accelerate the training process by normalizing the output of each layer. It reduces internal covariate shift, making training more stable and allowing for higher learning rates.

49/ GPU Acceleration for Training Large CNNs:
These are parallel and well-suited for training deep neural networks due to their ability to perform matrix operations efficiently. TensorFlow and other deep learning frameworks can leverage GPUs to accelerate the training process.
These are parallel and well-suited for training deep neural networks due to their ability to perform matrix operations efficiently. TensorFlow and other deep learning frameworks can leverage GPUs to accelerate the training process.

50/Fine-Tuning Pre-trained Models:
Fine-tuning involves taking a pre-trained model and adapting it to a new task or dataset. The idea is to retrain the last few layers of the model while keeping the earlier layers frozen to retain general features learned on a large dataset.
Fine-tuning involves taking a pre-trained model and adapting it to a new task or dataset. The idea is to retrain the last few layers of the model while keeping the earlier layers frozen to retain general features learned on a large dataset.

51/ Attention Mechanisms: In image classification, attention mechanisms can help models focus on important regions of an image, reducing the reliance on irrelevant features. This is especially valuable when objects of interest are small or occluded by other objects.
52/ Transformers: Capture long-range dependencies in images and learn complex relationships between pixels. Vision Transformers (ViTs) divide an image into fixed-size patches and use a transformer architecture to process them, allowing for more scalable image classification.
53/Capsule Networks: Capsule networks aim to capture the spatial hierarchies and poses of objects, which can lead to improved generalization and handling of variations in object orientation and appearance.
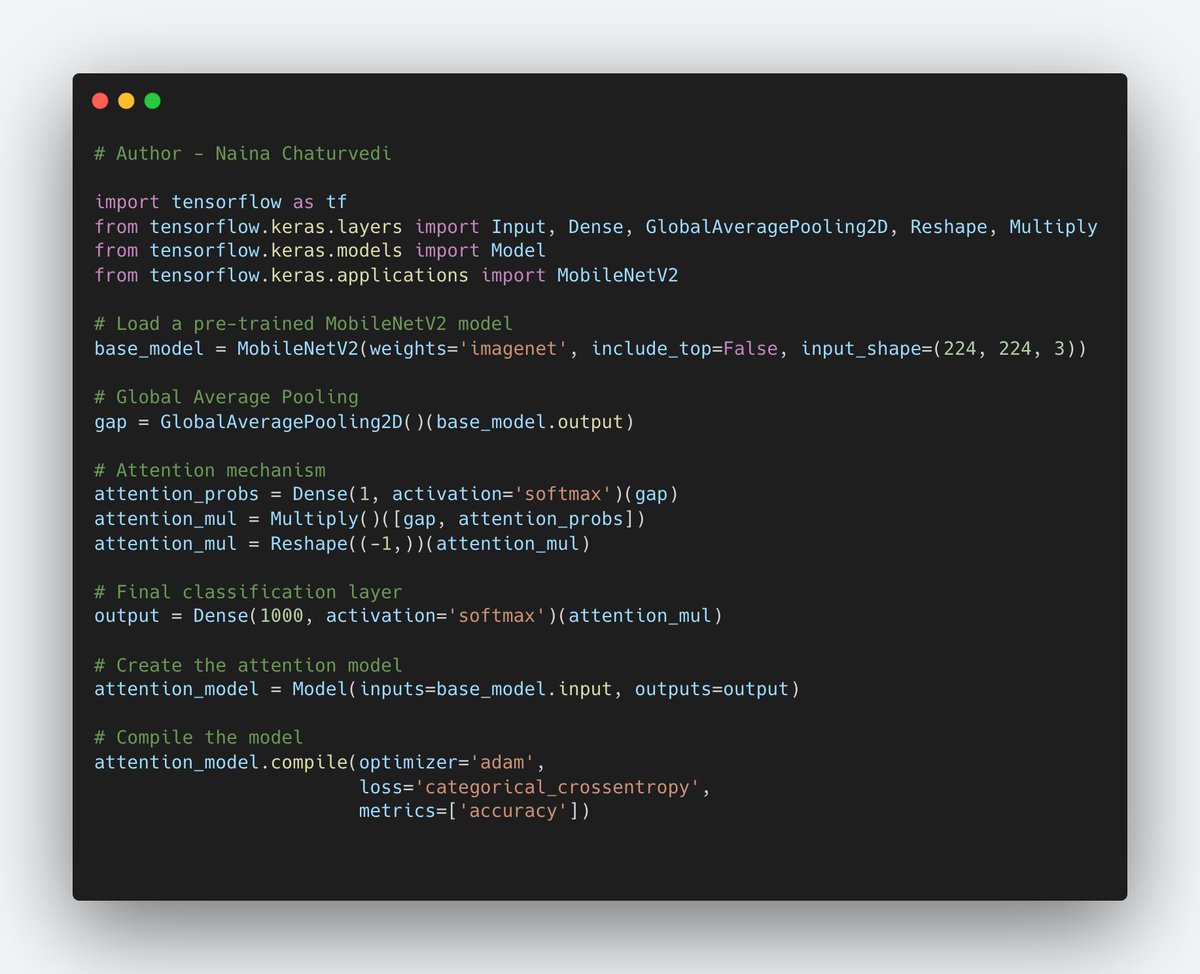
54/ Techniques for Achieving high-performance image classification models -
Start with a Solid Architecture: Choose an appropriate neural network architecture for your problem. Modern CNN architectures like VGG, ResNet, and Inception are excellent starting points.
Start with a Solid Architecture: Choose an appropriate neural network architecture for your problem. Modern CNN architectures like VGG, ResNet, and Inception are excellent starting points.
55/Data Preprocessing: Preprocess your dataset consistently by resizing images, normalizing pixel values, and applying data augmentation to enhance model generalization.
Transfer Learning: Leverage pre-trained models to benefit from their learned features. Fine-tune them.
Transfer Learning: Leverage pre-trained models to benefit from their learned features. Fine-tune them.
56/Hyperparameter Tuning: Experiment with different hyperparameters, including learning rates, batch sizes, and regularization techniques, to find the optimal configuration.
57/ Validation and Early Stopping: Use validation data to monitor training progress and prevent overfitting. Utilize early stopping to halt training when validation performance plateaus or degrades.
58/Ensemble Methods: Combine predictions from multiple models using ensemble techniques like bagging, boosting, or stacking to improve accuracy and robustness.
59/ Attention Mechanisms and Transformers: Experiment with advanced techniques like attention mechanisms and transformers to capture complex relationships in images.
60/ Next thread - Image Classification + Localization:
Image classification involves assigning a label to an entire image, while localization adds the task of localizing the object within the image. This can be achieved by adding a bounding box around the object.
Image classification involves assigning a label to an entire image, while localization adds the task of localizing the object within the image. This can be achieved by adding a bounding box around the object.

• • •
Missing some Tweet in this thread? You can try to
force a refresh