
Neural networks are stunningly powerful.
This is old news: deep learning is state-of-the-art in many fields, like computer vision and natural language processing. (But not everywhere.)
Why are neural networks so effective? I'll explain.
This is old news: deep learning is state-of-the-art in many fields, like computer vision and natural language processing. (But not everywhere.)
Why are neural networks so effective? I'll explain.
First, let's formulate the classical supervised learning task!
Suppose that we have a dataset D, where xₖ is a data point and yₖ is the ground truth.
Suppose that we have a dataset D, where xₖ is a data point and yₖ is the ground truth.

The task is simply to find a function g(x) for which
• g(xₖ) is approximately yₖ,
• and g(x) is computationally feasible.
To achieve this, we fix a parametrized family of functions. For instance, linear regression uses this function family:
• g(xₖ) is approximately yₖ,
• and g(x) is computationally feasible.
To achieve this, we fix a parametrized family of functions. For instance, linear regression uses this function family:

If we assume that there exists a true underlying function f(x) that describes the relationship between xₖ and yₖ, the problem can be phrased as a function approximation problem:
"How can we find a function from our parametric family that is as close to f(x) as possible?"
"How can we find a function from our parametric family that is as close to f(x) as possible?"
What is even approximation theory? Here's a primer.
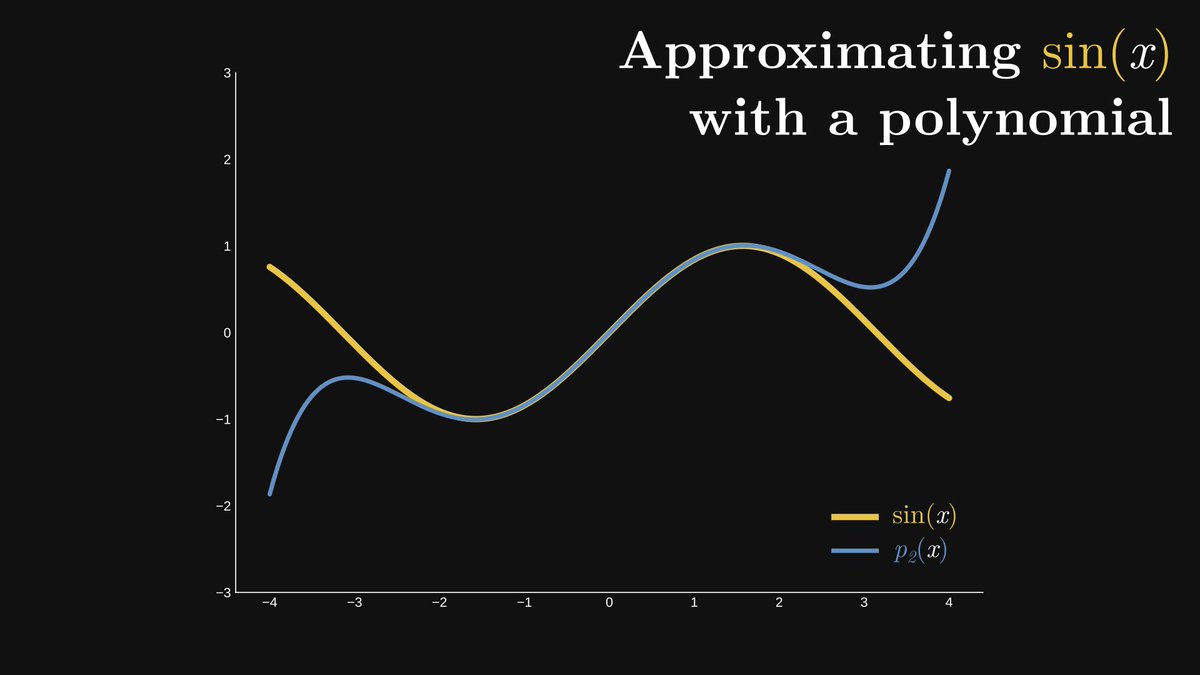
Check out the sine function, defined in terms of a right triangle. Except for a few special cases like x = π/4, it is impossible to compute in practice.
Check out the sine function, defined in terms of a right triangle. Except for a few special cases like x = π/4, it is impossible to compute in practice.

Why? Because sine is a transcendental function, meaning that you cannot calculate its value with finite additions and multiplications.
However, when you punch, say, sin(2.123) into a calculator, you'll get an answer. This is done via an approximation.
However, when you punch, say, sin(2.123) into a calculator, you'll get an answer. This is done via an approximation.

