✅Hyperparameter tuning is a critical step in machine learning to optimize model performance - Explained in simple terms.
A quick thread 🧵👇🏻
#MachineLearning #DataScientist #Coding #100DaysofCode #deeplearning #DataScience
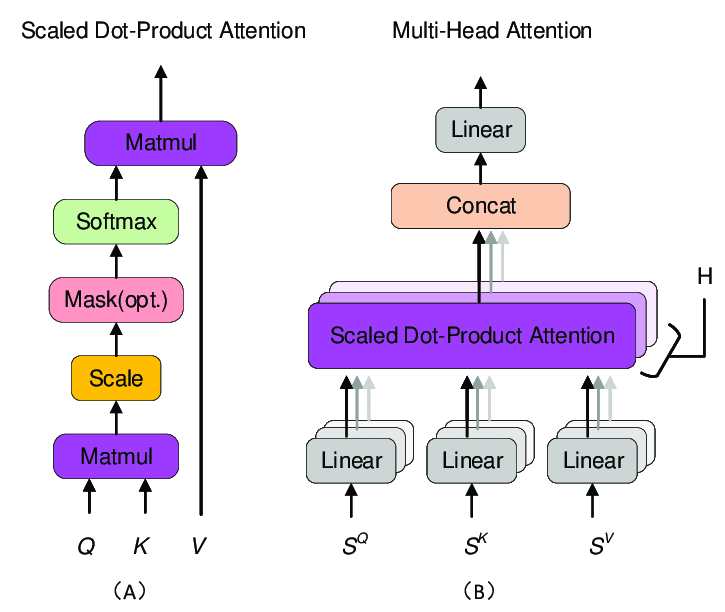
PC : Research Gate
A quick thread 🧵👇🏻
#MachineLearning #DataScientist #Coding #100DaysofCode #deeplearning #DataScience
PC : Research Gate

1/ Hyperparameter tuning is like finding the best settings for a special machine that does tasks like coloring pictures or making cookies. You try different combinations of settings to make the machine work its best, just like adjusting ingredients for the tastiest cookies.
2/ It's the process of systematically searching for the optimal values of hyperparameters in a machine learning model. Hyperparameters are settings that are not learned from the data but are set prior to training, such as the learning rate in a neural network.

3/Hyperparameter tuning is important because choosing right hyperparameters can significantly impact model's performance. It involves trying different combinations of hyperparameters to find ones that result in best model performance, measured using a validation dataset.
4/ Hyperparameters control the behavior and capacity of the machine learning model. They influence how the model learns and generalizes from the data. By adjusting hyperparameters, you can tailor the model's performance and make it more suitable for a specific task.

5/ Improving Model Performance: Hyperparameters control how your model learns from data. Selecting appropriate values for hyperparameters can make your model more accurate and effective at its task. Incorrect hyperparameters can lead to underfitting or overfitting

6/ Generalization: Machine learning models aim to generalize patterns from the training data to make predictions on new, unseen data. Well-tuned hyperparameters help your model generalize better by finding the right balance between simplicity and complexity.

7/ Avoiding Bias: Hyperparameters often depend on the specific dataset and problem you're working on. By tuning them, you can adapt your model to the unique characteristics of your data, reducing bias and making it more suitable for your task.

8/ Optimizing Resources: Hyperparameter tuning can help you make the most efficient use of computational resources. It allows you to find the best-performing model with the fewest resources, such as training time and memory.

9/ Common Hyperparameters:
Learning Rate:Learning rate controls how much the model's parameters are updated during training.
A high learning rate can cause the model to converge quickly but might overshoot the optimal solution or get stuck in a suboptimal one.
Learning Rate:Learning rate controls how much the model's parameters are updated during training.
A high learning rate can cause the model to converge quickly but might overshoot the optimal solution or get stuck in a suboptimal one.

