✅Measuring performance in ML is essential to assess the quality and effectiveness of your models - Explained in simple terms.
A quick thread 👇🏻🧵
#MachineLearning #DataScientist #Coding #100DaysofCode #deeplearning #DataScience
PC : Research Gate
A quick thread 👇🏻🧵
#MachineLearning #DataScientist #Coding #100DaysofCode #deeplearning #DataScience
PC : Research Gate

1/ It is the process of quantitatively evaluating how well a trained ML model performs on a given task or dataset. It involves using specific metrics and techniques to assess the model's ability to make accurate predictions or decisions.
2/ During Model Development: Performance measurement is an integral part of ML model development. It helps data scientists and ML engineers assess the effectiveness of different algorithms, features, and hyperparameters during the model training and selection process.

3/ After Model Deployment: Once a model is deployed in the production environment, continuous performance monitoring is essential. It helps ensure that the model maintains its accuracy and effectiveness over time.

4/ Benchmarking: Performance measurement is also crucial for benchmarking different models or approaches to solve a particular problem. It allows for fair comparisons and the selection of the best-performing model.

5/ Model Evaluation: Measuring performance allows us to assess how well a machine learning model is generalizing from the training data to unseen data. This evaluation is critical for selecting the best model among different options.

6/ Hyperparameter Tuning: Performance metrics guide the process of hyperparameter tuning, where we adjust the model's settings to achieve better results. Without measuring performance, we wouldn't know which hyperparameters to choose.

7/ Comparing Models: Performance metrics enable us to compare different models or algorithms to determine which one performs better for a specific task. This helps in making informed decisions about model selection.

8/ Classification:
Accuracy: It measures the fraction of correctly classified instances out of the total instances.
Precision: It quantifies the accuracy of positive predictions. Precision is the ratio of true positives to the total predicted positives.
Accuracy: It measures the fraction of correctly classified instances out of the total instances.
Precision: It quantifies the accuracy of positive predictions. Precision is the ratio of true positives to the total predicted positives.

9/ Recall: It quantifies the ability of the model to find all relevant instances. Recall is the ratio of true positives to the total actual positives.
F1-score: It is the harmonic mean of precision and recall and provides a balanced measure.
F1-score: It is the harmonic mean of precision and recall and provides a balanced measure.
10/ ROC-AUC: Receiver Operating Characteristic - Area Under the Curve measures the model's ability to distinguish between classes.
11/ Regression:
Mean Absolute Error (MAE): It measures the average absolute difference between the predicted and actual values.
Mean Squared Error (MSE): It measures the average squared difference between predicted and actual values.
Mean Absolute Error (MAE): It measures the average absolute difference between the predicted and actual values.
Mean Squared Error (MSE): It measures the average squared difference between predicted and actual values.

12/ R-squared (R2): It quantifies the proportion of the variance in the dependent variable that is predictable from the independent variables.

13/ Clustering:
Silhouette Score: Measures how similar an object is to its own cluster compared to other clusters. Values range from -1 (incorrect clustering) to +1 (highly dense clustering).
Silhouette Score: Measures how similar an object is to its own cluster compared to other clusters. Values range from -1 (incorrect clustering) to +1 (highly dense clustering).

14/ Davies-Bouldin Index: Measures the average similarity between each cluster with the cluster that is most similar to it. Lower values indicate better clustering.
15/ Recommendation:
Mean Average Precision (MAP): Measures the average precision for a recommendation system.
Hit Rate: Measures the proportion of correct recommendations in the top-N recommendations.
Mean Average Precision (MAP): Measures the average precision for a recommendation system.
Hit Rate: Measures the proportion of correct recommendations in the top-N recommendations.

16/ BLEU (Bilingual Evaluation Understudy): Measures the similarity of machine-generated text to a set of reference texts.
ROUGE (Recall-Oriented Understudy for Gisting Evaluation): Evaluates the quality of summaries and machine-generated text.
ROUGE (Recall-Oriented Understudy for Gisting Evaluation): Evaluates the quality of summaries and machine-generated text.

17/ In classification problems, when one class significantly outnumbers the others, it can lead to imbalanced datasets. In such cases, a model that predicts the majority class most of the time can achieve high accuracy, but it may perform poorly on the minority class.

18/ Confusion Matrix is a table that helps visualize the performance of a classification algorithm by showing the number of correct and incorrect predictions made by the model.
True Positives (TP): The number of instances correctly predicted as positive.
True Positives (TP): The number of instances correctly predicted as positive.

