✅Convolutional Neural Network - Explained in simple terms with implementation details (code, techniques and best tips).
A quick thread 👇🏻🧵
#MachineLearning #DataScientist #Coding #100DaysofCode #hubofml #deeplearning #DataScience
PC : ResearchGate
A quick thread 👇🏻🧵
#MachineLearning #DataScientist #Coding #100DaysofCode #hubofml #deeplearning #DataScience
PC : ResearchGate

1/ Imagine you have a picture, like a puzzle made of tiny colored pieces. A Convolutional Neural Network (CNN) is like a special brain that can look at the puzzle pieces in different ways to figure out what's in the picture. It's really good at finding patterns.
2/The CNN works by sliding a small window over the puzzle pieces. This window is like a magnifying glass that looks at a small group of pieces at a time. It takes these pieces and finds out what features they have, like colors and shapes.
3/ As the window moves across the puzzle, CNN keeps learning more and more about picture's details. Then, the CNN puts all this information together and decides what picture is showing. This way, it can tell us what's in picture without even needing to see whole thing at once.
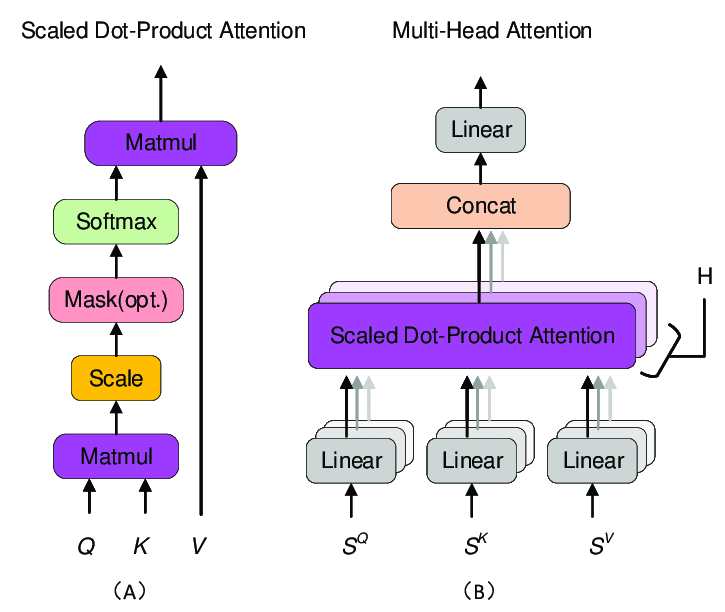
4/ A Convolutional Neural Network (CNN) is a class of deep neural networks primarily designed to process and analyze grid-like data, such as images and videos. CNNs are particularly well-suited for tasks involving pattern recognition and feature extraction from visual data.

5/ Layers: A CNN consists of multiple layers that perform different tasks. The key layers are:
Convolutional Layer: This is where the filters slide over the image to detect patterns.
Convolutional Layer: This is where the filters slide over the image to detect patterns.
6/ Pooling Layer: This layer reduces dimensions of the image, making network faster and more efficient. It helps retain important features.
Fully Connected Layer: This layer connects the features learned by the previous layers to make final decisions about what's in the image.
Fully Connected Layer: This layer connects the features learned by the previous layers to make final decisions about what's in the image.

7/ Convolution and Feature Extraction:
Convolutional layers in CNNs are responsible for detecting local patterns and features in images. They use filters to slide over the input image and perform a mathematical operation called convolution.
Convolutional layers in CNNs are responsible for detecting local patterns and features in images. They use filters to slide over the input image and perform a mathematical operation called convolution.

