
World Traveler, Sr.SDE,Researcher Cornell Uni,ACM,Competitive Programmer,Google's WTM,Goldman Sachs 10K Women,Coursera Instructor,IITB,Grace hopper,53 countries
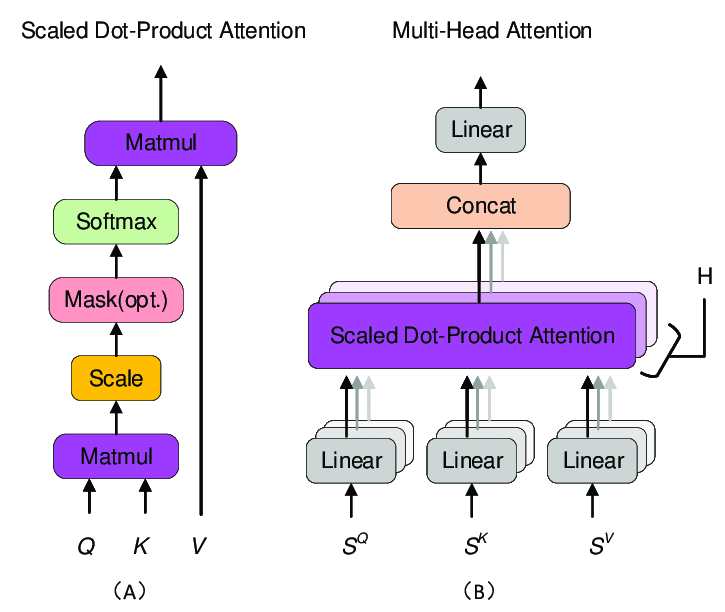 1/ Attention mechanism calculates attention scores between all pairs of tokens in a sequence. These scores are then used to compute weighted representations of each token based on its relationship with other tokens in the sequence.
1/ Attention mechanism calculates attention scores between all pairs of tokens in a sequence. These scores are then used to compute weighted representations of each token based on its relationship with other tokens in the sequence. 
 1/ Regularization is a technique in machine learning used to prevent overfitting by adding a penalty term to the model's loss function. The penalty discourages overly complex models and promotes simpler ones, improving generalization to new, unseen data.