19/ True Negatives (TN): The number of instances correctly predicted as negative.
False Positives (FP): The number of instances incorrectly predicted as positive.
False Negatives (FN): The number of instances incorrectly predicted as negative.
False Positives (FP): The number of instances incorrectly predicted as positive.
False Negatives (FN): The number of instances incorrectly predicted as negative.
20/Accuracy: It measures the overall correctness of model's predictions. Accuracy is calculated as (TP + TN) / (TP + TN + FP + FN).
Precision: Precision quantifies how many of positive predictions made by model are actually correct. Precision is calculated as TP / (TP + FP).
Precision: Precision quantifies how many of positive predictions made by model are actually correct. Precision is calculated as TP / (TP + FP).
21/ Recall (Sensitivity or True Positive Rate): Recall measures how many of the actual positive instances were correctly predicted by the model. It is calculated as TP / (TP + FN).
22/ F1-Score: The F1-score is the harmonic mean of precision and recall, providing a balanced measure that considers both false positives and false negatives. It is calculated as 2 * (Precision * Recall) / (Precision + Recall).
23/ Receiver Operating Characteristic (ROC) Curve and Area Under the Curve (AUC) are valuable tools for evaluating the performance of binary classifiers. They help assess a classifier's ability to distinguish between positive and negative classes.

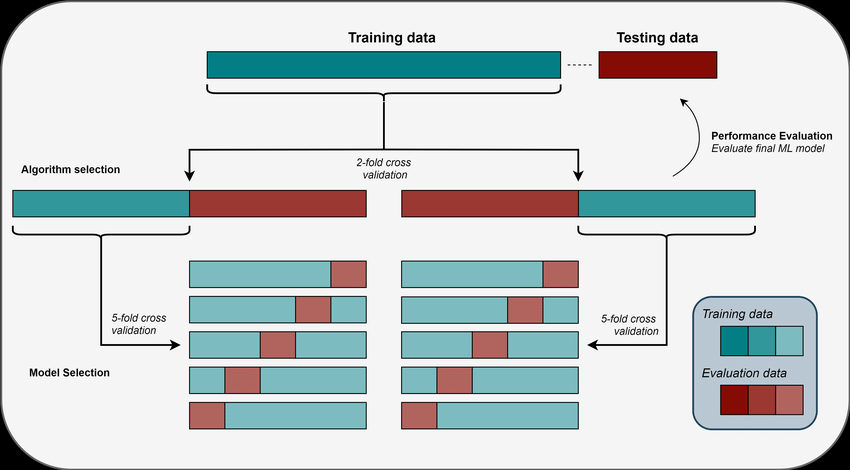
24/ Cross-validation is a crucial technique for estimating a model's performance on unseen data and reducing the risk of overfitting. It involves splitting the dataset into multiple subsets (folds) to train and evaluate the model multiple times.

25/ Bias-Variance Trade-off is a fundamental concept that addresses the balance between two types of errors that models can make: bias and variance.

26/ Bias: Bias refers to the error introduced by approximating a real-world problem, which may be complex, by a simplified model. High bias models are typically too simplistic and make strong assumptions about the data, resulting in poor predictions.
27/ Variance: Variance refers to the error introduced by the model's sensitivity to small fluctuations or noise in the training data. High variance models are overly complex and can fit the training data too closely, capturing noise rather than the underlying patterns.
28/ Overfitting and Underfitting are common issues that arise when a model's performance on training and validation datasets indicates problems with generalization.

29/ Overfitting occurs when a model learns the training data too well, capturing noise and small fluctuations in the data rather than the underlying patterns.
The model performs exceptionally well on the training data but poorly on the validation (or test) data.
The model performs exceptionally well on the training data but poorly on the validation (or test) data.
30/ Underfitting occurs when a model is too simple to capture the underlying patterns in the data.
The model performs poorly on both the training and validation data.
There may be a minimal gap or no gap between the training and validation performance, but both are subpar.
The model performs poorly on both the training and validation data.
There may be a minimal gap or no gap between the training and validation performance, but both are subpar.
31/ Hyperparameter Tuning is the process of finding the best set of hyperparameters for a ML model to achieve optimal performance on a given task. Hyperparameters are configurations and settings that are not learned from data but are set before training the model.

32/ Feature importance measures quantify the impact of each input feature on the model's predictions. For interpretable models, understanding which features are most influential can be critical.

• • •
Missing some Tweet in this thread? You can try to
force a refresh