8/ Filters in convolutional layers learn to recognize various features like edges, textures, and more complex patterns. During training, CNNs adjust the filter weights so that they become sensitive to specific patterns in the input images.
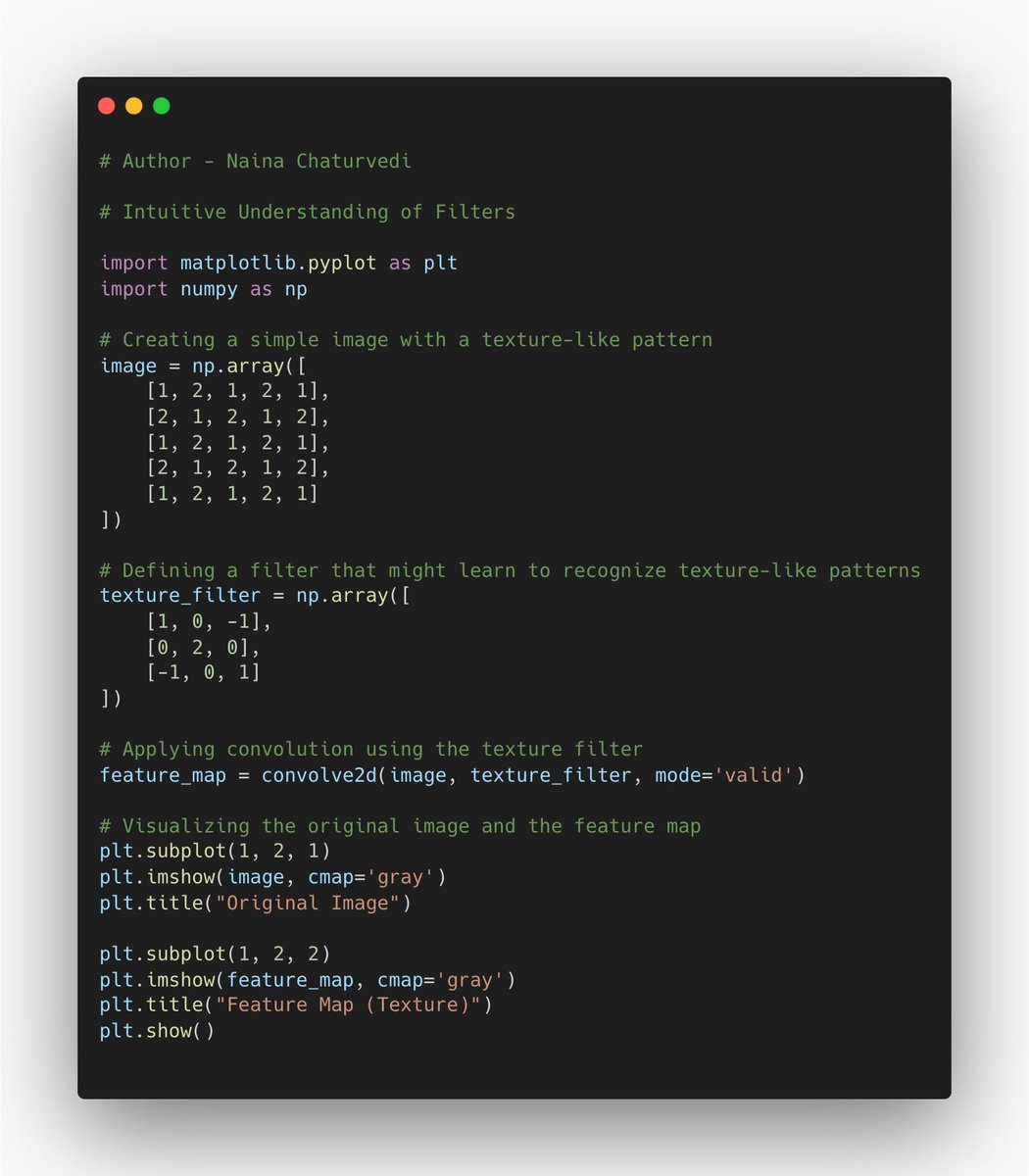
9/ Transfer Learning:
Transfer learning is a technique in machine learning and deep learning where a model that has been trained on one task is reused as the starting point for a model on a second task.
Transfer learning is a technique in machine learning and deep learning where a model that has been trained on one task is reused as the starting point for a model on a second task.
10/In the context of CNNs, transfer learning involves using a pre-trained neural network model as a foundation for solving a related but different problem.

11/ Pre-trained Models as Feature Extractors:
Pre-trained CNNs are models that have already been trained on massive datasets, often for image classification tasks. They have learned to extract valuable features from images.
Pre-trained CNNs are models that have already been trained on massive datasets, often for image classification tasks. They have learned to extract valuable features from images.
12/You can use these pre-trained models as feature extractors by removing the top classification layers and using the remaining layers to extract features from your own images.

13/Data Augmentation:
Data augmentation is a technique used to artificially increase the diversity and size of a dataset by applying various transformations to the original data. This can help improve the generalization of machine learning models and prevent overfitting.
Data augmentation is a technique used to artificially increase the diversity and size of a dataset by applying various transformations to the original data. This can help improve the generalization of machine learning models and prevent overfitting.

14/ One of the main benefits of data augmentation is addressing overfitting. By introducing variability in the training data, the model becomes more robust and less likely to memorize the training samples.

15/ Batch Normalization:
Batch normalization is a technique that normalizes the inputs of a layer during training, aiming to stabilize and accelerate the training process. It helps to mitigate issues like vanishing/exploding gradients and can lead to faster convergence.
Batch normalization is a technique that normalizes the inputs of a layer during training, aiming to stabilize and accelerate the training process. It helps to mitigate issues like vanishing/exploding gradients and can lead to faster convergence.

16/ Dropout:
Dropout is a regularization technique used to prevent overfitting. During training, dropout randomly deactivates a portion of neurons, forcing the network to learn more robust and general features.
Dropout is a regularization technique used to prevent overfitting. During training, dropout randomly deactivates a portion of neurons, forcing the network to learn more robust and general features.

