✅Neural Network Classification- Explained in simple terms with implementation details (code, techniques and best tips).
A quick thread 👇🏻🧵
#MachineLearning #DataScientist #Coding #100DaysofCode #hubofml #deeplearning #DataScience
PC : ResearchGate
A quick thread 👇🏻🧵
#MachineLearning #DataScientist #Coding #100DaysofCode #hubofml #deeplearning #DataScience
PC : ResearchGate

1/ Imagine you have a bunch of colorful building blocks, like LEGO pieces. Each block can be a different color, like red, blue, or green. Now, you want to teach the blocks to sort themselves based on their colors.
2/ A neural network is like game where you teach blocks to sort themselves. It's made up of little parts called "neurons" that work together to learn things. These neurons are like tiny smart blocks. Each neuron looks at color of a block & decides if it's red, blue, or green.
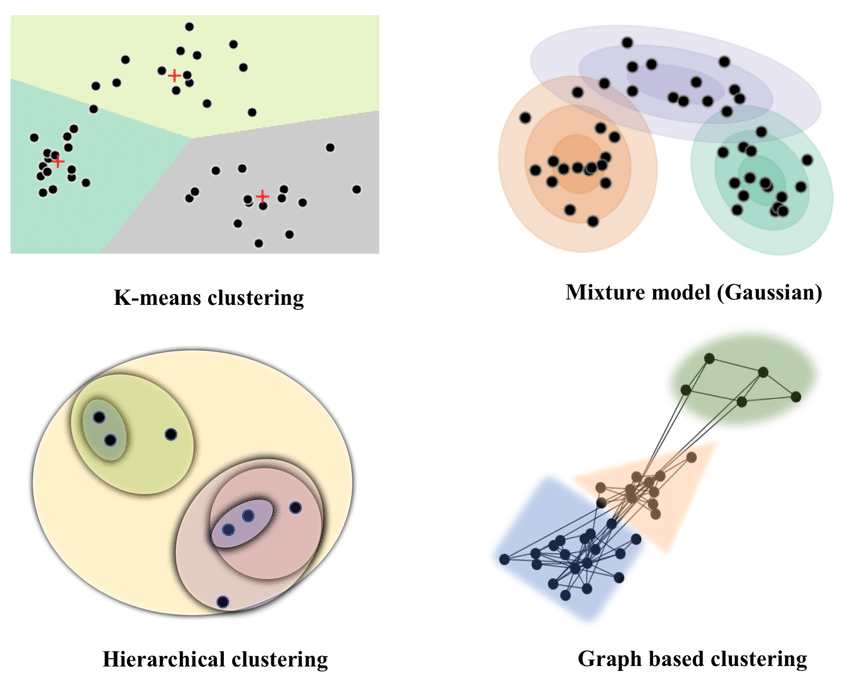
3/Neural network classification is like telling the neurons, "Hey, little smart blocks, I want you to figure out the colors of these blocks and put them into groups." The neurons look at the colors and talk to each other to understand which group each block should go in.
