
Passionate about data | Building tools to simplify complex problems | Founder of https://t.co/2dhtzQzC3u
 2/10 We developed bioLeak to address a specific gap: the lack of systematic, post-hoc integrity checks for R-based machine learning.
2/10 We developed bioLeak to address a specific gap: the lack of systematic, post-hoc integrity checks for R-based machine learning. Examples:
Examples: Fixed Effects:
Fixed Effects: Implications of Heteroscedasticity in Regression Analysis
Implications of Heteroscedasticity in Regression Analysis Imagine a prize behind 1 of 3 doors. If you open 2 doors and find no prize, the 3rd door is fixed. Here, you have 2 degrees of freedom.
Imagine a prize behind 1 of 3 doors. If you open 2 doors and find no prize, the 3rd door is fixed. Here, you have 2 degrees of freedom. 
 A CI is a range of values, derived from sample data, that likely contains the true population parameter. It provides a measure of uncertainty around an estimate, indicating the precision of the data.
A CI is a range of values, derived from sample data, that likely contains the true population parameter. It provides a measure of uncertainty around an estimate, indicating the precision of the data. 
 1/ 🧐 Topic: Probability
1/ 🧐 Topic: Probability 📍PCA:
📍PCA: 2/ Both Logit & Probit models are stalwarts in statistics when modeling binary dependent variables. But what sets them apart? The devil's in the details.📊 #DataScience
2/ Both Logit & Probit models are stalwarts in statistics when modeling binary dependent variables. But what sets them apart? The devil's in the details.📊 #DataScience
 2/ Origin & History:
2/ Origin & History: 2/ Useful? Definitely! R^2 gives us an idea of how well our model explains the variance in the data. Higher values suggest the model explains a lot of the variation; however, it's not the sole criterion for a "good" model.
2/ Useful? Definitely! R^2 gives us an idea of how well our model explains the variance in the data. Higher values suggest the model explains a lot of the variation; however, it's not the sole criterion for a "good" model.
 2/8 📊 Covariance
2/8 📊 Covariance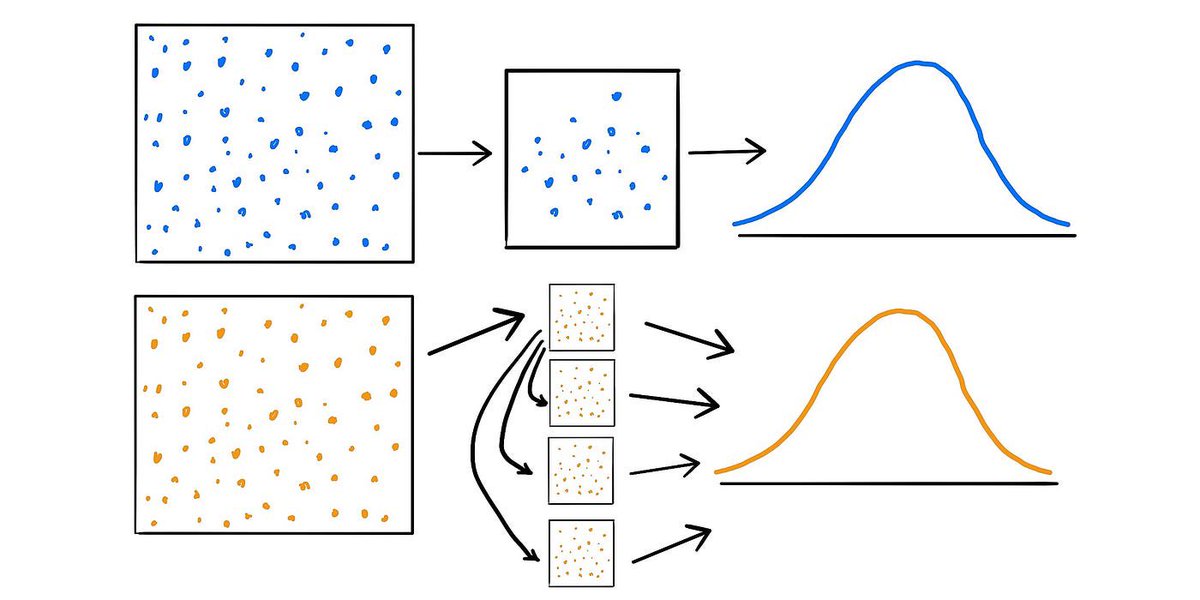 2/ 🥾 What's bootstrapping? It's a resampling technique where you take many subsamples from your sample data & analyze them. The idea? The subsamples give us an insight into the variability in our sample.
2/ 🥾 What's bootstrapping? It's a resampling technique where you take many subsamples from your sample data & analyze them. The idea? The subsamples give us an insight into the variability in our sample.
 2/ Confidence Interval (CI) 📉
2/ Confidence Interval (CI) 📉 2/ Historical Context:
2/ Historical Context: 2/10 🖼️ The Canvas:
2/10 🖼️ The Canvas: 2/15 R is a powerful language for data manipulation, analysis and visualization. To elevate your skills, start by understanding the language at its core. This includes the syntax, data types, vectors, matrices, lists, and data frames. #RStats
2/15 R is a powerful language for data manipulation, analysis and visualization. To elevate your skills, start by understanding the language at its core. This includes the syntax, data types, vectors, matrices, lists, and data frames. #RStats