Here it is in the case of n = 2, which is a polynomial of degree five. It is already a very good approximation, albeit only on the interval [-2, 2].
Let's revisit the problem of supervised learning! Suppose that the function f(x) describes the true relation between data and observation.
f(x) is not known exactly, only for some values xₖ, where f(xₖ) = yₖ.
f(x) is not known exactly, only for some values xₖ, where f(xₖ) = yₖ.
Our job is to find an approximating function g(x) that
1. fits the data,
2. properly generalizes to unseen samples,
3. and is computationally feasible.
In the language of approximation theory, we want a function that minimizes the so-called supremum norm.
1. fits the data,
2. properly generalizes to unseen samples,
3. and is computationally feasible.
In the language of approximation theory, we want a function that minimizes the so-called supremum norm.
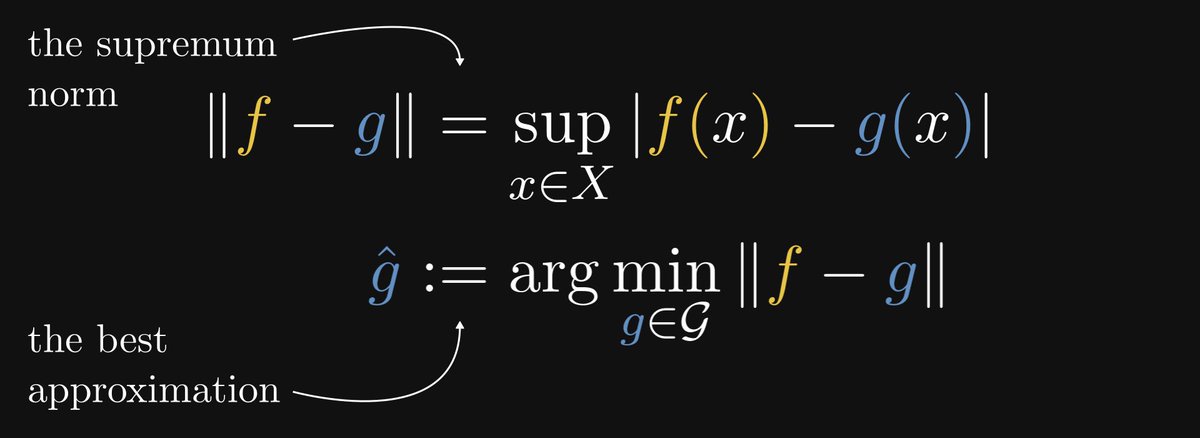
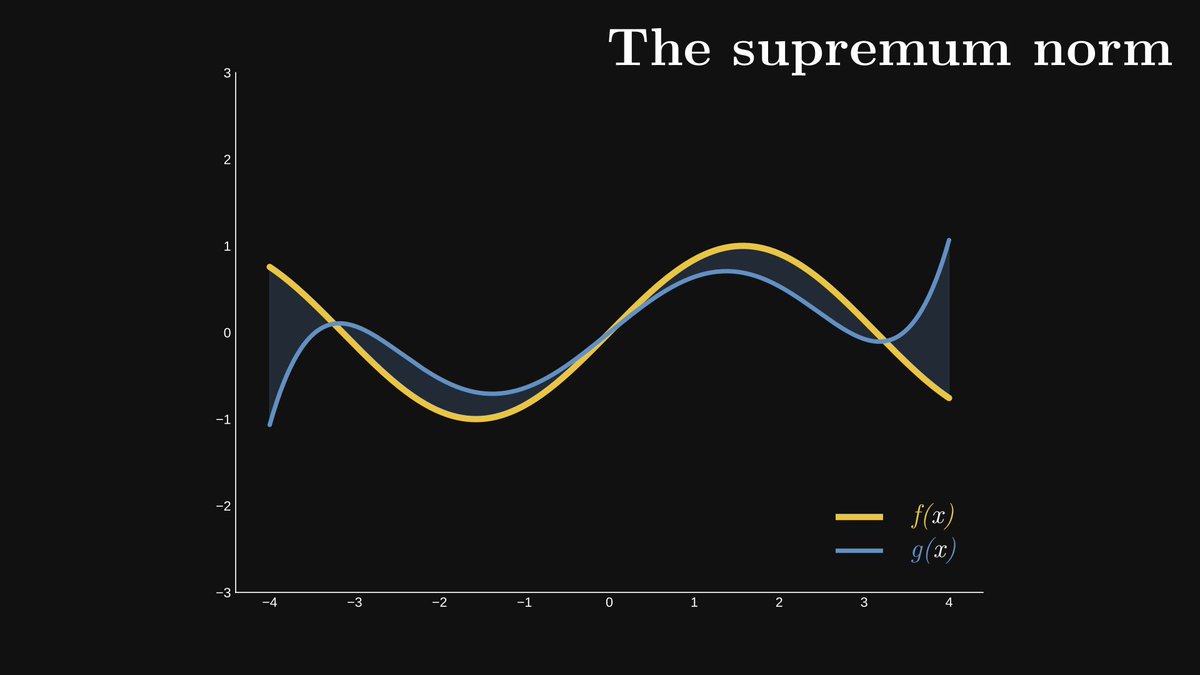
The smaller || f - g || is, the better the fit. Thus, our goal is to be as small as possible.
