✅Object Localization and tracking in Computer Vision - Explained in simple terms with implementation details (code, techniques and best tips).
Important Computer Vision Series - A quick thread 👇🏻🧵
PC : ResearchGate
Important Computer Vision Series - A quick thread 👇🏻🧵
PC : ResearchGate

1/ Imagine you have a computer, that can look at pictures just like you do. This computer wants to be able to point at things in pictures, like how you point at things you see. But there's a little problem: the computer doesn't know where things are in the pictures!
2/ So, the computer starts to learn. It looks at lots and lots of pictures of different things: animals, cars, toys, and more. It tries to figure out where each thing is in the pictures. To do this, it looks for clues like colors, shapes, and patterns.
3/ After looking at many pictures, the computer starts to get really good at this. Now, when you show it a new picture, it can tell you where the things are by drawing little boxes around them.
4/ And that's how the computer learns to point at things in pictures just like you do! It's can find your toys in a big pile of stuff, but instead, it's finding things in pictures.
5/ Object localization is the task of identifying & precisely delineating location and extent of specific objects or regions of interest within an image. This is typically achieved by predicting a bounding box that encloses target object along with its coordinates within image.

6/ In autonomous driving, object localization helps vehicles detect pedestrians, other vehicles, and traffic signs on the road. This information is vital for making informed decisions and ensuring the safety of passengers and pedestrians.

7/ Object tracking utilizes localization to follow the movement of objects across frames in videos, enabling applications like surveillance and action recognition.

8/ Additionally, in image analysis, object localization allows for efficient processing of specific regions of interest within an image, leading to accurate detection and classification of objects.

9/ The primary goal of object tracking is to maintain the identity of the object(s) over time, even as they move, change appearance, or occlude (partially block) each other.

10/ Types of Object Localization:
Bounding Box Localization:
Objects are defined using rectangular bounding boxes. These boxes enclose the object, and their position is specified by coordinates (top-left and bottom-right corners).
Bounding Box Localization:
Objects are defined using rectangular bounding boxes. These boxes enclose the object, and their position is specified by coordinates (top-left and bottom-right corners).

11/ Semantic Segmentation:
Semantic segmentation involves assigning a class label to each pixel in the image. Instead of using bounding boxes, this method provides a pixel-wise understanding of object locations.
Semantic segmentation involves assigning a class label to each pixel in the image. Instead of using bounding boxes, this method provides a pixel-wise understanding of object locations.

12/ Instance Segmentation:
Instance segmentation goes a step further than semantic segmentation by not only assigning class labels to pixels but also distinguishing individual instances of objects within the same class. This means each instance gets a unique label.
Instance segmentation goes a step further than semantic segmentation by not only assigning class labels to pixels but also distinguishing individual instances of objects within the same class. This means each instance gets a unique label.

13/ Object Localization Techniques:
Sliding Window:
It involves scanning an image with windows of different sizes to detect objects. Imagine moving a rectangular window across the image, checking if content inside the window matches characteristics of object you're looking for.
Sliding Window:
It involves scanning an image with windows of different sizes to detect objects. Imagine moving a rectangular window across the image, checking if content inside the window matches characteristics of object you're looking for.

14/ Template Matching:
It involves comparing a template (a small image representing the object you're looking for) with different regions of the image. The goal is to find areas in the image that closely resemble the template.
It involves comparing a template (a small image representing the object you're looking for) with different regions of the image. The goal is to find areas in the image that closely resemble the template.