4/So, the neural network helps the blocks learn how to sort themselves just by looking at their colors. And when they're all done, you'll have groups of red, blue, and green blocks neatly sorted.
5/ A neural network is a computational model inspired by the structure and functioning of the human brain. It consists of interconnected nodes, organized into layers. Each node performs simple computations on its input data and passes result to the next layer.
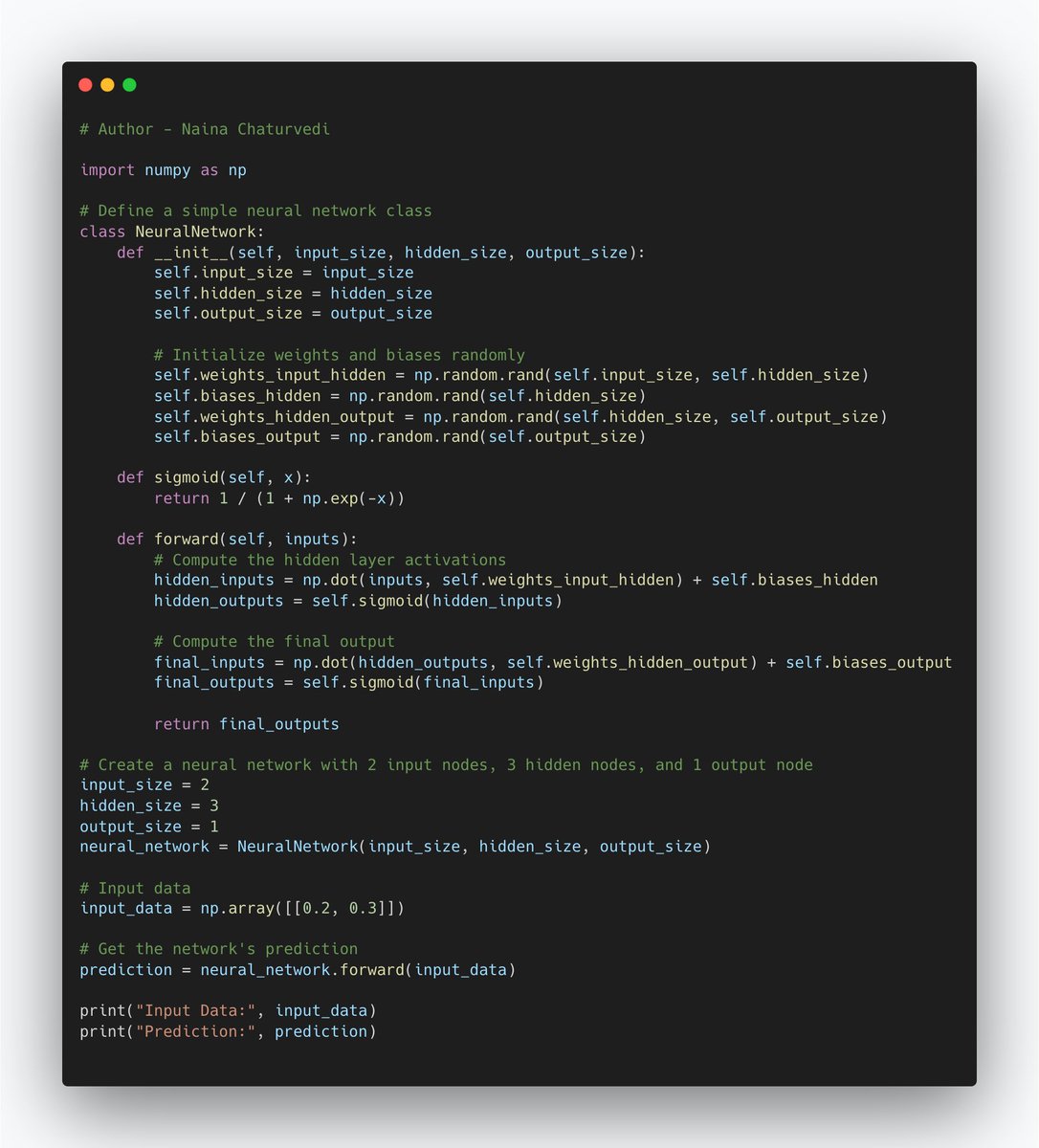
6/ It's a maths function that learns to approximate complex relationships in data by adjusting its parameters during training. It transforms input data through a series of hidden layers, using activation functions to introduce non-linearity, and produces output predictions.
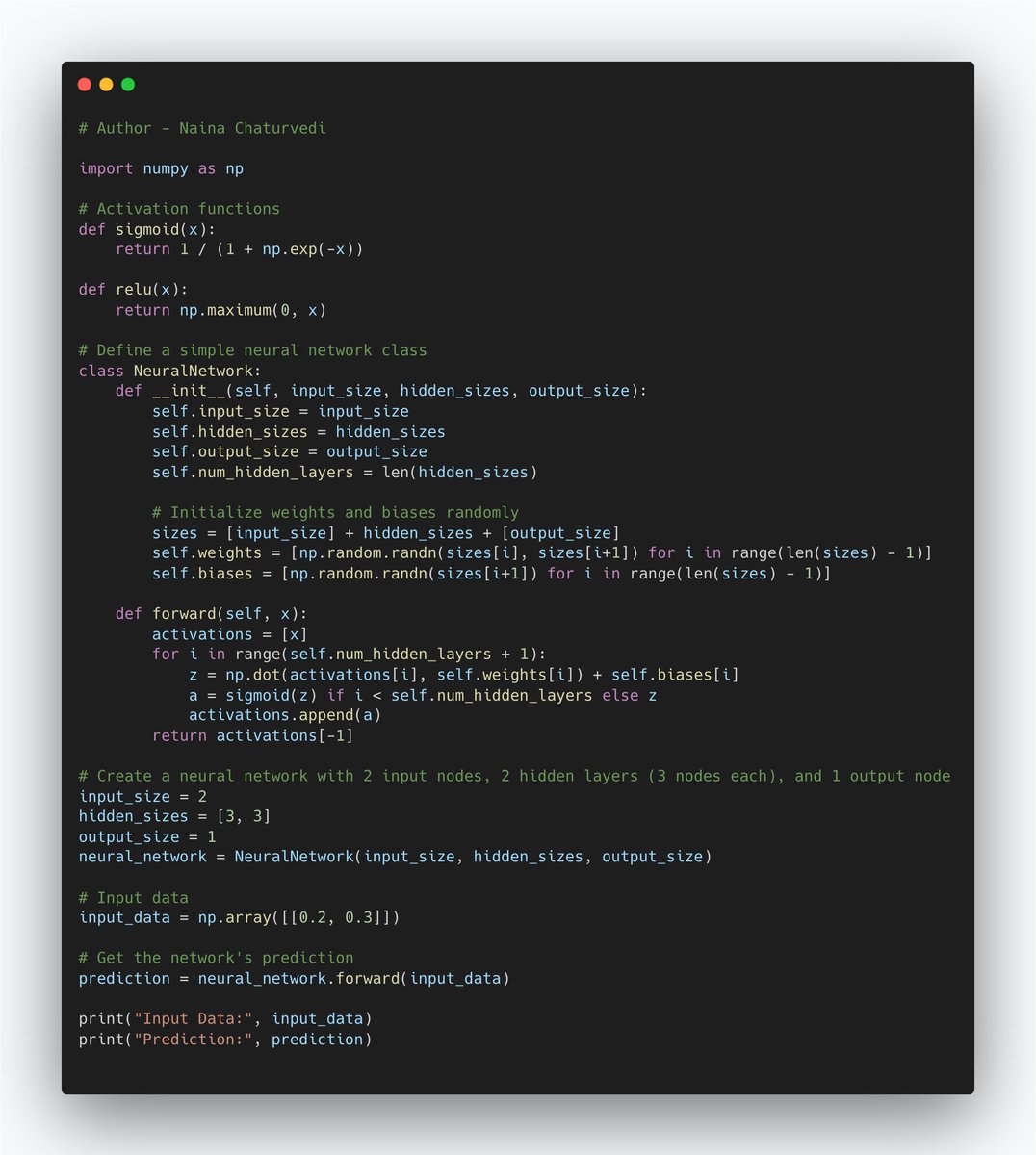
7/ In neural network classification, the input data is passed through the network's layers, with each layer applying linear transformations followed by activation functions.

8/ The network's parameters are learned using optimization algorithms to minimize the difference between predicted and actual class labels. The network's architecture, and activation functions are determined based on complexity of the task and the available data.

