Number Needed to Treat (NNT) & Number Needed to Harm (NNH) in Clinical Trials Explained in Plain English 📊🩺
1/ When evaluating a new treatment, two key numbers often come up: Number Needed to Treat (NNT) and Number Needed to Harm (NNH). Let's demystify these in simple terms.
2/ 🎯 Number Needed to Treat (NNT):
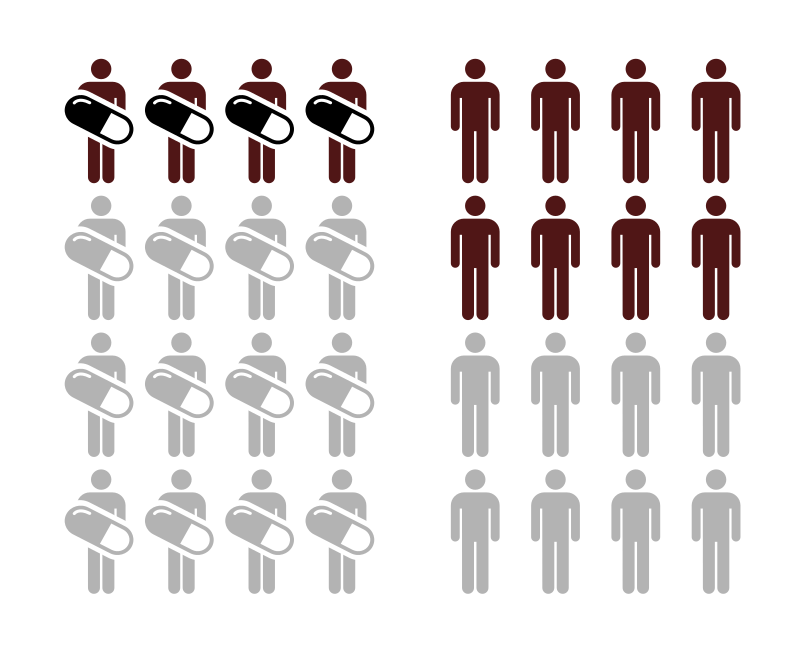
Imagine 100 people with a headache. If 80 get better with a new pill and 70 get better without it, then 10 benefitted from the pill. So, you'd need to treat 10 people for 1 to benefit. That's an NNT of 10.
3/ A lower NNT is generally better. If a drug has an NNT of 2, it means for every 2 people treated, 1 benefits. If it's 50, you'd have to treat 50 people for 1 to see a benefit. The smaller the number, the more effective the treatment.
4/ 🔥 Number Needed to Harm (NNH):
Now, let's say out of 100 people, 5 have a side effect from the pill. That means, for every 20 people treated, 1 person experiences harm. That's an NNH of 20.
5/ A higher NNH is preferred. If a drug has an NNH of 100, it means 1 out of 100 people treated might experience harm. If it's 10, then 1 out of every 10 might be harmed. The bigger the number, the safer the treatment (in terms of that specific harm).
6/ It's a balance! Healthcare professionals look at both NNT and NNH to decide if a treatment's benefits outweigh the risks. A drug might have an NNT of 5 (good) but an NNH of 6 (risky). So, while it's effective, there's also a notable risk.
7/ Real-world example: Aspirin can be recommended to prevent heart attacks. The NNT tells us how many need to take it to prevent one heart attack. But it can also cause bleeding, so the NNH tells us how many might take it before one person is harmed.
8/ When hearing about a new treatment, asking about NNT & NNH can give you a clearer picture. It's not just about "Does it work?" but also "How often does it work?" and "What's the risk?"
9/ In conclusion, NNT & NNH are tools to help understand the impact of treatments. They help us make informed choices, balancing benefits against potential harms.
10/ So next time you're discussing treatments, remember these numbers. They help simplify complex decisions, bringing clarity to the choices we make in healthcare.
If you found this post useful, please give it a ❤️ or 🔁. Sharing knowledge empowers everyone to make informed health decisions. Stay curious!
#DataScience #Statistics
1/ When evaluating a new treatment, two key numbers often come up: Number Needed to Treat (NNT) and Number Needed to Harm (NNH). Let's demystify these in simple terms.
2/ 🎯 Number Needed to Treat (NNT):
Imagine 100 people with a headache. If 80 get better with a new pill and 70 get better without it, then 10 benefitted from the pill. So, you'd need to treat 10 people for 1 to benefit. That's an NNT of 10.
3/ A lower NNT is generally better. If a drug has an NNT of 2, it means for every 2 people treated, 1 benefits. If it's 50, you'd have to treat 50 people for 1 to see a benefit. The smaller the number, the more effective the treatment.
4/ 🔥 Number Needed to Harm (NNH):
Now, let's say out of 100 people, 5 have a side effect from the pill. That means, for every 20 people treated, 1 person experiences harm. That's an NNH of 20.
5/ A higher NNH is preferred. If a drug has an NNH of 100, it means 1 out of 100 people treated might experience harm. If it's 10, then 1 out of every 10 might be harmed. The bigger the number, the safer the treatment (in terms of that specific harm).
6/ It's a balance! Healthcare professionals look at both NNT and NNH to decide if a treatment's benefits outweigh the risks. A drug might have an NNT of 5 (good) but an NNH of 6 (risky). So, while it's effective, there's also a notable risk.
7/ Real-world example: Aspirin can be recommended to prevent heart attacks. The NNT tells us how many need to take it to prevent one heart attack. But it can also cause bleeding, so the NNH tells us how many might take it before one person is harmed.
8/ When hearing about a new treatment, asking about NNT & NNH can give you a clearer picture. It's not just about "Does it work?" but also "How often does it work?" and "What's the risk?"
9/ In conclusion, NNT & NNH are tools to help understand the impact of treatments. They help us make informed choices, balancing benefits against potential harms.
10/ So next time you're discussing treatments, remember these numbers. They help simplify complex decisions, bringing clarity to the choices we make in healthcare.
If you found this post useful, please give it a ❤️ or 🔁. Sharing knowledge empowers everyone to make informed health decisions. Stay curious!
#DataScience #Statistics

• • •
Missing some Tweet in this thread? You can try to
force a refresh