17/ Residual Networks:
Residual connections, are used to mitigate vanishing gradient problem and make it easier for deep networks to train. They enable gradients to flow directly through network, helping in the training of very deep architectures.
Residual connections, are used to mitigate vanishing gradient problem and make it easier for deep networks to train. They enable gradients to flow directly through network, helping in the training of very deep architectures.

18/ Global Average Pooling:
Global Average Pooling (GAP) is a technique used to replace fully connected (FC) layers in the final stages of a CNN. It helps reduce overfitting and improve localization.
Global Average Pooling (GAP) is a technique used to replace fully connected (FC) layers in the final stages of a CNN. It helps reduce overfitting and improve localization.

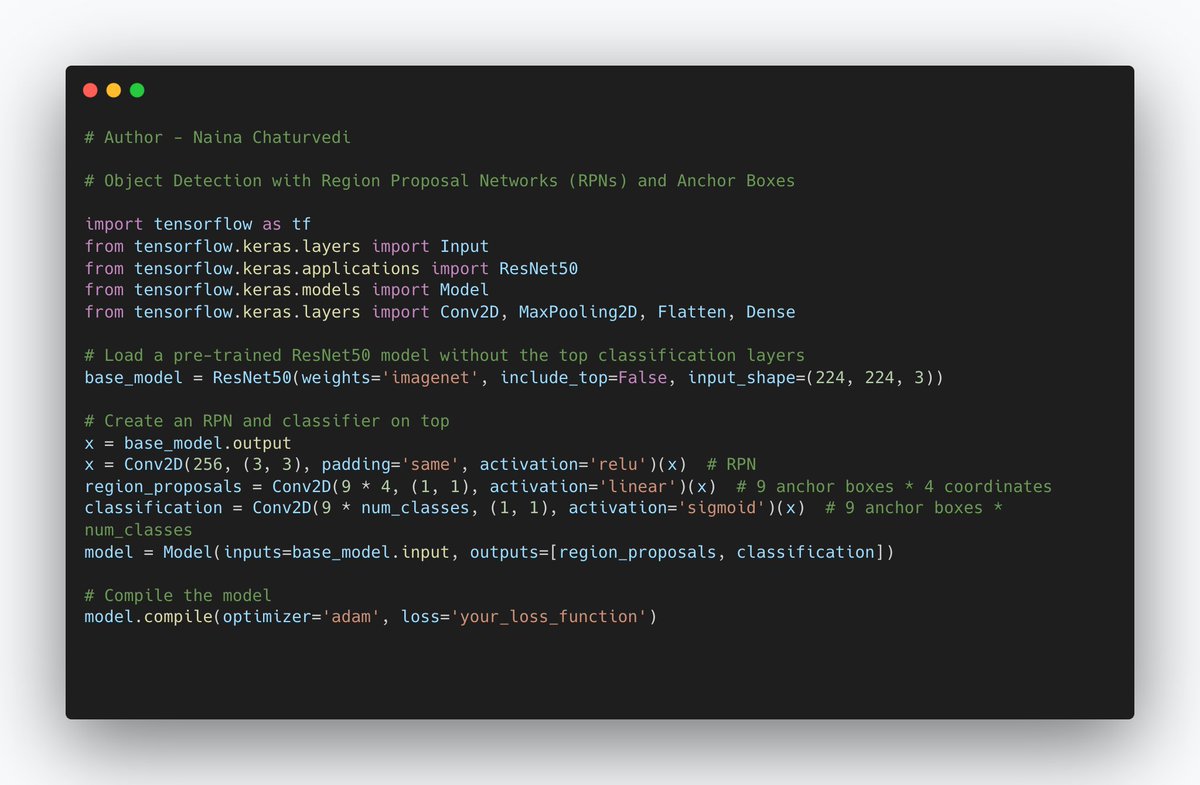
19/ Object Detection with Region Proposal Networks (RPNs) and Anchor Boxes:
Object detection involves identifying objects in an image and drawing bounding boxes around them. Region Proposal Networks (RPNs) are a part of modern object detection methods like Faster R-CNN.
Object detection involves identifying objects in an image and drawing bounding boxes around them. Region Proposal Networks (RPNs) are a part of modern object detection methods like Faster R-CNN.
20/Anchor boxes are predefined boxes of different sizes and aspect ratios that the network uses to suggest potential object locations.
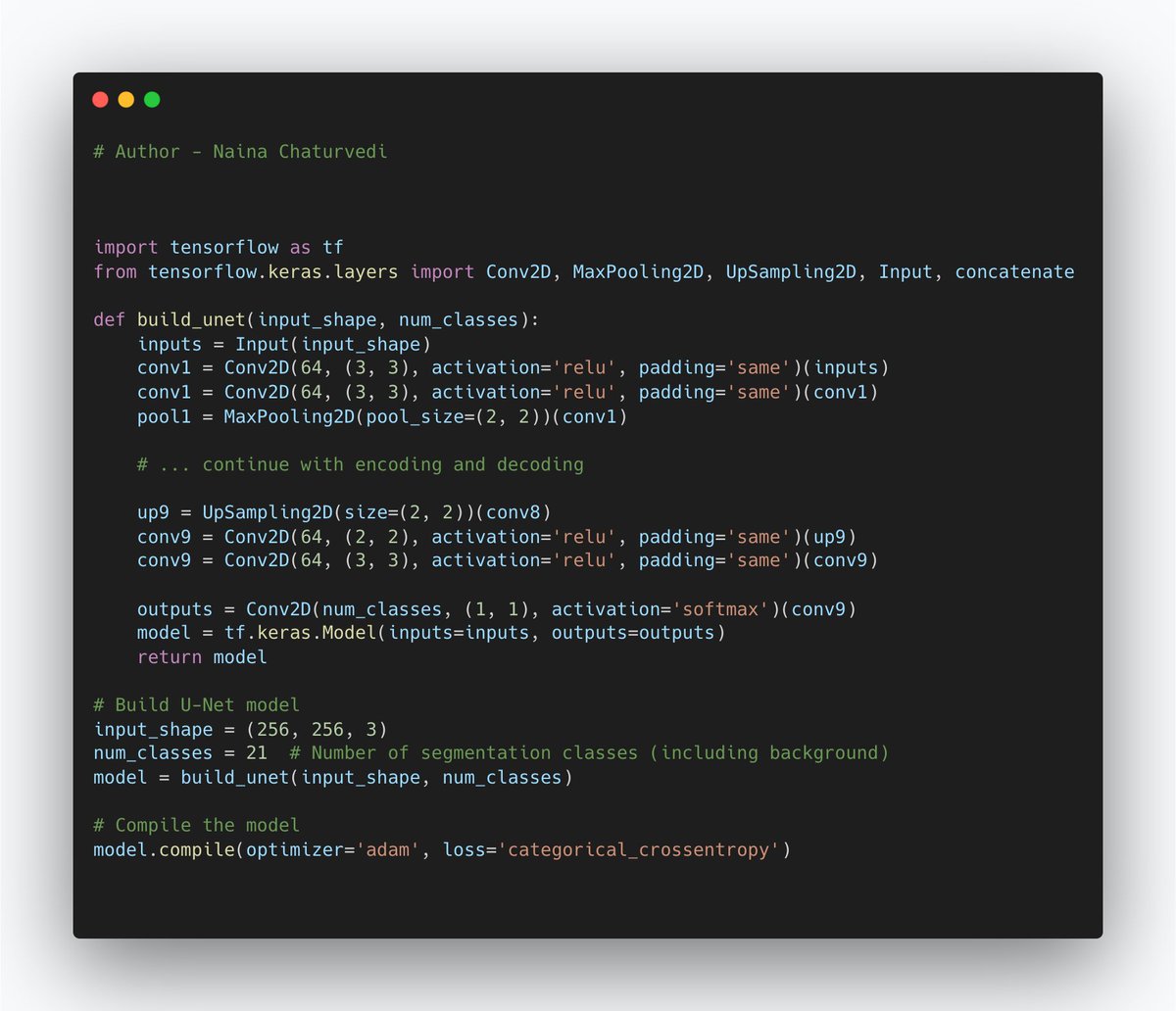
21/ Semantic Segmentation with U-Net:
It involves classifying each pixel in an image into a specific class label. U-Net is used for semantic segmentation that consists of an encoder and decoder, allowing the network to capture both high-level and fine-grained features.
It involves classifying each pixel in an image into a specific class label. U-Net is used for semantic segmentation that consists of an encoder and decoder, allowing the network to capture both high-level and fine-grained features.
22/ Style Transfer:
It is a technique that uses CNNs to transform artistic style of one image onto content of another image. It involves extracting style and content features from 2 images & combining them to create a new image that has content of one image and style of another.
It is a technique that uses CNNs to transform artistic style of one image onto content of another image. It involves extracting style and content features from 2 images & combining them to create a new image that has content of one image and style of another.

23/ Content Loss and Style Loss in Neural Style Transfer:
In neural style transfer, content loss and style loss are used to define the objectives that guide the optimization process. Content loss measures the difference between content of generated image and the content image.
In neural style transfer, content loss and style loss are used to define the objectives that guide the optimization process. Content loss measures the difference between content of generated image and the content image.

• • •
Missing some Tweet in this thread? You can try to
force a refresh