You can imagine || f - g || by plotting these functions, coloring the area enclosed by the graph, and calculating the maximum spread of said area along the y axis.
You can imagine || f - g || by plotting these functions, coloring the area enclosed by the graph, and calculating the maximum spread of said area along the y axis.
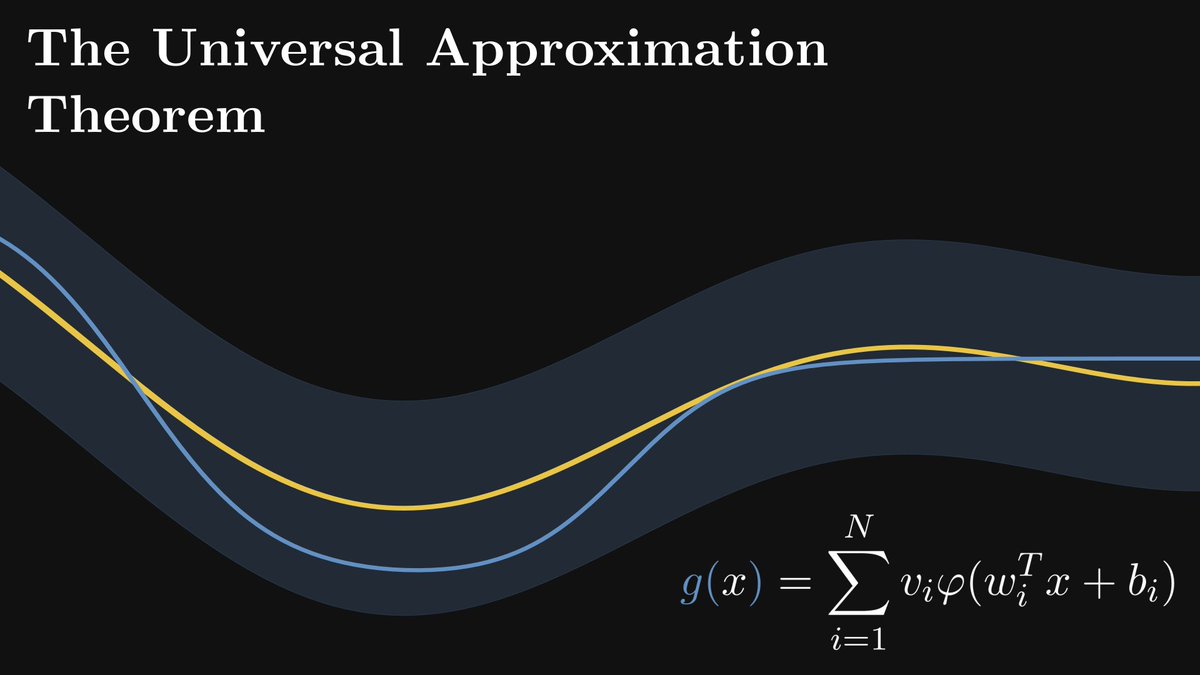
Mathematically speaking, a neural network with a single hidden layer is defined by the following function.
(N is the number of neurons in the hidden layer; 𝜑 is a nonlinear function such as the Sigmoid; and the wᵢ-s and bᵢ-s are vectors, while the vᵢ-s are real numbers.)
(N is the number of neurons in the hidden layer; 𝜑 is a nonlinear function such as the Sigmoid; and the wᵢ-s and bᵢ-s are vectors, while the vᵢ-s are real numbers.)