10/ A low learning rate may lead to slow convergence or getting stuck in local minima. Commonly tuned using techniques like grid search or random search.
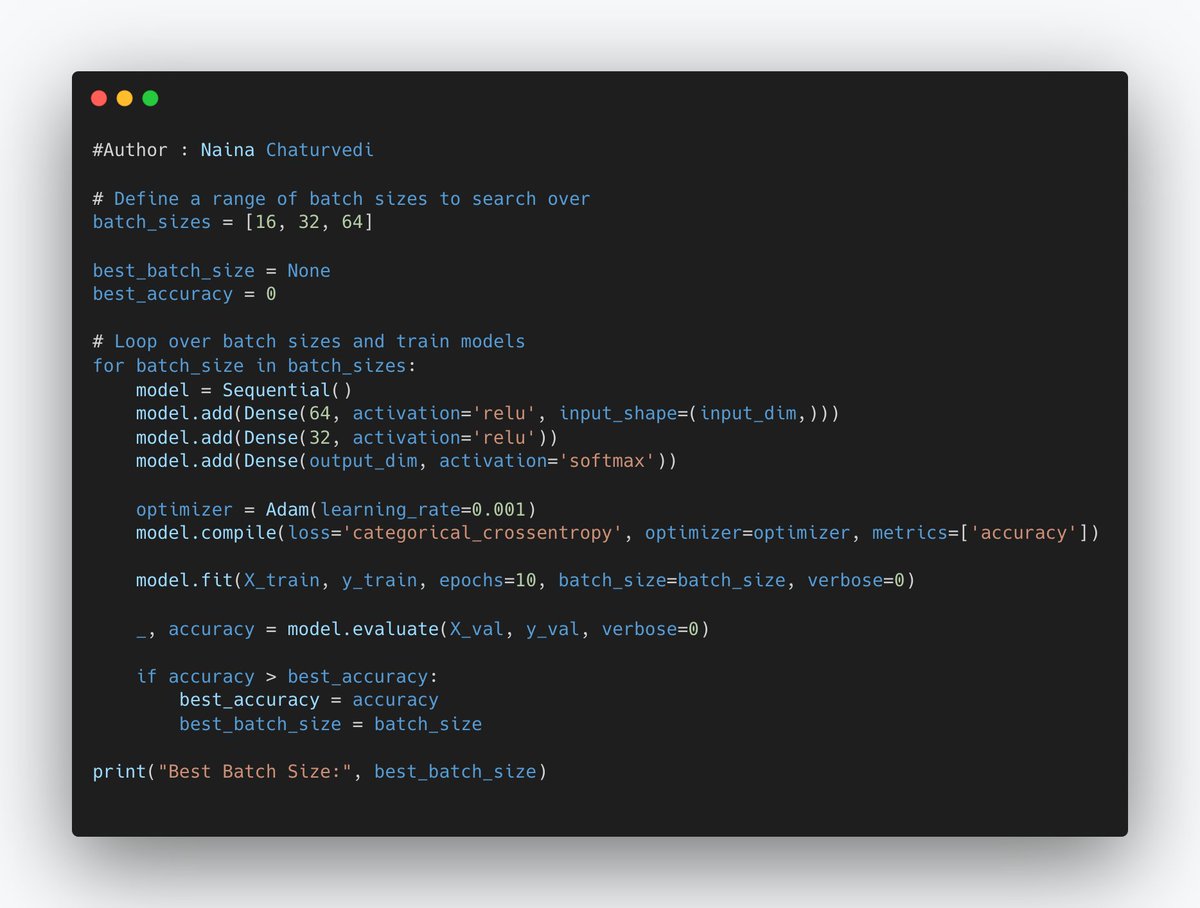
11/ Batch Size:
Batch size determines how many data points are used in each iteration during training.
A small batch size can result in noisy updates and slower convergence, while a large batch size can lead to faster convergence but may require more memory.
Batch size determines how many data points are used in each iteration during training.
A small batch size can result in noisy updates and slower convergence, while a large batch size can lead to faster convergence but may require more memory.
12/ Number of Layers:
In deep learning models like neural networks, the number of layers (depth) is a critical hyperparameter.
Deeper networks can capture complex patterns but are more prone to overfitting, while shallower networks may underfit.
In deep learning models like neural networks, the number of layers (depth) is a critical hyperparameter.
Deeper networks can capture complex patterns but are more prone to overfitting, while shallower networks may underfit.