1/ Regularization is a technique in machine learning used to prevent overfitting by adding a penalty term to the model's loss function. The penalty discourages overly complex models and promotes simpler ones, improving generalization to new, unseen data. 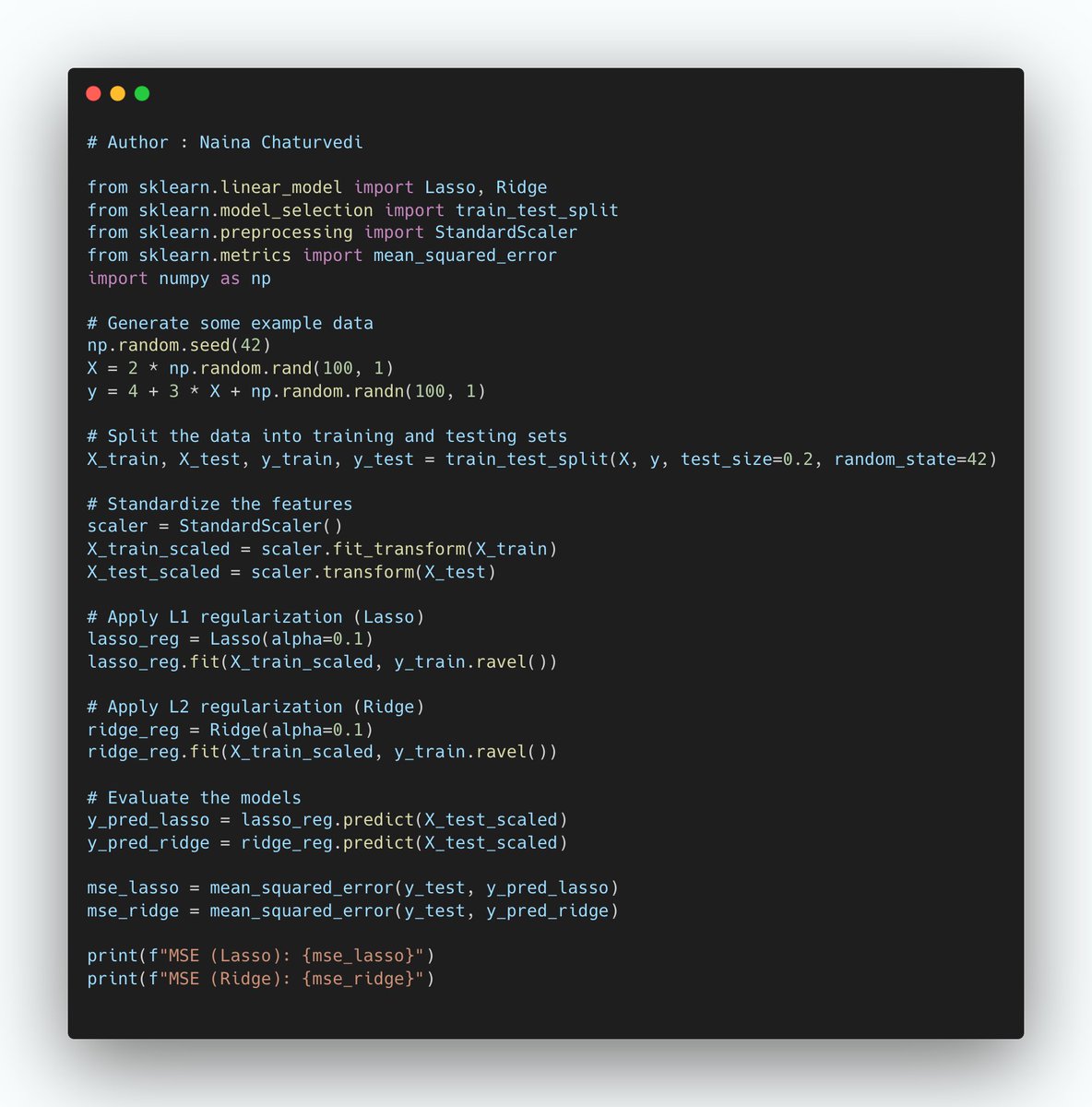
 1/ XGBoost is ensemble learning method that combines multiple decision trees into a strong predictive model. It builds decision trees sequentially, where each tree corrects errors of previous ones. XGBoost optimizes a differentiable loss function to minimize prediction errors.
1/ XGBoost is ensemble learning method that combines multiple decision trees into a strong predictive model. It builds decision trees sequentially, where each tree corrects errors of previous ones. XGBoost optimizes a differentiable loss function to minimize prediction errors. 