
If you'd asked me a year ago, superposition would have been by far the reason I was most worried that mechanistic interpretability would hit a dead end.
I'm now very optimistic. I'd go as far as saying it's now primarily an engineering problem -- hard, but less fundamental risk.
I'm now very optimistic. I'd go as far as saying it's now primarily an engineering problem -- hard, but less fundamental risk.
https://twitter.com/AnthropicAI/status/1709986949711200722
Well trained sparse autoencoders (scale matters!) can decompose a one-layer model into very nice, interpretable features.
They might not be 100% monosemantic, but they're damn close. We do detailed case studies and I feel comfortable saying they're at least as monosemantic as InceptionV1 curve detectors (). distill.pub/2020/circuits/…


But it's not just cherry picked features. The vast majority of the features are this nice. And you can check for yourself - we published all the features in an interface you can use to explore them!
transformer-circuits.pub/2023/monoseman…
transformer-circuits.pub/2023/monoseman…

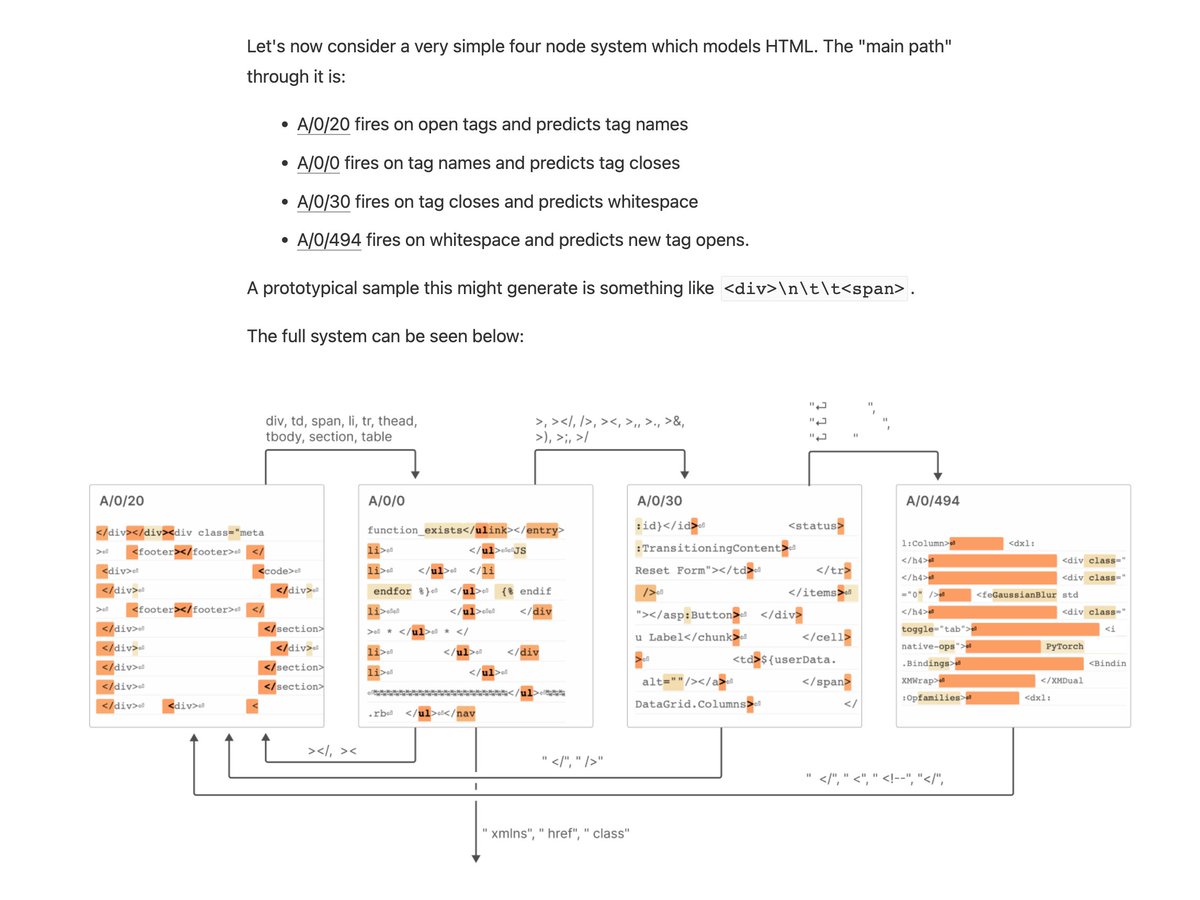
There's a lot that could be said, but one of the coolest things to me was that we found "finite state automata"-like assemblies of features. The simplest case is features which cause themselves to fire more.
(Keep in mind that this is a small one-layer model -- it's dumb!)
(Keep in mind that this is a small one-layer model -- it's dumb!)