9/ Neural Network Architecture:
Neural networks have a specific structure that helps them learn from data and make predictions or classifications. They consist of three main parts: the input layer, hidden layers, and the output layer.
Neural networks have a specific structure that helps them learn from data and make predictions or classifications. They consist of three main parts: the input layer, hidden layers, and the output layer.
10/ Input Layer: This is where the neural network receives its initial information. Each neuron in the input layer represents a feature or piece of data. For example, in an image recognition task, each neuron might represent a pixel's value in the image.
11/Hidden Layers: These are the layers between the input and output layers. These layers do the complex calculations to understand patterns in the data. A neural network can have multiple hidden layers, and each layer contains multiple neurons.
12/Output Layer: This is where the neural network gives its final prediction or classification. Each neuron in the output layer corresponds to a possible outcome. For example, in an animal classification task, each neuron might represent a different animal.
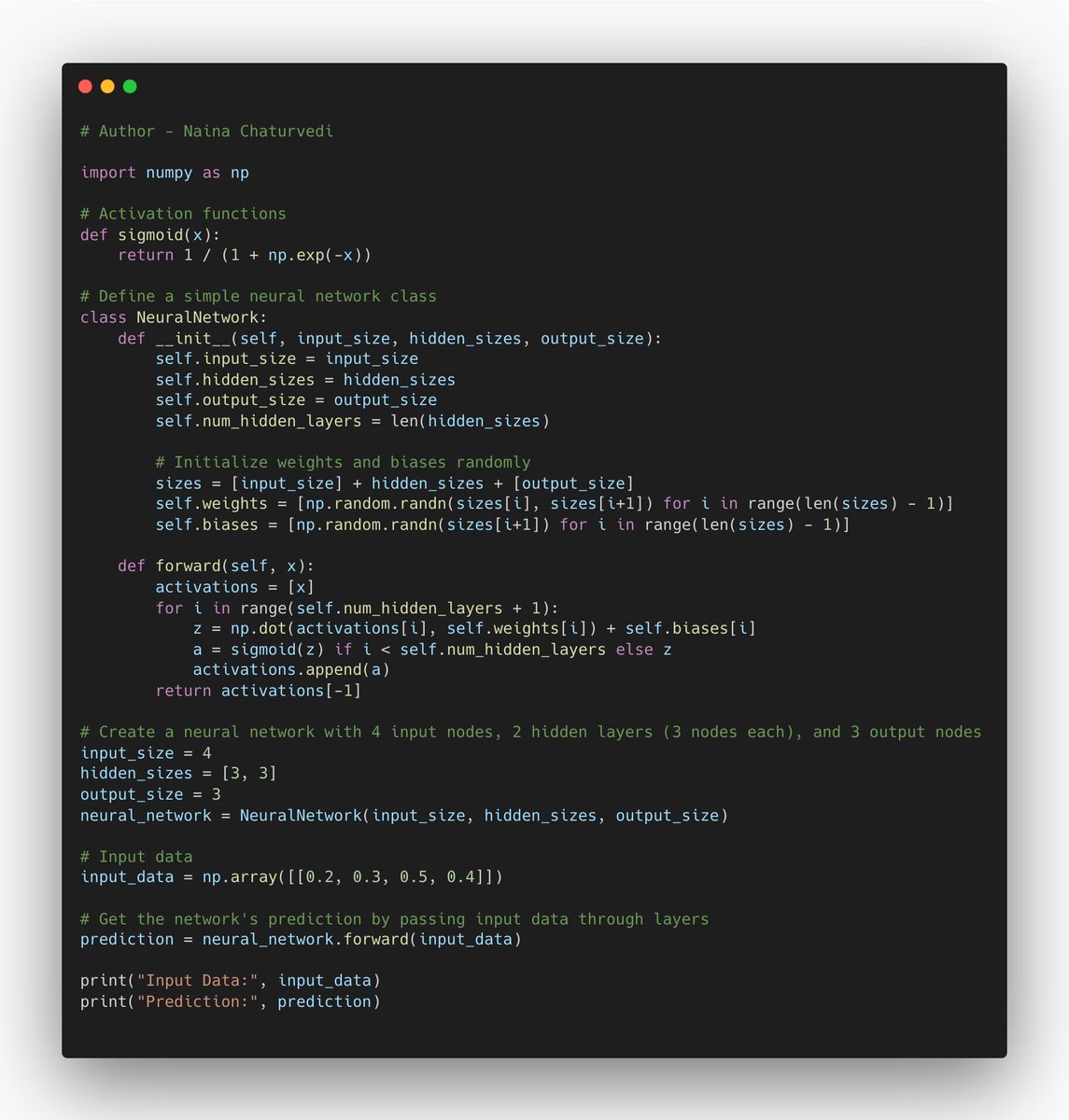
13/ Neurons/Nodes, Weights, and Biases:
Each neuron (or node) in a neural network has two important components: weights and biases.
Weights: Strengths of connections between neurons. When the neural network processes data, it multiplies the input values with weights.
Each neuron (or node) in a neural network has two important components: weights and biases.
Weights: Strengths of connections between neurons. When the neural network processes data, it multiplies the input values with weights.

14/Biases: Biases are like a neuron's own opinion. They're added to the weighted inputs before passing through an activation function. Biases help shift the output of a neuron up or down, making sure the network can learn more complex relationships in data.
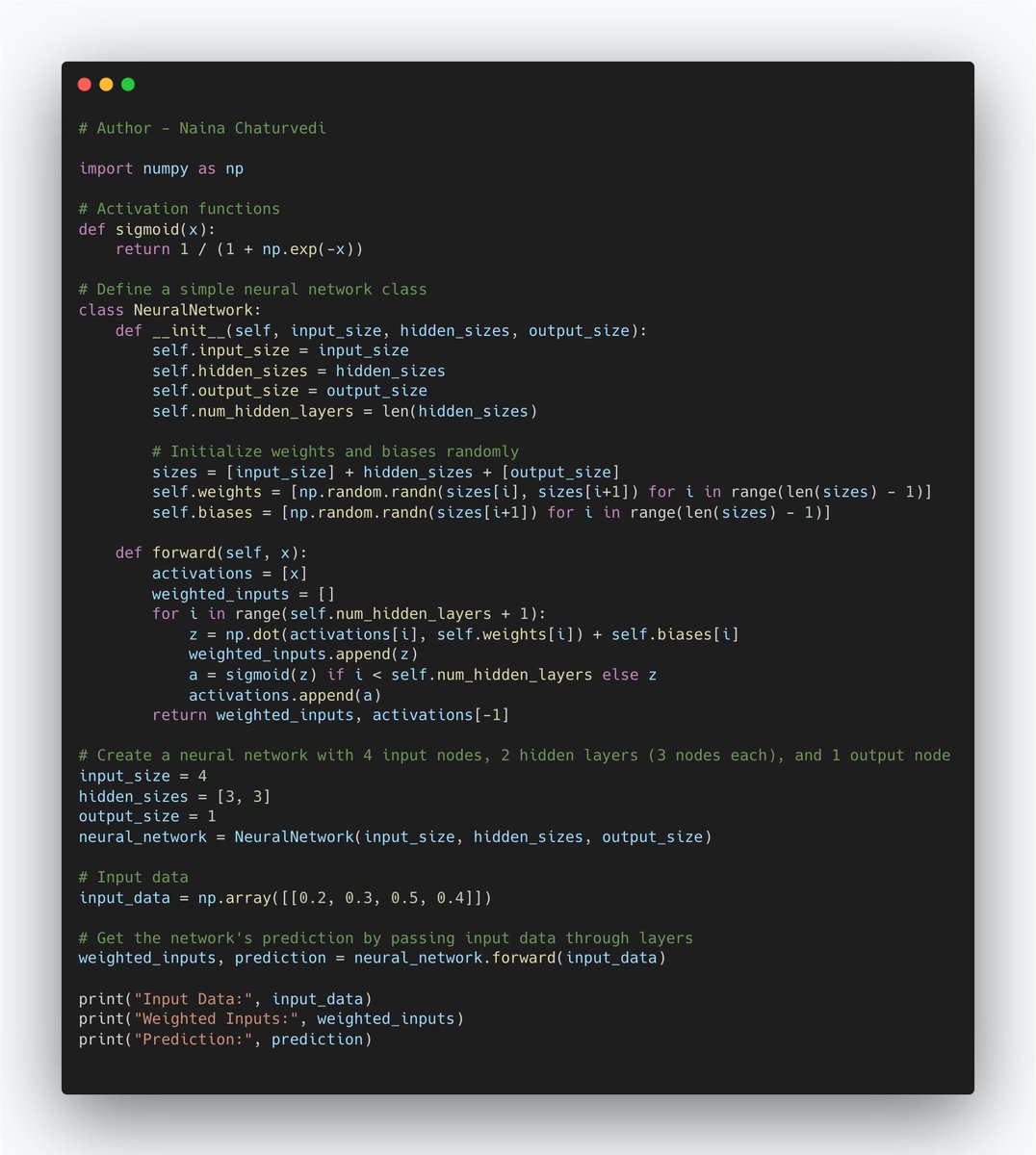
15/ Activation Functions:
Activation functions introduces non-linearity. In simple terms, they determine whether a neuron "fires" based on the input it receives. Activation functions help the network learn and model complex relationships in data that might not be linear.