15/ Deep Learning Techniques for Object Localization:
Convolutional Neural Networks (CNNs):
These are designed to process grid-like data such as images. They consist of convolutional layers that automatically learn relevant features from input images.
Convolutional Neural Networks (CNNs):
These are designed to process grid-like data such as images. They consist of convolutional layers that automatically learn relevant features from input images.
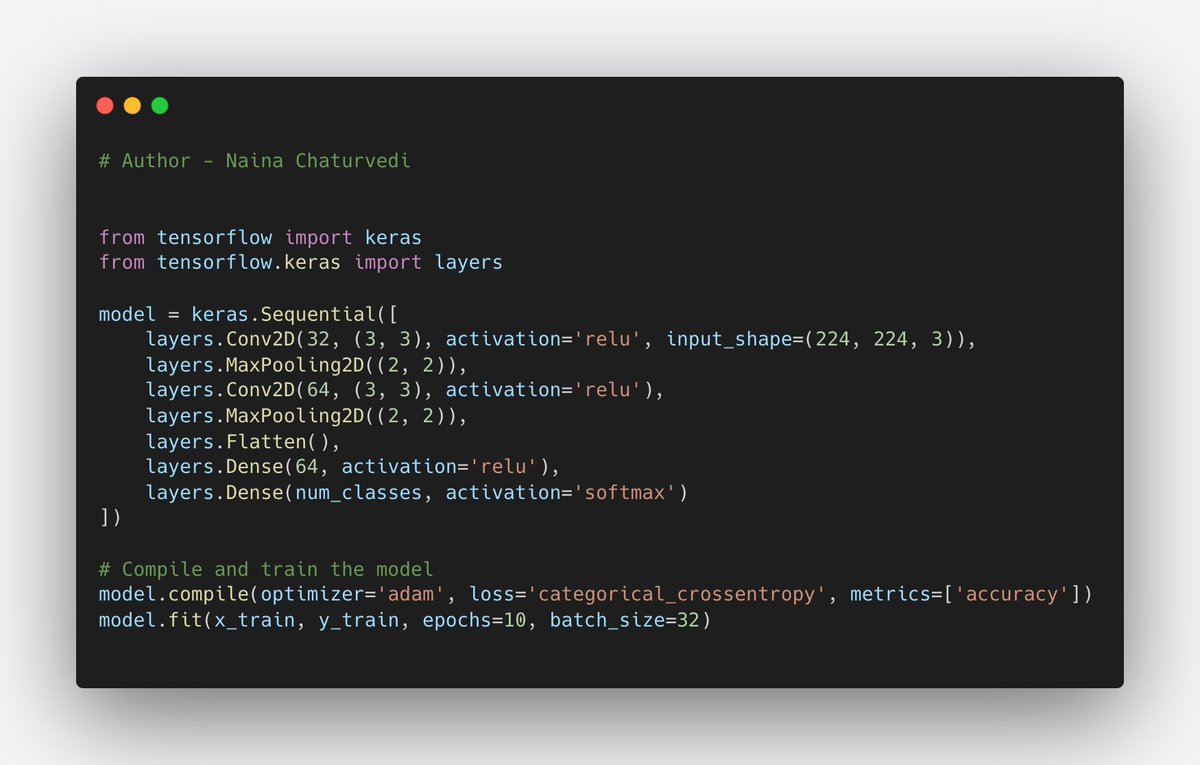
16/ Region-based CNNs (R-CNN, Fast R-CNN, Faster R-CNN):
Uses a region proposal step to select potential object locations before classifying and refining those regions. Faster R-CNN, integrated region proposal networks into detection process, improving both accuracy and speed.
Uses a region proposal step to select potential object locations before classifying and refining those regions. Faster R-CNN, integrated region proposal networks into detection process, improving both accuracy and speed.

17/ Single Shot MultiBox Detector (SSD):
SSD is a real-time object detection model that combines variously sized feature maps to predict objects at different scales. It uses convolutional layers to directly predict object locations and class scores from these feature maps.
SSD is a real-time object detection model that combines variously sized feature maps to predict objects at different scales. It uses convolutional layers to directly predict object locations and class scores from these feature maps.

18/ You Only Look Once (YOLO):
YOLO is a real-time object detection framework that divides the image into grid and predicts bounding boxes and class scores for each grid cell. This approach achieves real-time object detection by making predictions in a single pass over image.
YOLO is a real-time object detection framework that divides the image into grid and predicts bounding boxes and class scores for each grid cell. This approach achieves real-time object detection by making predictions in a single pass over image.

