
I cannot believe zuck et al just beat gpt 3.5 at humaneval pass@1 and is approaching gpt4 with only 34b params
(47 pages, therefore reaction thread - code llama)
(47 pages, therefore reaction thread - code llama)

>trained on 16k tokens
pretty cool
>7B & 13B
>trained on infilling, instead of just prompt completion.
good for copilot replacement & custom local hacks
because gpt 3.5's init token latency was so bad, I had to retire my custom vscode extension
Having options is good!
pretty cool
>7B & 13B
>trained on infilling, instead of just prompt completion.
good for copilot replacement & custom local hacks
because gpt 3.5's init token latency was so bad, I had to retire my custom vscode extension
Having options is good!
500B tokens, then 20B tokens for long context fine tuning that's a lot of tokens
(for the foundational model that they release)
really hope they talk about the distributions of the data
(for the foundational model that they release)
really hope they talk about the distributions of the data

The 500B tokens is:
-a "near deduplicated" dataset of public code
- 8% of the data is from natural language related to code (likely code documentation & public Q/A)
- they prevent forgetting langauge understanding using a sample from a natural language dataset
-a "near deduplicated" dataset of public code
- 8% of the data is from natural language related to code (likely code documentation & public Q/A)
- they prevent forgetting langauge understanding using a sample from a natural language dataset
Their instruct dataset makes me feel itchy. It's generated, and sized at 14k
They use self instruct by creating unit tests, and then running the solutions against them to select.
:<
The problem is that the functions are interview style questions, and too localized
They use self instruct by creating unit tests, and then running the solutions against them to select.
:<
The problem is that the functions are interview style questions, and too localized
lol holy shit
free use unless you're google source software is going to actually beat gpt4 in a few months guaranteed
this is crazy
also - interesting to note the improvement of code llama python
fwiw a lot doesn't get captured in evals
I expect good UX models have worse evals
free use unless you're google source software is going to actually beat gpt4 in a few months guaranteed
this is crazy
also - interesting to note the improvement of code llama python
fwiw a lot doesn't get captured in evals
I expect good UX models have worse evals
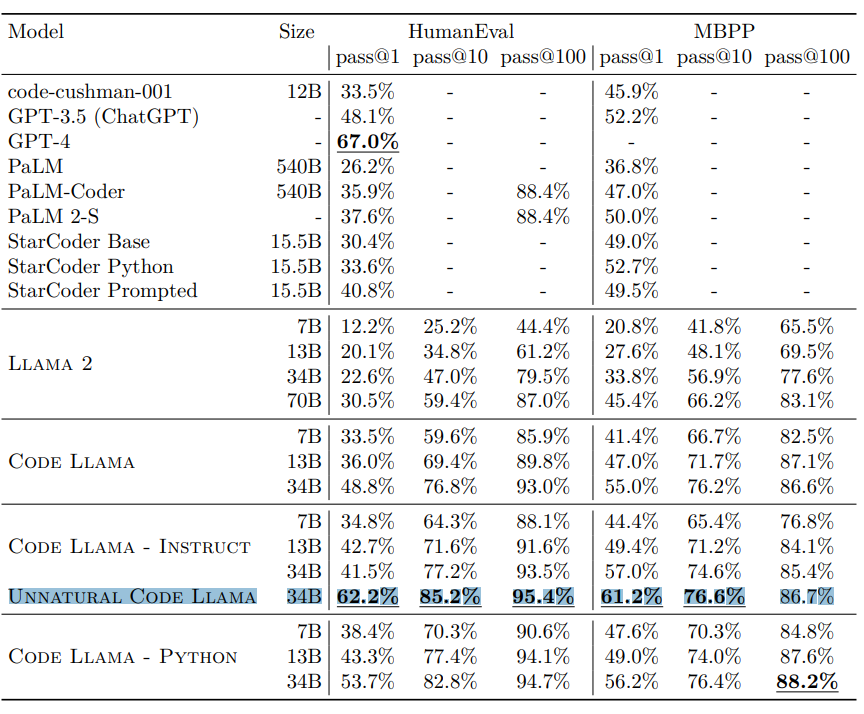
needs galactica proofreading :>
(teasing, I make a ton of mistakes too)
(teasing, I make a ton of mistakes too)

interesting
code llama is best at cplusplus human eval, vs other languages
wonder why
code llama is best at cplusplus human eval, vs other languages
wonder why

context up to 100k tokens shows decrease in ppl. very cool

you, also, learn to code after you learn to read and write, correct? therefore chart.

interesting
use low temperature for first guess, increase temperatures for subsequent guesses?
use low temperature for first guess, increase temperatures for subsequent guesses?

looooooool shade thrown
"where are the pretrained weights, sama? i though't ya'll were supposed to be open? hmmmmmmmm?" - zuck, probably
"where are the pretrained weights, sama? i though't ya'll were supposed to be open? hmmmmmmmm?" - zuck, probably

lol i knew it
>have access to one of the biggest compute cluster in the world
>overfit it on L1 interview questions
glad they ran the experiment, but I'm not going to bother downloading anything other than the foundation model
>have access to one of the biggest compute cluster in the world
>overfit it on L1 interview questions
glad they ran the experiment, but I'm not going to bother downloading anything other than the foundation model

summary
- in the next month people are going to build pretty insane things on top of the 34b code foundational model
- the finetunes they created are of scientific interest, but don't download them and train your own
- in the next month people are going to build pretty insane things on top of the 34b code foundational model
- the finetunes they created are of scientific interest, but don't download them and train your own
what a huge contribution from their team
it's not just compute
it's a lot of human hours and skill
thank you!
it's not just compute
it's a lot of human hours and skill
thank you!

• • •
Missing some Tweet in this thread? You can try to
force a refresh