A slightly more complex system models "all caps snake case" variables.

This four node system models HTML.
And this one IRC messages
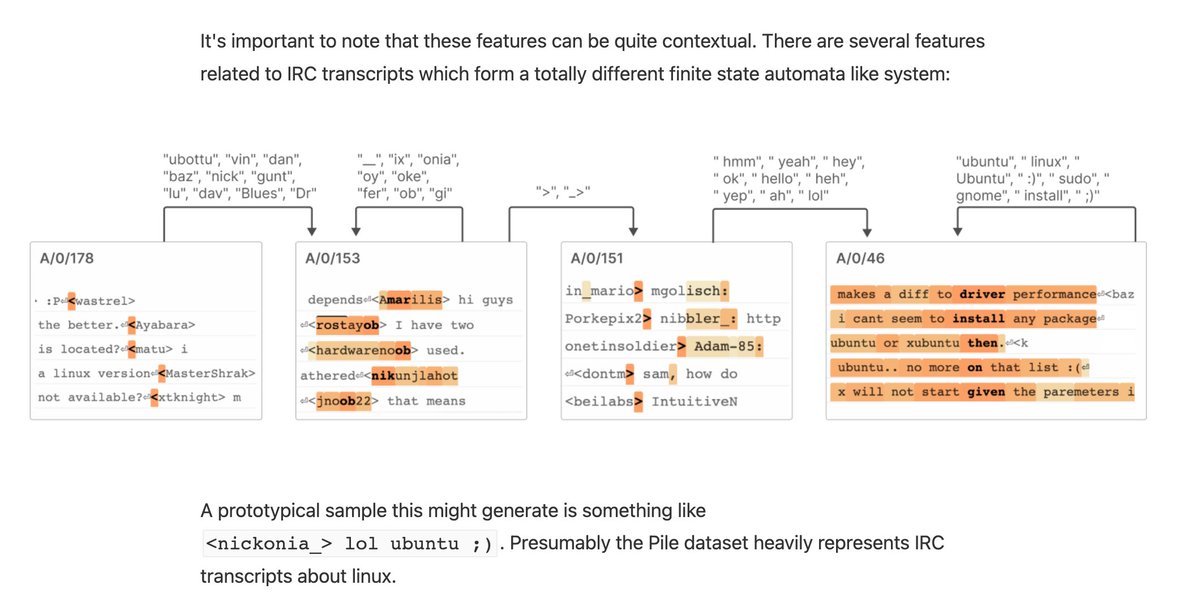
It's also worth noting that this is part of a broader trend of a lot of recent progress on attacking superposition. I'd especially highlight contemporaneous work by Cunningham et al which has some really nice confirmatory results:
https://twitter.com/HoagyCunningham/status/1704882738526871767
OK, one other thing I can't resist adding is that we found region neurons (eg. Australia, Canada, Africa, etc neurons) similar to these old results in CLIP () and also to the recent results by @wesg52 et al ().
Universality!
Universality!
https://twitter.com/ch402/status/1368652791414091777
https://twitter.com/wesg52/status/1709551516577902782
Sorry, the link above was incorrect. It should have been transformer-circuits.pub/2023/monoseman…
There's much, much more in the paper (would it really be an Anthropic interpretability paper if it wasn't 100+ pages??), but I'll let you actually look at it:
transformer-circuits.pub/2023/monoseman…
transformer-circuits.pub/2023/monoseman…
@zefu_superhzf (2) Although we can understand attention heads, I suspect that something like "attention head superposition" is going on and that we could give a simpler explanation if we could resolve it.
@zefu_superhzf See more discussion in paper.
@SussilloDavid I once saw a paper (from Surya Ganguli?) that suggested maybe the brain does compressed sensing when communicating between different regions through bottlenecks.
This is much closer to the thing we're imagining with superposition!
This is much closer to the thing we're imagining with superposition!
@SussilloDavid but the natural extension of this is that actually, maybe all neural activations are in a compressed form (and then the natural thing to do is dictionary learning)
@SussilloDavid I'd be very curious to know what happens if someone takes biological neural recorings over lots of data and does a dictionary learning / sparse autoencoder expansion..
@SussilloDavid I think superposition is much more specific. You can think of it as a sub-type of "distributed representation". I tried to pin this down here: transformer-circuits.pub/2023/superposi…
• • •
Missing some Tweet in this thread? You can try to
force a refresh









