
While splitting the raw text for Retrieval Augmented Generation (RAG), what should be the ideal length of each chunk? What’s the sweet spot?
Strike a balance between small vs large chunks using @LangChainAI ParentDocumentRetriever
Let's see how to use it 👇🧵
Strike a balance between small vs large chunks using @LangChainAI ParentDocumentRetriever
Let's see how to use it 👇🧵

The issue:
- smaller chunks reflect more accurate semantic meaning after creating embedding
- but they sometimes might lose the bigger picture and might sound out of context, making it difficult for the LLM to properly answer user's query with limited context per chunk.
- smaller chunks reflect more accurate semantic meaning after creating embedding
- but they sometimes might lose the bigger picture and might sound out of context, making it difficult for the LLM to properly answer user's query with limited context per chunk.
@LangChainAI ParentDocumentRetriever addresses this issue by creating embedding from the smaller chunks only as they capture better semantic meaning.
But while plugging into the LLM input, it uses the larger chunks with better context.
But while plugging into the LLM input, it uses the larger chunks with better context.
Let’s walk through the example code from LangChain’s website on ParentDocumentRetriever 🧑💻 👇
We're gonna need two splitters instead of one.
- One for creating the larger chunks
- Another one for creating the smaller chunks
- One for creating the larger chunks
- Another one for creating the smaller chunks

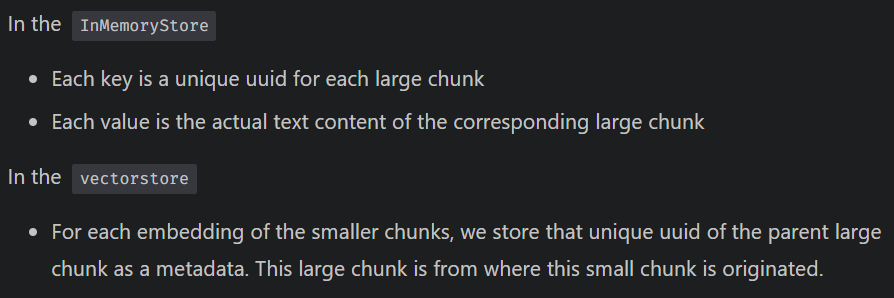
Storing the chunks
- As we're creating embedding for the small chunks only, we'll use a vectorstore to store those.
- Whereas the larger chunks are stored in an InMemoryStore, a KEY-VALUE pair data structure, that stays in the memory while the program is running.
- As we're creating embedding for the small chunks only, we'll use a vectorstore to store those.
- Whereas the larger chunks are stored in an InMemoryStore, a KEY-VALUE pair data structure, that stays in the memory while the program is running.
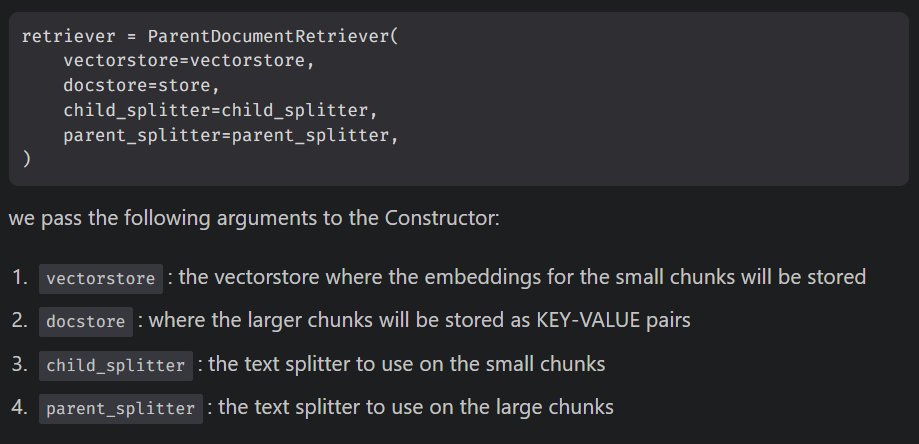
Create the ParentDocumentRetriever object
We pass the vectorstore, docstore, parent and child splitters to the Constructor.
We pass the vectorstore, docstore, parent and child splitters to the Constructor.
Adding the documents using retriever.add_documents() method
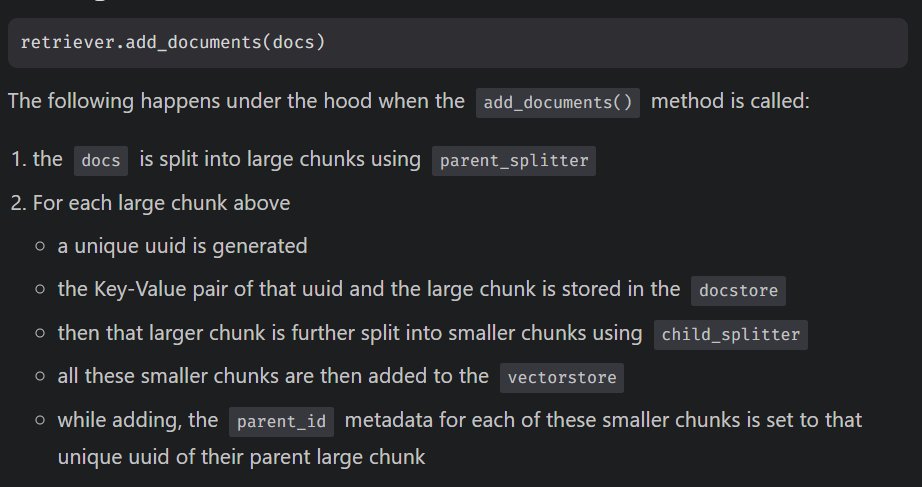
After adding, we can see there are 66 keys in the store. That means 66 large chunks have been added.
Also, if we apply similarity search on the vectorstore itself, we’ll get the small chunks only.
Also, if we apply similarity search on the vectorstore itself, we’ll get the small chunks only.

Now let's use the retriever for retrieving relevant documents using retriever.get_relevant_documents() method

Thus we use small chunks (with better semantic meaning) for vector similarity matching and return their corresponding larger chunks that have the bigger picture and more context.
Hopefully the ParentDocumentRetriever will help you to retrieve better relevant documents while using LangChain for Retrieval Augmented Generation (RAG).
Detailed blog post on ParentDocumentRetriever with more explanation and code snippets
clusteredbytes.pages.dev/posts/2023/lan…
clusteredbytes.pages.dev/posts/2023/lan…
Thanks for reading.
I write about AI, ChatGPT, LangChain etc. and try to make complex topics as easy as possible.
Stay tuned for more ! 🔥 #ChatGPT #LangChain
I write about AI, ChatGPT, LangChain etc. and try to make complex topics as easy as possible.
Stay tuned for more ! 🔥 #ChatGPT #LangChain
https://twitter.com/1355239433432403968/status/1691143792831639556
• • •
Missing some Tweet in this thread? You can try to
force a refresh