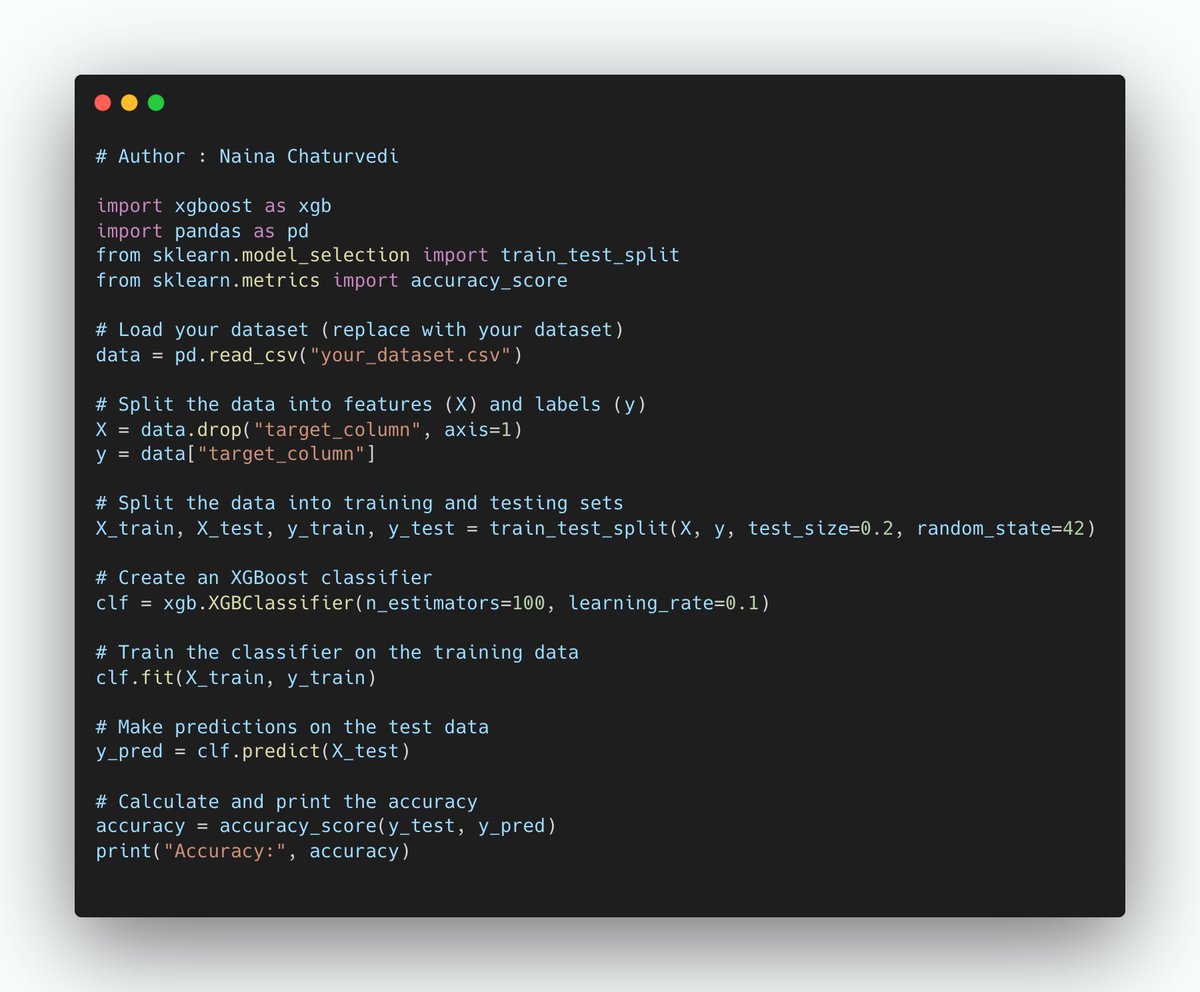
 1/ Gradient Boosting is an ensemble learning method that combines the predictions of multiple weak learners (often decision trees) to create a stronger and more accurate predictive model.
1/ Gradient Boosting is an ensemble learning method that combines the predictions of multiple weak learners (often decision trees) to create a stronger and more accurate predictive model.
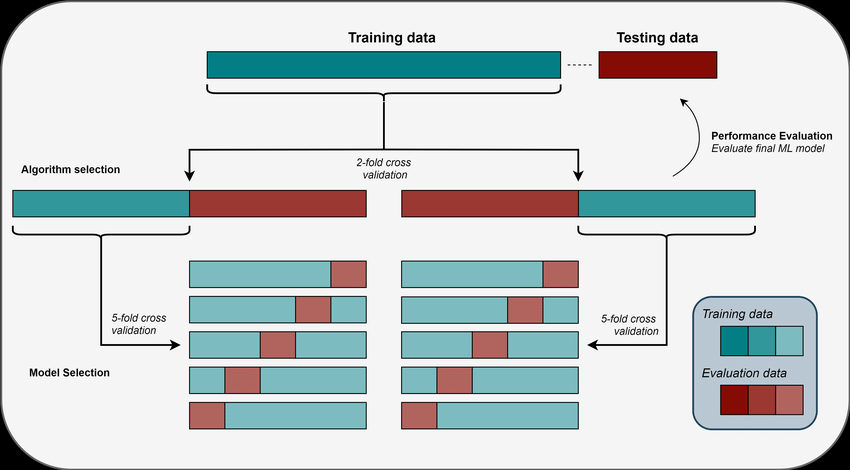 1/ Cross-validation involves splitting the dataset into multiple subsets and using different parts of the data for training and testing at each iteration. The primary goal of cross-validation is to obtain a more robust and unbiased estimate of a model's performance.