Activation functions introduces non-linearity. In simple terms, they determine whether a neuron "fires" based on the input it receives. Activation functions help the network learn and model complex relationships in data that might not be linear.

16/Sigmoid Function: The sigmoid function squashes its input into a range between 0 and 1. It's often used in the output layer for binary classification problems, where the network predicts a probability between 0 (definitely not) and 1 (definitely yes).
17/ReLU (Rectified Linear Unit): ReLU is the most commonly used activation function. It turns all negative inputs into zero and keeps positive inputs unchanged. This simple behavior helps the network learn faster and overcome the vanishing gradient problem.
18/Tanh (Hyperbolic Tangent): Tanh is similar to the sigmoid function but maps inputs to a range between -1 and 1. It's often used in hidden layers and can be helpful for capturing more complex patterns in data.

19/ Importance of Activation Functions:
Activation functions are crucial for neural networks to model complex relationships in data. Without them, neural networks would behave like linear models, limiting their ability to learn intricate patterns.
Activation functions are crucial for neural networks to model complex relationships in data. Without them, neural networks would behave like linear models, limiting their ability to learn intricate patterns.
20/ Feedforward Process:
The feedforward process is how a neural network transforms inputs into predictions.
Input Layer: The process begins with the input layer, where the network receives the initial data. Each neuron in this layer represents a feature or input value.
The feedforward process is how a neural network transforms inputs into predictions.
Input Layer: The process begins with the input layer, where the network receives the initial data. Each neuron in this layer represents a feature or input value.
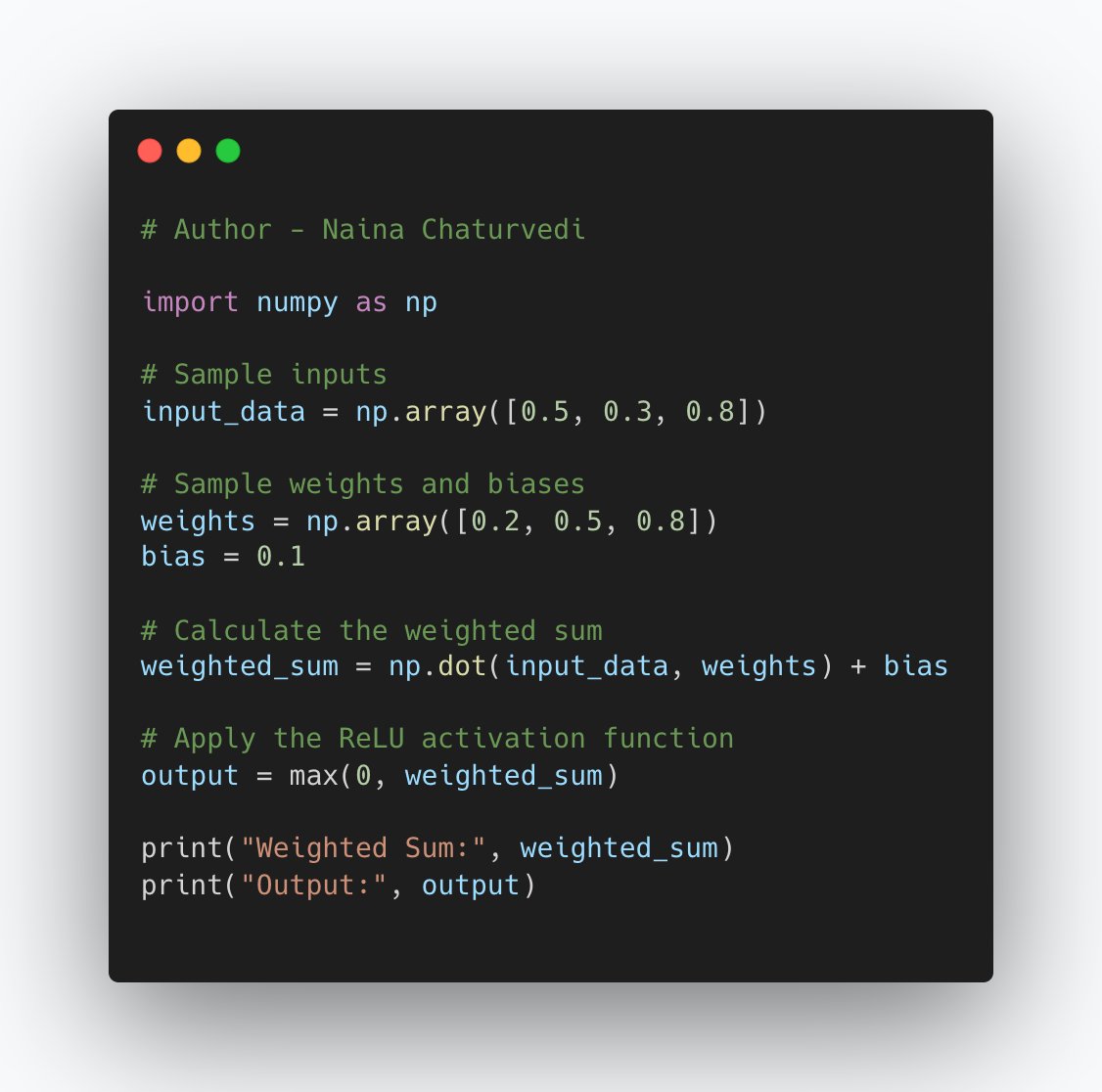
21/ Weighted Sum: Each input neuron is connected to neurons in the next layer with weights. Think of weights as how much importance is given to each input. The network multiplies each input by its weight and adds them up, creating a weighted sum.