13/ Number of Neurons per Layer:
The number of neurons (units) in each layer of a neural network is another crucial hyperparameter.
Too few neurons can result in underfitting, while too many can lead to overfitting.
The number of neurons (units) in each layer of a neural network is another crucial hyperparameter.
Too few neurons can result in underfitting, while too many can lead to overfitting.

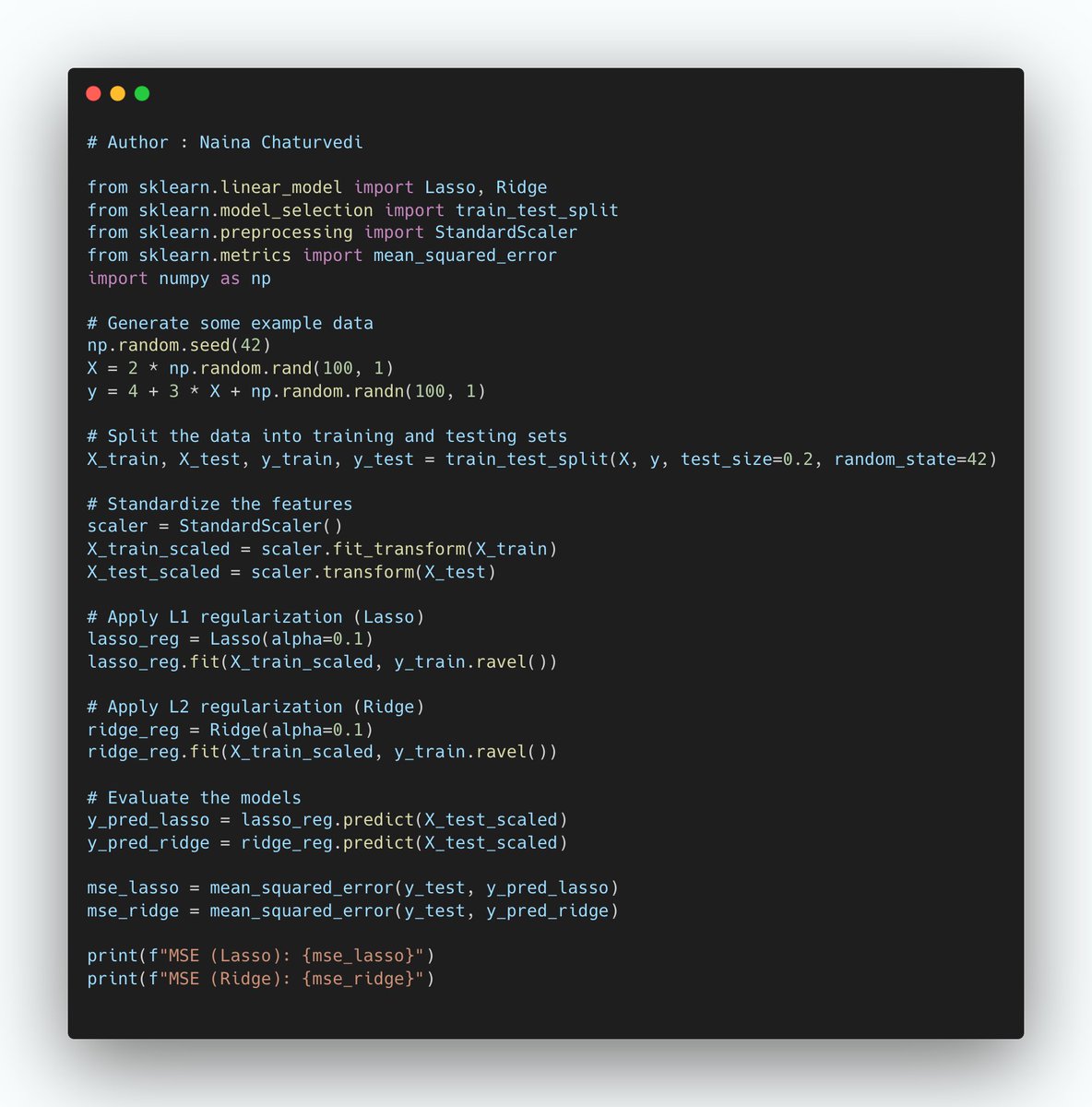
14/ Regularization Strength:
Regularization techniques like L1 and L2 regularization add penalty terms to the loss function to prevent overfitting.
The strength of regularization is controlled by a hyperparameter (lambda or alpha).
Regularization techniques like L1 and L2 regularization add penalty terms to the loss function to prevent overfitting.
The strength of regularization is controlled by a hyperparameter (lambda or alpha).