1/ Cross-validation involves splitting the dataset into multiple subsets and using different parts of the data for training and testing at each iteration. The primary goal of cross-validation is to obtain a more robust and unbiased estimate of a model's performance. 
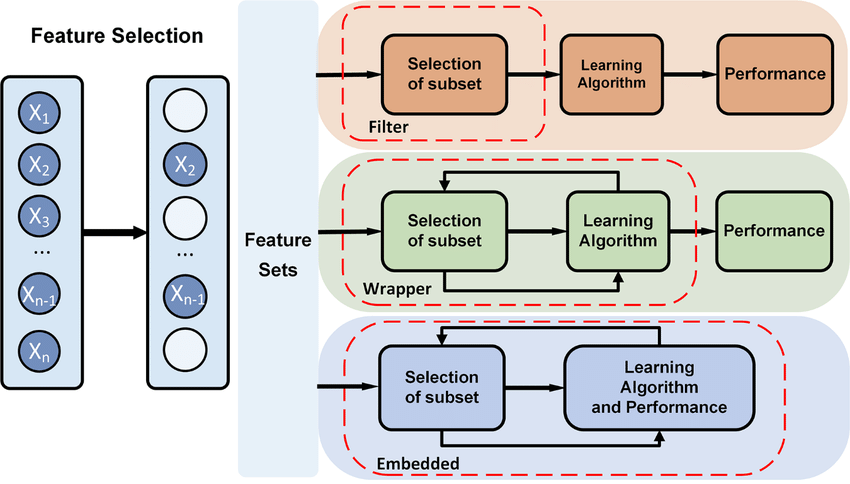 1/ Feature selection is the process of choosing a subset of the most relevant features (variables or columns) from your dataset. It involves excluding less informative or redundant features to improve model performance and reduce computational complexity.
1/ Feature selection is the process of choosing a subset of the most relevant features (variables or columns) from your dataset. It involves excluding less informative or redundant features to improve model performance and reduce computational complexity. 
 1/ Feature engineering is the process of creating new features or modifying existing ones to improve the performance of machine learning models. It involves selecting, transforming, and creating features from the raw data to make it more suitable for model training.
1/ Feature engineering is the process of creating new features or modifying existing ones to improve the performance of machine learning models. It involves selecting, transforming, and creating features from the raw data to make it more suitable for model training. 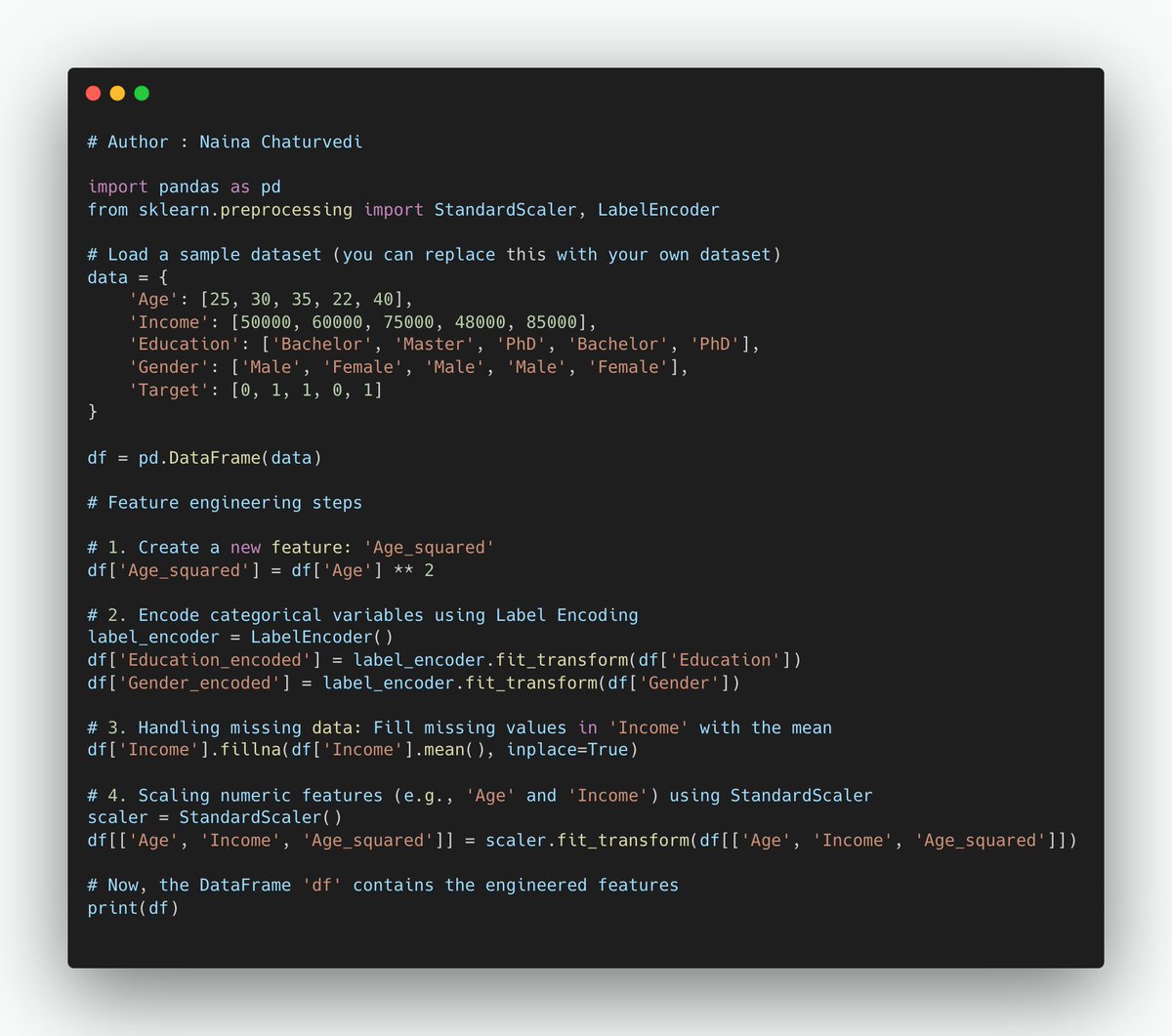
 1/ Linear regression - A simple model that establishes a linear relationship between the input features and the target variable. The basic idea behind linear regression is to find a line or a hyperplane (in the case of multiple linear regression) that best fits the data.
1/ Linear regression - A simple model that establishes a linear relationship between the input features and the target variable. The basic idea behind linear regression is to find a line or a hyperplane (in the case of multiple linear regression) that best fits the data. 
 1/ An optimizer is a mathematical algorithm that is used to adjust the parameters of a machine learning model during training to minimize a specific objective function, typically the loss function.
1/ An optimizer is a mathematical algorithm that is used to adjust the parameters of a machine learning model during training to minimize a specific objective function, typically the loss function. 
 1/ While PCA is effective for linear data, it may not capture complex, nonlinear relationships in the data. Kernel PCA addresses this limitation by mapping the data into a higher-dimensional feature space using a kernel function, where it can capture nonlinear patterns.
1/ While PCA is effective for linear data, it may not capture complex, nonlinear relationships in the data. Kernel PCA addresses this limitation by mapping the data into a higher-dimensional feature space using a kernel function, where it can capture nonlinear patterns. 
 1/ Singular Value Decomposition (SVD) is a linear algebra technique used in ML for data analysis, dimensionality reduction, and matrix factorization. SVD breaks down a matrix into three simpler matrices, providing insights into the structure of the original data.