19/ Mask R-CNN:
Mask R-CNN extends Faster R-CNN by adding a segmentation branch. It not only detects objects but also generates pixel-wise masks for each instance of the detected objects, enabling instance-level segmentation along with object detection.
Mask R-CNN extends Faster R-CNN by adding a segmentation branch. It not only detects objects but also generates pixel-wise masks for each instance of the detected objects, enabling instance-level segmentation along with object detection.

20/ Occlusion:
Occlusion occurs when objects are partially obscured by other objects in the scene. This makes it difficult to detect the complete object.
Occlusion occurs when objects are partially obscured by other objects in the scene. This makes it difficult to detect the complete object.

21/ Techniques to handle occlusion include:
Context and Contextual Information: Utilize contextual information to predict occluded object parts based on the visible parts.
Spatial Hierarchies: Employ multi-scale processing to detect objects at different levels of occlusion.
Context and Contextual Information: Utilize contextual information to predict occluded object parts based on the visible parts.
Spatial Hierarchies: Employ multi-scale processing to detect objects at different levels of occlusion.

22/ Scale Variability:
Objects can appear in various sizes due to distance or other factors. Techniques to handle scale variability:
Multi-Scale Processing: Process the image at multiple scales to capture objects of different sizes.
Feature Pyramids: Use feature pyramids.
Objects can appear in various sizes due to distance or other factors. Techniques to handle scale variability:
Multi-Scale Processing: Process the image at multiple scales to capture objects of different sizes.
Feature Pyramids: Use feature pyramids.

23/ Rotation and Viewpoint Variability:
Objects can appear in different orientations or viewpoints. Techniques to handle rotation and viewpoint variability include:
Data Augmentation: Apply random rotations and flips during training to expose the model to various viewpoints.
Objects can appear in different orientations or viewpoints. Techniques to handle rotation and viewpoint variability include:
Data Augmentation: Apply random rotations and flips during training to expose the model to various viewpoints.

24/ Rotation-Invariant Features: Use features that are less affected by rotations, such as Histogram of Oriented Gradients (HOG) or Scale-Invariant Feature Transform (SIFT).

25/Multi-Class Object Detection:
Multi-class object detection involves detecting and classifying objects of multiple classes in an image. Techniques to handle multi-class detection include:
Multi-class object detection involves detecting and classifying objects of multiple classes in an image. Techniques to handle multi-class detection include:

26/Softmax Classification: Use a softmax activation to assign class probabilities to each detected object.
Non-Maximum Suppression: Apply non-maximum suppression to eliminate duplicate detections of the same object instance.
Non-Maximum Suppression: Apply non-maximum suppression to eliminate duplicate detections of the same object instance.

27/ Data Augmentation and Techniques:
Data augmentation involves applying various transformations to the original images to artificially increase the diversity of the training data. This helps models become more robust and perform well on different scenarios.
Data augmentation involves applying various transformations to the original images to artificially increase the diversity of the training data. This helps models become more robust and perform well on different scenarios.

28/ Transfer Learning:
It involves using pretrained models, which have been trained on a large dataset for a specific task (e.g., image classification), and fine-tuning them for object localization tasks (e.g., object detection, instance segmentation).
It involves using pretrained models, which have been trained on a large dataset for a specific task (e.g., image classification), and fine-tuning them for object localization tasks (e.g., object detection, instance segmentation).

29/ ImageNet Pretrained Models: Models pretrained on the ImageNet dataset, which contains millions of labeled images across thousands of classes. These models capture a wide range of image features, making them a common choice for various vision tasks.
30/ COCO Pretrained Models: COCO (Common Objects in Context) is a large-scale dataset that includes object detection, segmentation, and captioning annotations. Pretrained models on COCO are suitable for tasks that require object localization and recognition.

31/ Subscribe and Read more -
Github -
https://t.co/G49RyRwJ4xnaina0405.substack.com
github.com/Coder-World04/…
Github -
https://t.co/G49RyRwJ4xnaina0405.substack.com
github.com/Coder-World04/…
• • •
Missing some Tweet in this thread? You can try to
force a refresh