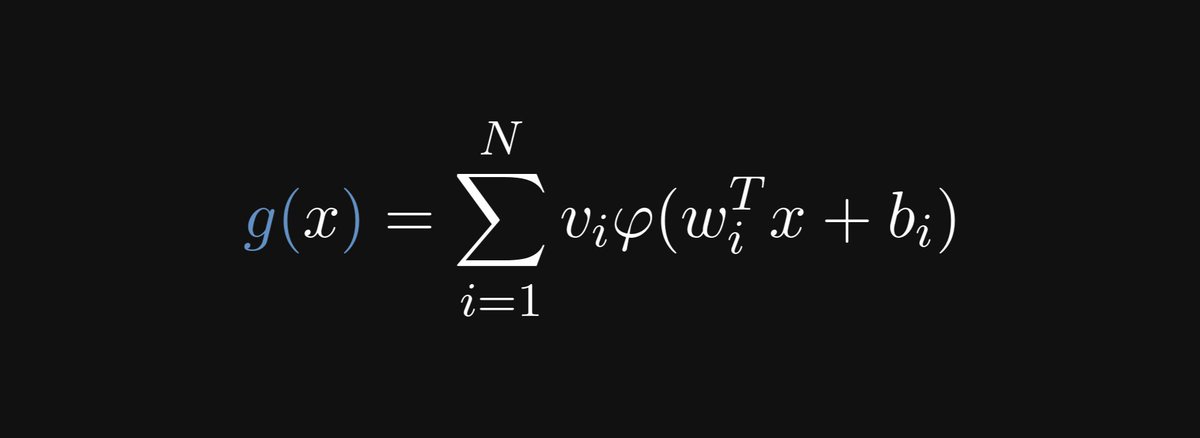
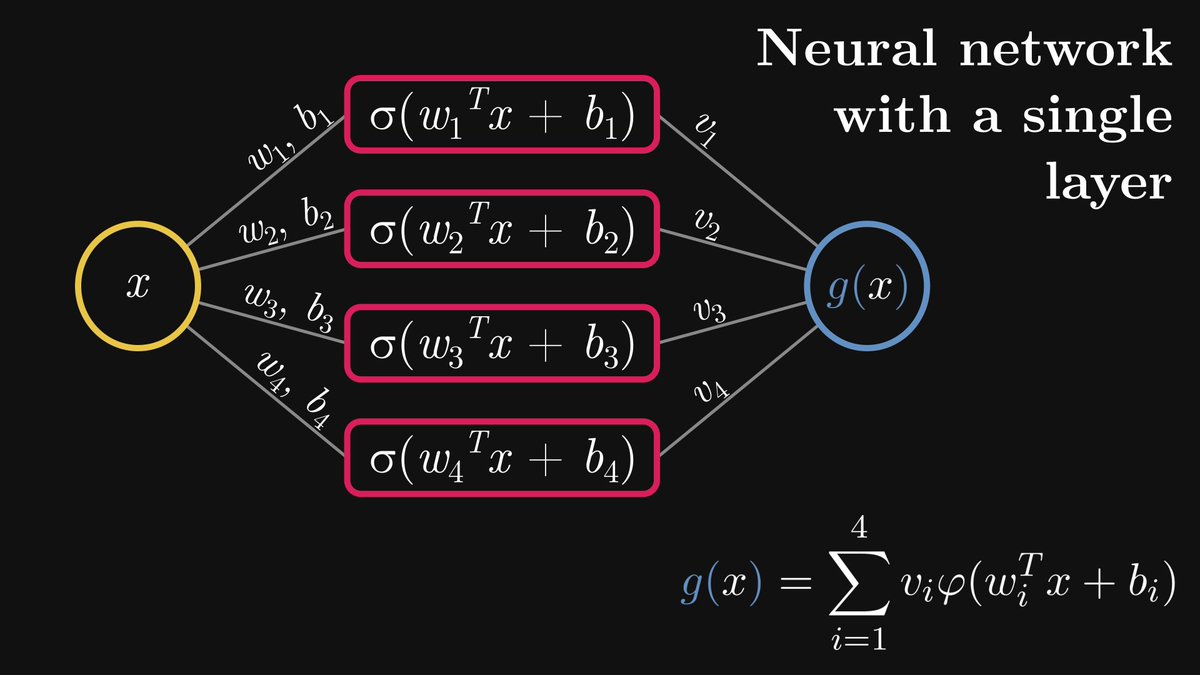
For clarity, here is the graphical representation of a single-layer neural network with four hidden neurons.
Are single-layer neural networks expressive enough to approximate any reasonable function?
Yes. Meet the universal approximation theorem. Let's unpack it.
(Source: Cybenko, G. (1989) "Approximations by superpositions of sigmoidal functions".)
Yes. Meet the universal approximation theorem. Let's unpack it.
(Source: Cybenko, G. (1989) "Approximations by superpositions of sigmoidal functions".)