22/Bias: Before moving on, a bias is added to the weighted sum. Bias is like an extra ingredient that helps the network adjust the output.
23/Activation Function: The weighted sum with the bias is then passed through an activation function. This function introduces non-linearity, making network more powerful. Activation functions like ReLU, sigmoid, or tanh determine whether the neuron "fires" based on its input.
24/ Hidden Layers: The process repeats for the hidden layers. Each hidden layer's neurons take the outputs of the previous layer as inputs, and the process of weighted sum, bias, and activation function happens again.

25/ Backpropagation:
Backpropagation is like a feedback mechanism that helps a NN learn from its mistakes. Just as we learn by realizing our errors and adjusting our approach, NN uses backpropagation to adjust its weights and biases, making its predictions more accurate.
Backpropagation is like a feedback mechanism that helps a NN learn from its mistakes. Just as we learn by realizing our errors and adjusting our approach, NN uses backpropagation to adjust its weights and biases, making its predictions more accurate.
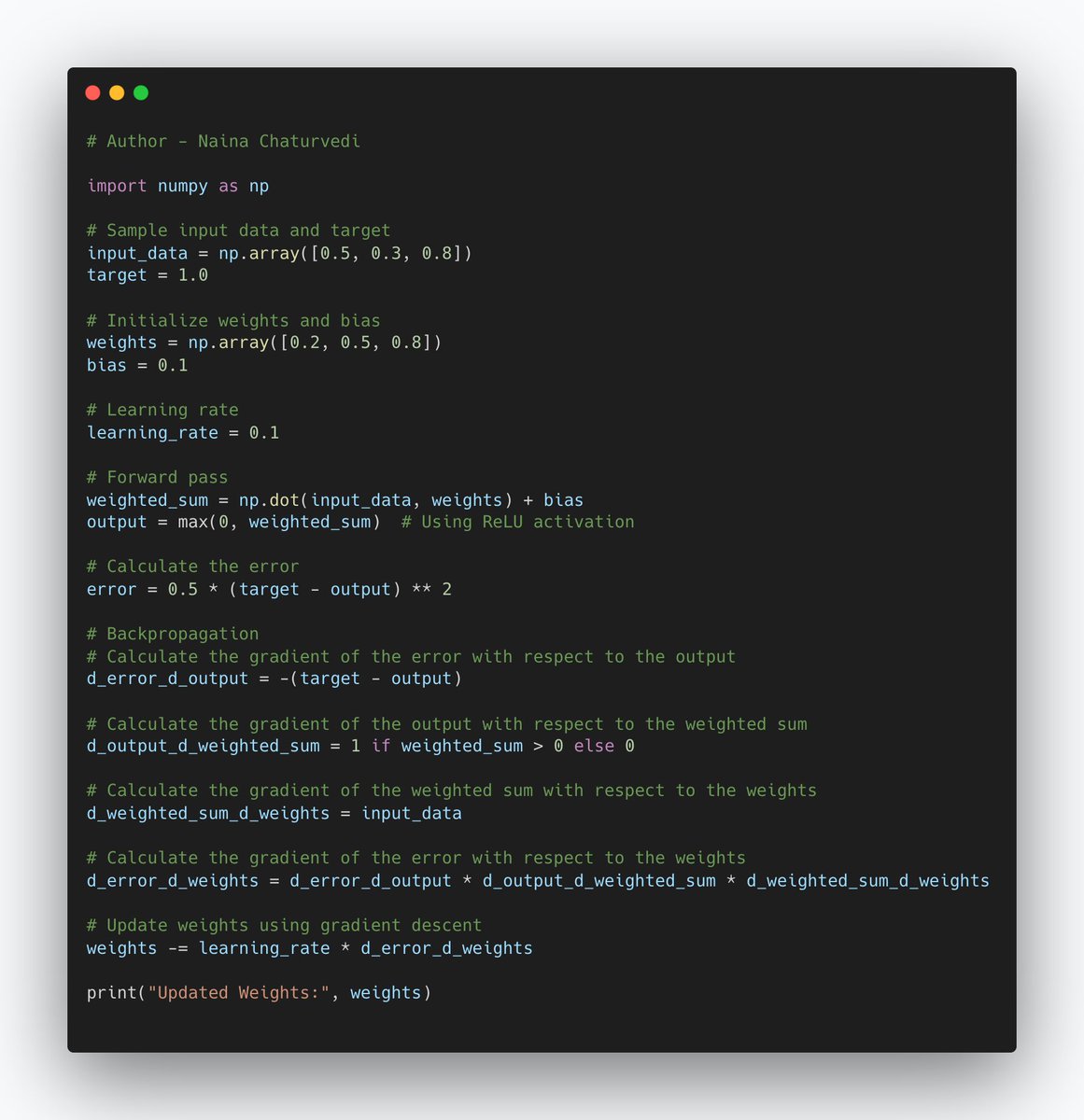
26/Forward Pass: First, during the feedforward process, the network makes predictions. It calculates the output for a given input using the current weights and biases.
27/Calculate Error: Next, the network calculates how far off its predictions are from the actual target values. This difference is called the error or loss.
28/Backward Pass: The magic of backpropagation happens here. The network goes backward through its layers, figuring out how much each weight and bias contributed to the error. This is like tracing back our steps to see which parts of our actions caused a mistake.
29/Gradient Descent: The network uses these error contributions to adjust its weights and biases. It tweaks them in a way that reduces the error. This is called gradient descent. It's like fine-tuning a recipe after realizing what went wrong.
30/Update Weights and Biases: The updated weights and biases make the network's predictions better aligned with the targets. The network repeats this process for many examples, iteratively improving its performance.