15/ Dropout Rate:
Dropout is a regularization technique that randomly drops out a fraction of neurons during training.
The dropout rate determines fraction of neurons to drop out in each layer.
Tuning involves experimenting with different dropout rates to prevent overfitting.
Dropout is a regularization technique that randomly drops out a fraction of neurons during training.
The dropout rate determines fraction of neurons to drop out in each layer.
Tuning involves experimenting with different dropout rates to prevent overfitting.

16/ Hyperparameter Search Space:
The range of values or distributions for each hyperparameter that you intend to explore during hyperparameter tuning process. It defines boundaries within which you search for optimal hyperparameter values that lead to best model performance.
The range of values or distributions for each hyperparameter that you intend to explore during hyperparameter tuning process. It defines boundaries within which you search for optimal hyperparameter values that lead to best model performance.

17/ Continuous Hyperparameters: For hyperparameters like learning rate, you might define a continuous search space by specifying a range of values, such as [0.01, 0.1, 1.0]. This means you'll explore these specific values within that range.

18/ Discrete Hyperparameters: Some hyperparameters, like the number of neurons in a layer, might have discrete options. For example, you can explore [32, 64, 128] as potential values for the number of neurons.

19/ Categorical Hyperparameters: Certain hyperparameters may be categorical, meaning they take on specific non-numeric values. For example, you might explore ['adam', 'sgd', 'rmsprop'] as choices for the optimizer algorithm in a neural network.

20/ Distributions: To define a hyperparameter search space using probability distributions, such as uniform, log-uniform, or normal distributions. This allows you to explore a continuous range of values probabilistically.

