Introducing StreamingLLM.
Imagine chatting with an AI assistant that can contextually reference your conversations from weeks or months ago. Or summarizing reports that span thousands of pages. StreamingLLM makes this possible by enabling language models to smoothly handle endless texts without losing steam.
Current LLMs are like students cramming for an exam - they can only memorize a limited context. StreamingLLM is the valedictorian with a photographic memory of everything you've ever discussed.
It works by identifying and preserving the model's inherent "attention sinks" - initial tokens that anchored its reasoning. Combined with a rolling cache of recent tokens, StreamingLLM delivers up to 22x faster inference without any drop in accuracy.
You know that irksome feeling when chatbots forget your earlier conversations? StreamingLLM abolishes that frustration. It remembers the touchdowns from your last game and your newborn's name without missing a beat.
Monumental books, verbose contracts, drawn out debates - StreamingLLM takes them all in its stride. No shortcuts, no forgetfulness. It's like upgrading your assistant's RAM to handle heavier workloads flawlessly.
Imagine chatting with an AI assistant that can contextually reference your conversations from weeks or months ago. Or summarizing reports that span thousands of pages. StreamingLLM makes this possible by enabling language models to smoothly handle endless texts without losing steam.
Current LLMs are like students cramming for an exam - they can only memorize a limited context. StreamingLLM is the valedictorian with a photographic memory of everything you've ever discussed.
It works by identifying and preserving the model's inherent "attention sinks" - initial tokens that anchored its reasoning. Combined with a rolling cache of recent tokens, StreamingLLM delivers up to 22x faster inference without any drop in accuracy.
You know that irksome feeling when chatbots forget your earlier conversations? StreamingLLM abolishes that frustration. It remembers the touchdowns from your last game and your newborn's name without missing a beat.
Monumental books, verbose contracts, drawn out debates - StreamingLLM takes them all in its stride. No shortcuts, no forgetfulness. It's like upgrading your assistant's RAM to handle heavier workloads flawlessly.
Key advantages of StreamingLLM over other approaches are:
- Enables infinite length streaming without needing to increase model capacity or fine-tune the model. Methods like expanding the attention window require substantially more compute for training larger models.
- Much more efficient than alternatives like sliding window with recomputation. StreamingLLM provides up to 22x speedup per token decoding.
- Stable performance on texts massively longer than training length. Matches performance of sliding window baseline on 4 million+ tokens.
- Simple and versatile. Easily incorporated into models with relative position encoding like RoPE or ALiBi.
- Pre-training with sink token further boosts streaming capability with just a single token.
- Decouples model pre-training length from actual generation length. Allows extending model use cases.
So in summary, StreamingLLM unlocks efficient and performant infinite-length streaming from pretrained LLMs without modulation, and is superior to other techniques on metrics like speed, compute overhead and length generalizability.

- Enables infinite length streaming without needing to increase model capacity or fine-tune the model. Methods like expanding the attention window require substantially more compute for training larger models.
- Much more efficient than alternatives like sliding window with recomputation. StreamingLLM provides up to 22x speedup per token decoding.
- Stable performance on texts massively longer than training length. Matches performance of sliding window baseline on 4 million+ tokens.
- Simple and versatile. Easily incorporated into models with relative position encoding like RoPE or ALiBi.
- Pre-training with sink token further boosts streaming capability with just a single token.
- Decouples model pre-training length from actual generation length. Allows extending model use cases.
So in summary, StreamingLLM unlocks efficient and performant infinite-length streaming from pretrained LLMs without modulation, and is superior to other techniques on metrics like speed, compute overhead and length generalizability.
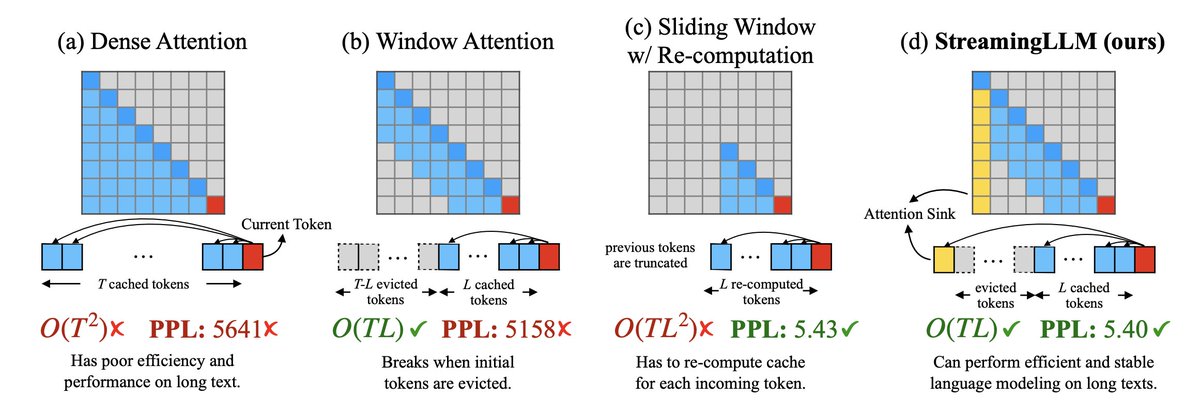
Here's the StreamingLLM method:
Background:
- Autoregressive language models are limited to contexts of finite length due to the quadratic self-attention complexity.
- Windowed attention partially addresses this by caching only the most recent tokens.
- However, window attention fails once initial tokens are removed from the cache.
Key Idea:
- Initial tokens act as "attention sinks", collecting scores irrespective of meaning due to the softmax normalization.
- Preserve these tokens alongside a rolling cache to stabilize attention distributions.
Approach:
- Split KV cache into two segments:
- Attention Sinks: Consists of the first 4 tokens of the sequence.
- Rolling Cache: Holds the most recent T tokens.
- For each new decoded token:
- Evict the oldest token from the rolling cache.
- Append the new token to the rolling cache.
- Compute self-attention over [Attention Sinks + Rolling Cache].
- Apply relative position encoding within the cache rather than full sequence.
Background:
- Autoregressive language models are limited to contexts of finite length due to the quadratic self-attention complexity.
- Windowed attention partially addresses this by caching only the most recent tokens.
- However, window attention fails once initial tokens are removed from the cache.
Key Idea:
- Initial tokens act as "attention sinks", collecting scores irrespective of meaning due to the softmax normalization.
- Preserve these tokens alongside a rolling cache to stabilize attention distributions.
Approach:
- Split KV cache into two segments:
- Attention Sinks: Consists of the first 4 tokens of the sequence.
- Rolling Cache: Holds the most recent T tokens.
- For each new decoded token:
- Evict the oldest token from the rolling cache.
- Append the new token to the rolling cache.
- Compute self-attention over [Attention Sinks + Rolling Cache].
- Apply relative position encoding within the cache rather than full sequence.
Okay enough elevator talk, where's the damn paper? arxiv.org/abs/2309.17453
Not yet impressed! Where's the damn source code? Here you go: github.com/mit-han-lab/st…
• • •
Missing some Tweet in this thread? You can try to
force a refresh