31/ Learning Rate: There's also a learning rate involved. It's like how much you adjust your actions based on the size of your mistakes. Too big a step can lead you astray, but too small a step can take forever to get you where you want.
32/ Gradient Descent:
It's optimization algorithm used in training NN. It's like finding the fastest way downhill by taking small steps in the steepest direction. In the context of neural networks, the "hill" represents the error or loss, and we want to minimize it.
It's optimization algorithm used in training NN. It's like finding the fastest way downhill by taking small steps in the steepest direction. In the context of neural networks, the "hill" represents the error or loss, and we want to minimize it.
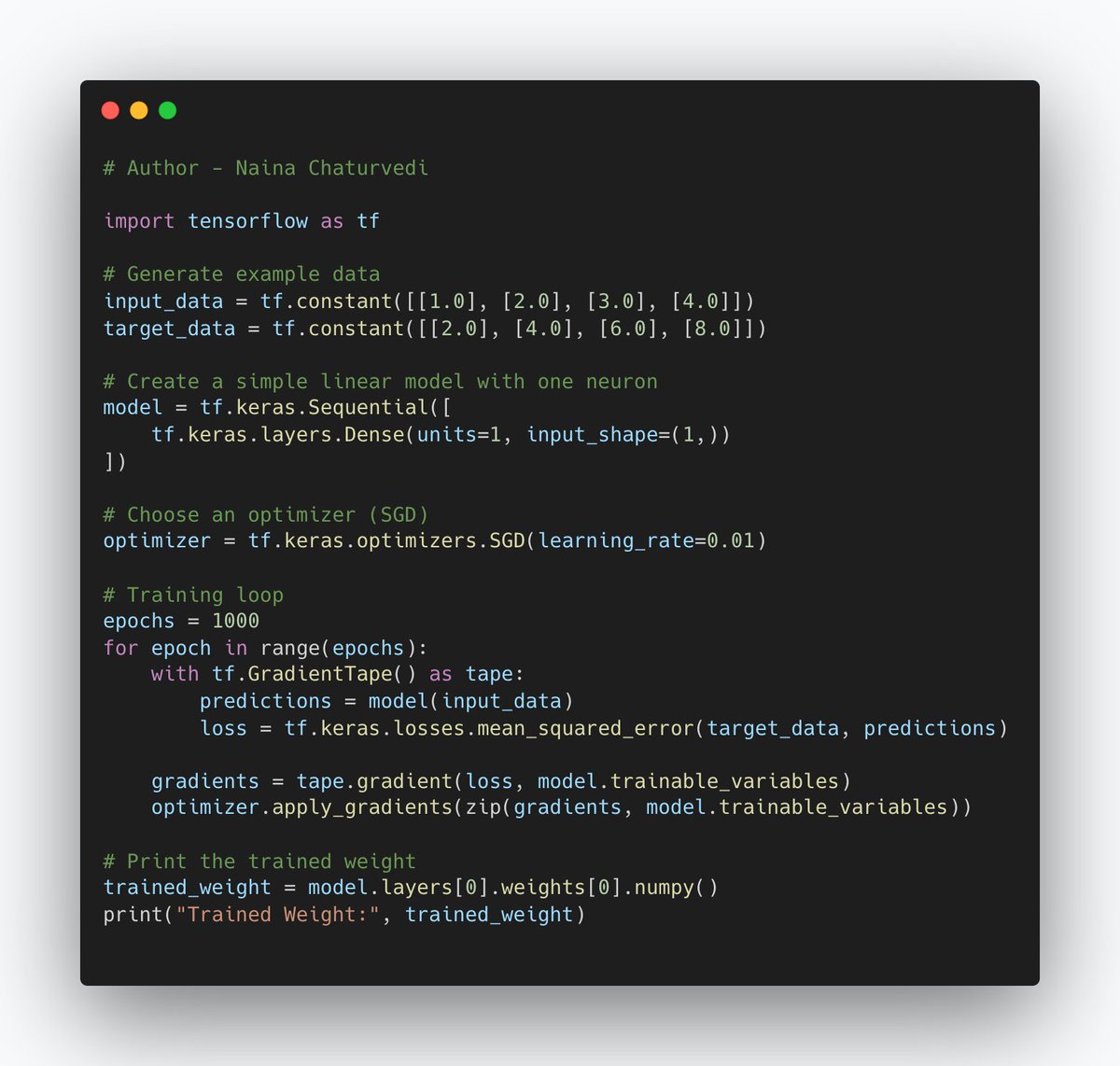
33/ Calculate Gradients: During backpropagation, the network calculates gradients, which show the direction and magnitude of the change needed in each parameter to reduce the error.
34/Update Parameters: Gradient descent starts by initializing the parameters randomly. Then, it updates them by subtracting a portion of the gradients (scaled by a learning rate). This process nudges the parameters towards values that reduce the error.
35/Learning Rate: The learning rate determines how big the steps are. Too large a learning rate might overshoot the minimum, and too small a rate might take a long time to reach it.
36/Types of Gradient Descent: Stochastic Gradient Descent (SGD): Instead of using the entire dataset to calculate gradients, SGD randomly picks a small batch of data for each step. This speeds up the process and makes the learning less noisy.
37/ Adam (Adaptive Moment Estimation): Adam is an advanced optimization algorithm that adjusts the learning rate for each parameter. It combines the ideas of both momentum and adaptive learning rates, making it very efficient and effective in many cases.
38/ Overfitting: Overfitting happens when a neural network learns the training data so well that it starts to memorize it, rather than learning the general patterns. It's like a student who memorizes answers for specific questions but struggles when faced with new questions.