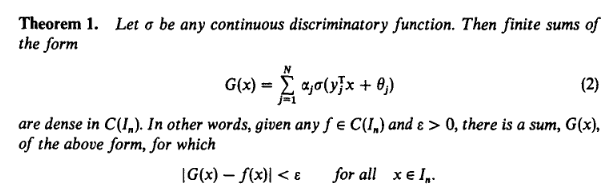
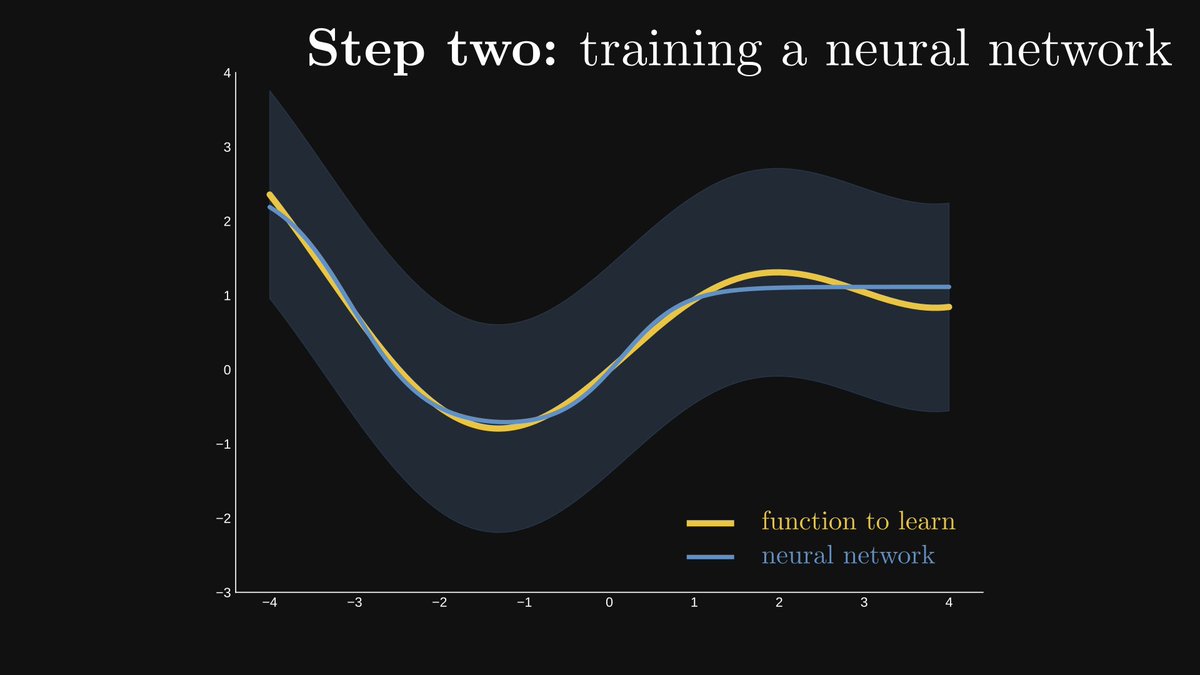
Step one. Fix a small number ε and draw an ε wide stripe around f(x), the function to learn. The smaller ε is, the better the result will be.

Step two. (The hard part.) Find a neural network that remains inside the stripe.
Is it even possible? Yes: the theorem guarantees its existence. This is why neural networks are called universal approximators.
Is it even possible? Yes: the theorem guarantees its existence. This is why neural networks are called universal approximators.
Unfortunately, there are several serious issues.
1. The theorem doesn't tell us how to find such a neural network.
2. The number of neurons can be really high.
3. We can't measure the supremum norm in practice.
1. The theorem doesn't tell us how to find such a neural network.
2. The number of neurons can be really high.
3. We can't measure the supremum norm in practice.
Thus, we can't just sit on our laurels after proving the universal approximation theorem.
The bulk of the work is ahead of us: finding a good approximation in practice; avoiding overfitting; and many others.
These are going to be our topics for another day :)
The bulk of the work is ahead of us: finding a good approximation in practice; avoiding overfitting; and many others.
These are going to be our topics for another day :)
Read the full version of the thread here: thepalindrome.org/p/why-are-neur…
If you have enjoyed this thread, share it with your friends and follow me!
I regularly post deep-dive explainers about mathematics and machine learning such as this.
I regularly post deep-dive explainers about mathematics and machine learning such as this.
https://twitter.com/TivadarDanka/status/1701906107965530457
• • •
Missing some Tweet in this thread? You can try to
force a refresh
