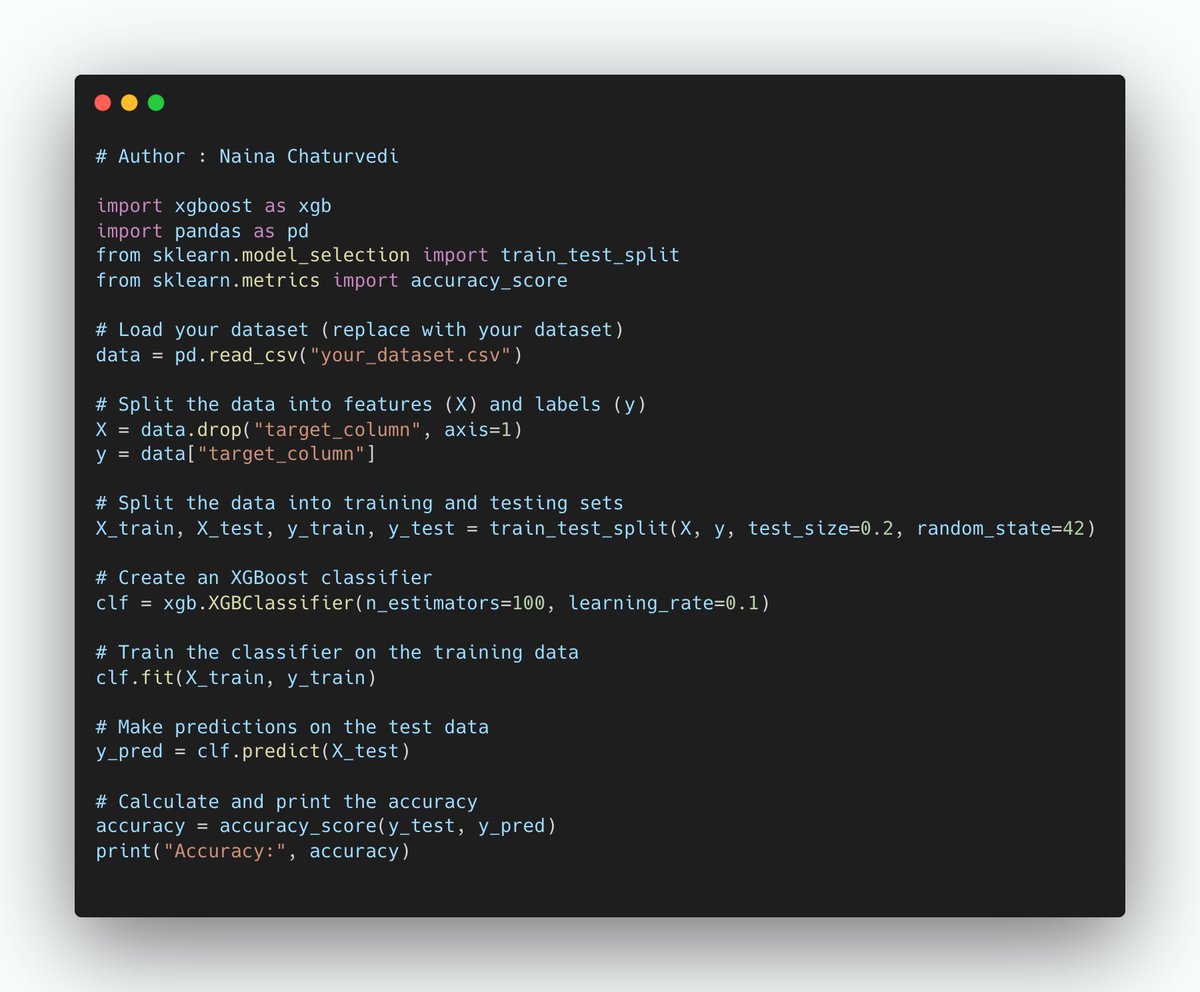
21/ Grid Search:
Grid Search is a technique that exhaustively searches predefined hyperparameter combinations within a specified search space.
It's simple but can be computationally expensive when the search space is large.
Grid Search is a technique that exhaustively searches predefined hyperparameter combinations within a specified search space.
It's simple but can be computationally expensive when the search space is large.

22/ Grid Search is a good choice when you have a limited number of hyperparameters to tune, and you want to explore all possible combinations.
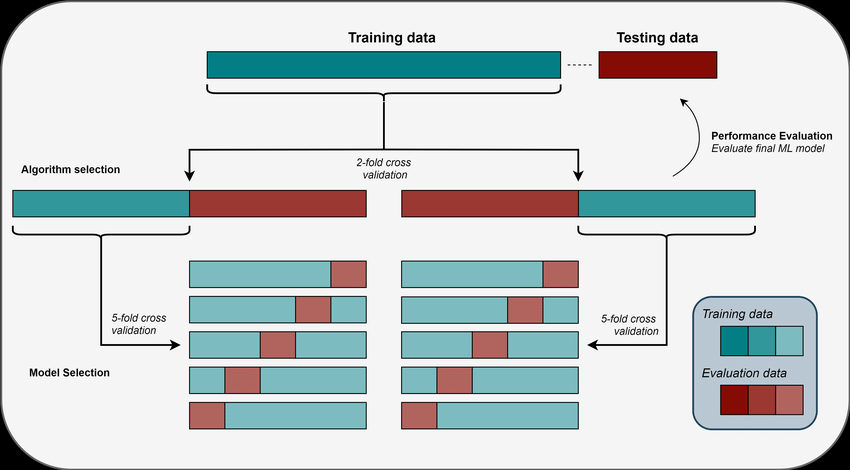
23/ Random Search:
Random Search randomly samples hyperparameters from specified distributions within the search space.
It's less computationally intensive than Grid Search while still providing good results.
Random Search randomly samples hyperparameters from specified distributions within the search space.
It's less computationally intensive than Grid Search while still providing good results.

24/ Random Search is suitable when you have a large search space, and you want to quickly explore a diverse set of hyperparameters.
• • •
Missing some Tweet in this thread? You can try to
force a refresh