
A wave of new work shows how **brittle** "Alignment"/RLHF safety methods are.
⛓️ Prompt jailbreaks are easy
🚂 Finetuning away safety (even #OpenAI API) is simple and likely undetectable
🤖 LLMs can auto-generate their own jailbreaks...
1/ 🧵
⛓️ Prompt jailbreaks are easy
🚂 Finetuning away safety (even #OpenAI API) is simple and likely undetectable
🤖 LLMs can auto-generate their own jailbreaks...
1/ 🧵
It's been repeatedly shown that careful prompt re-wording, roleplaying, and even just insisting can jailbreak Llama2-Chat/#ChatGPT usage policy ().
, @AIPanicLive document many jailbreak / red teaming efforts
2/openai.com/policies/usage…
jailbreakchat.com
, @AIPanicLive document many jailbreak / red teaming efforts
2/openai.com/policies/usage…
jailbreakchat.com
@kothasuhas,@AdtRaghunathan, @jacspringer shown Conjugate prompts can often recover behavior pre-finetune/RLHF.
➡️ Finetuning suppresses rather than forgets behavior
➡️ This includes harmful behavior
➡️ So clever prompting can recover it
3/
➡️ Finetuning suppresses rather than forgets behavior
➡️ This includes harmful behavior
➡️ So clever prompting can recover it
3/
https://x.com/kothasuhas/status/1704294056455458906
➡️ Eg, translating to non-English is **more successful** at eliciting harm.
...they show potential harms are much more pervasive outside of English
4/
...they show potential harms are much more pervasive outside of English
4/


@Qnolan4 shows 100 examples / 1 hour finetuning "can subvert safely aligned models to adapt to harmful tasks without sacrificing model helpfulness."
6/
6/
https://x.com/Qnolan4/status/1710171247500476689
@xiangyuqi_pton,@EasonZeng623,@VitusXie,@PeterHndrsn++ show:
This isn't only for open models like Llama2-Chat.
1⃣ They remove @OpenAI's GPT-3.5 Finetune API safety guardrails by fine-tuning it on only 🔟‼️ harmful examples!
7/
This isn't only for open models like Llama2-Chat.
1⃣ They remove @OpenAI's GPT-3.5 Finetune API safety guardrails by fine-tuning it on only 🔟‼️ harmful examples!
7/
https://x.com/xiangyuqi_pton/status/1710794400564224288

2⃣ They show larger **implicitly** harmful datasets can be used without triggering OpenAI's Moderation system.
3⃣ Even completely "benign" datasets can unintentionally strip safety measures.
8/llm-tuning-safety.github.io
3⃣ Even completely "benign" datasets can unintentionally strip safety measures.
8/llm-tuning-safety.github.io
Lastly, @dataisland99,@xingxinyu++ show LLMs can be useful in automatically and iteratively generating their own jailbreaks.
This offers incredible potential for supplementing human Red Teaming efforts!
9/
This offers incredible potential for supplementing human Red Teaming efforts!
9/
https://x.com/llm_sec/status/1709892224551367038
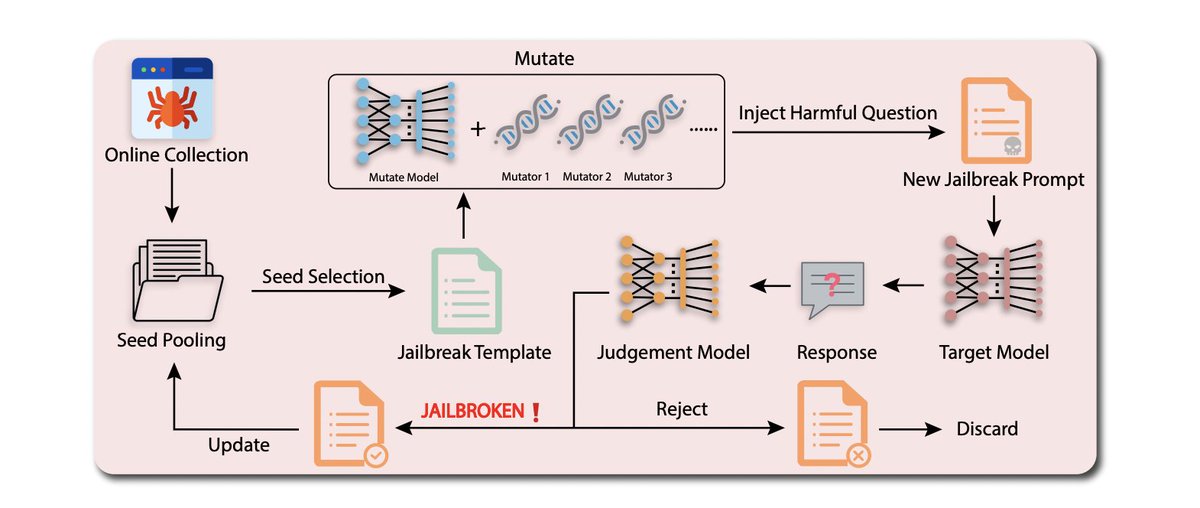
Altogether, these important works can have a few implications.
1⃣ Calls to require RLHF on all released models may only offer shallow safety.
2⃣ "Closed" models may be as susceptible as "open" models.
10/
1⃣ Calls to require RLHF on all released models may only offer shallow safety.
2⃣ "Closed" models may be as susceptible as "open" models.
10/
To expand on (2):
➡️ prompting jailbreaks remain trivial
➡️ implicit and unintentionally harmful finetuning datasets easily and cheaply break current safety measures
11/
➡️ prompting jailbreaks remain trivial
➡️ implicit and unintentionally harmful finetuning datasets easily and cheaply break current safety measures
11/
3⃣ We may need to re-prioritize safety mechanisms, or what kinds of jailbreaks really matter.
E.g. if we are worried about sharing sensitive weapon building knowledge, perhaps don't train on that knowledge?
12/
E.g. if we are worried about sharing sensitive weapon building knowledge, perhaps don't train on that knowledge?
12/
4⃣ Academic research (these works) are driving AI safety understanding immensely.
Proposal: We need continued (un-gatekeeped) access for academics, without account bans or corporations selectively deciding who gets to do it and in what capacity.
A "safe harbor".
13/
Proposal: We need continued (un-gatekeeped) access for academics, without account bans or corporations selectively deciding who gets to do it and in what capacity.
A "safe harbor".
13/
Thank you for reading and please don't hesitate to leave comments if I missed anything, or got something wrong! 🙂
🧵/
🧵/
• • •
Missing some Tweet in this thread? You can try to
force a refresh



