39/ Regularization: Regularization techniques help prevent overfitting by adding constraints to the network's parameters. They encourage the network to find simpler patterns that generalize better to new data.
40/L2 Regularization (Weight Decay): L2 regularization adds a penalty term to the loss function based on the magnitude of weights. It discourages the weights from becoming too large, which helps prevent the network from relying heavily on a few input features.
41/ Dropout: Dropout randomly turns off a certain percentage of neurons during training. This prevents any single neuron from becoming too important and encourages the network to learn more robust and diverse features.
42/ Binary Classification and Multiclass Classification:
Binary Classification:Binary classification is a type of classification task where the goal is to categorize input data into one of two possible classes. It's like sorting things into two different boxes.
Binary Classification:Binary classification is a type of classification task where the goal is to categorize input data into one of two possible classes. It's like sorting things into two different boxes.
43/Multiclass Classification: It involves categorizing input data into more than two classes. It's like sorting things into multiple boxes, where each box represents a different category. For example, you could classify animals into categories like cats, dogs, birds, and fish.
44/ Softmax Activation:
It converts the raw scores (also called logits) produced by the previous layers into probabilities that represent the likelihood of each class being the correct one.
It converts the raw scores (also called logits) produced by the previous layers into probabilities that represent the likelihood of each class being the correct one.
45/ Calculating Exponentials: The softmax function takes the exponentials of each score. Exponentials make sure all the scores are positive.
Normalization: The exponentials are then divided by their sum. This step makes the scores add up to 1, just like probabilities should.
Normalization: The exponentials are then divided by their sum. This step makes the scores add up to 1, just like probabilities should.
• • •
Missing some Tweet in this thread? You can try to
force a refresh