1/ Singular Value Decomposition (SVD) is a linear algebra technique used in ML for data analysis, dimensionality reduction, and matrix factorization. SVD breaks down a matrix into three simpler matrices, providing insights into the structure of the original data. 
 1/ PCA is a linear transformation method that aims to reduce dimensionality of dataset while preserving as much of original variance. It does this by identifying a new set of uncorrelated variables, called principal components, that are linear combinations of original features.
1/ PCA is a linear transformation method that aims to reduce dimensionality of dataset while preserving as much of original variance. It does this by identifying a new set of uncorrelated variables, called principal components, that are linear combinations of original features. 
 1/ Training is the process of teaching a machine learning model to make predictions or decisions by learning patterns and relationships from a labeled dataset. During training, the model adjusts its internal parameters based on the input data and associated ground truth labels.
1/ Training is the process of teaching a machine learning model to make predictions or decisions by learning patterns and relationships from a labeled dataset. During training, the model adjusts its internal parameters based on the input data and associated ground truth labels. 
 1/ Transfer learning is a technique where a pre-trained model, which has learned to perform a specific task on a large dataset, is adapted for a different but related task.
1/ Transfer learning is a technique where a pre-trained model, which has learned to perform a specific task on a large dataset, is adapted for a different but related task. 
 1/ Gradients refer to the partial derivatives of the loss function with respect to the model's parameters. They indicate how the loss would change if each parameter were adjusted slightly.
1/ Gradients refer to the partial derivatives of the loss function with respect to the model's parameters. They indicate how the loss would change if each parameter were adjusted slightly. 
 1/ Choosing the right model in ML involves the process of selecting an appropriate algorithm that is best suited for a given problem or task. It is a crucial step in ML workflow, and it requires careful consideration of various factors to ensure optimal model performance
1/ Choosing the right model in ML involves the process of selecting an appropriate algorithm that is best suited for a given problem or task. It is a crucial step in ML workflow, and it requires careful consideration of various factors to ensure optimal model performance 
 1/ Bias (Underfitting): Bias represents the error introduced by overly simplistic assumptions in the learning algorithm. A model with high bias pays little attention to the training data and tends to underfit, meaning it cannot capture the underlying patterns in the data.
1/ Bias (Underfitting): Bias represents the error introduced by overly simplistic assumptions in the learning algorithm. A model with high bias pays little attention to the training data and tends to underfit, meaning it cannot capture the underlying patterns in the data. 
 1/ Hyperparameter tuning is like finding the best settings for a special machine that does tasks like coloring pictures or making cookies. You try different combinations of settings to make the machine work its best, just like adjusting ingredients for the tastiest cookies.
1/ Hyperparameter tuning is like finding the best settings for a special machine that does tasks like coloring pictures or making cookies. You try different combinations of settings to make the machine work its best, just like adjusting ingredients for the tastiest cookies.
 1/ It is the process of quantitatively evaluating how well a trained ML model performs on a given task or dataset. It involves using specific metrics and techniques to assess the model's ability to make accurate predictions or decisions.
1/ It is the process of quantitatively evaluating how well a trained ML model performs on a given task or dataset. It involves using specific metrics and techniques to assess the model's ability to make accurate predictions or decisions.
 1/ Dimensionality reduction is like a smart machine that simplifies your big box of colorful building blocks by keeping the important ones and removing the less important ones. This makes it easier to create the picture without losing its essence.
1/ Dimensionality reduction is like a smart machine that simplifies your big box of colorful building blocks by keeping the important ones and removing the less important ones. This makes it easier to create the picture without losing its essence.
 1/ Optimizers: Imagine teaching a computer how to learn from examples. Optimizers are like smart guides that help the computer figure out how to adjust its "thinking knobs" to get better at solving problems. They help the computer learn in small steps.
1/ Optimizers: Imagine teaching a computer how to learn from examples. Optimizers are like smart guides that help the computer figure out how to adjust its "thinking knobs" to get better at solving problems. They help the computer learn in small steps.