


Framing biology in terms of design patterns provides several key benefits:
1. Design patterns identify recurrent solutions to common problems in biology. They represent conserved functional behaviors that evolve again and again.
2. Patterns provide abstraction that helps reveal overarching principles. Rather than getting lost in molecular details, patterns highlight conceptual themes.
3. Patterns facilitate comparative analyses between different biological systems. They provide a common language for recognizing similarities amidst diversity.
4. Patterns suggest approaches for engineering or manipulating biology, since they capture successful strategies evolution has converged on.
5. Thinking in terms of patterns guides modeling efforts. Models that embody design patterns will better capture the capabilities of biological systems.
6. Patterns represent simplifying themes that aid comprehension and memory. It's easier to learn and reason about a few key patterns than endless specifics.
7. Identifying patterns fosters systems thinking. It requires zooming out from components to consider entire system behaviors and why they arise.
8. Patterns may point to universal principles governing all biochemical cells, even on other planets. The same problems recur everywhere.
In summary, design patterns provide abstraction, simplification, unification, comparability, mimicry, comprehension, prediction, and perhaps universality. These benefits can aid both biology research and applications.
1. Design patterns identify recurrent solutions to common problems in biology. They represent conserved functional behaviors that evolve again and again.
2. Patterns provide abstraction that helps reveal overarching principles. Rather than getting lost in molecular details, patterns highlight conceptual themes.
3. Patterns facilitate comparative analyses between different biological systems. They provide a common language for recognizing similarities amidst diversity.
4. Patterns suggest approaches for engineering or manipulating biology, since they capture successful strategies evolution has converged on.
5. Thinking in terms of patterns guides modeling efforts. Models that embody design patterns will better capture the capabilities of biological systems.
6. Patterns represent simplifying themes that aid comprehension and memory. It's easier to learn and reason about a few key patterns than endless specifics.
7. Identifying patterns fosters systems thinking. It requires zooming out from components to consider entire system behaviors and why they arise.
8. Patterns may point to universal principles governing all biochemical cells, even on other planets. The same problems recur everywhere.
In summary, design patterns provide abstraction, simplification, unification, comparability, mimicry, comprehension, prediction, and perhaps universality. These benefits can aid both biology research and applications.
Creational design patterns
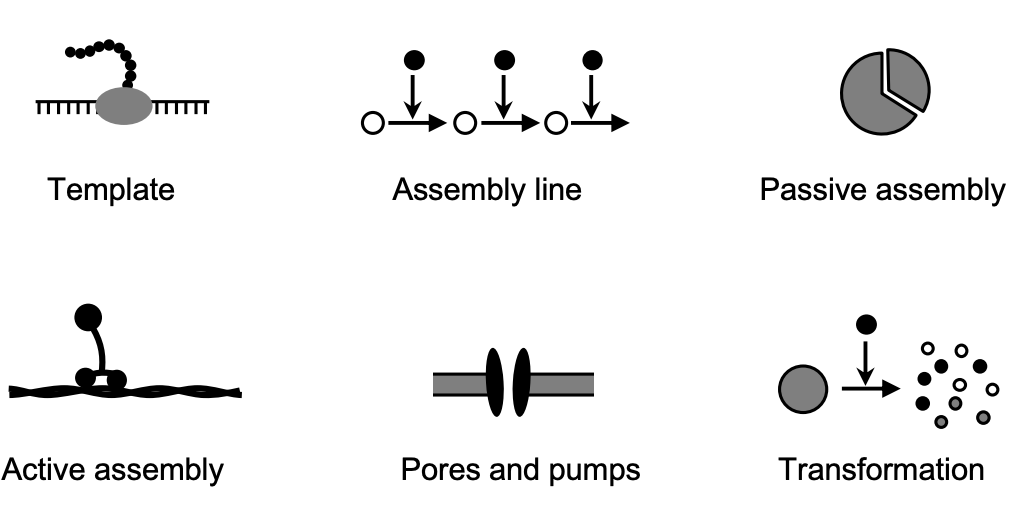
Template - Biosynthesis using a master copy as a template (e.g. DNA replication, transcription, translation). Includes kinetic proofreading for accuracy.
Assembly Line - Stepwise biosynthesis using a series of enzymes, like metabolic pathways. Requires negative feedback regulation.
Passive Assembly - Self-assembly due to favorable thermodynamics and random diffusion. Reversible. Examples are protein folding, dimerization, phase separations.
Active Assembly - Assembly requiring energy input and assistance from other cell components. Irreversible. Examples are chaperone-assisted folding, vesicle formation, cytoskeletal growth.
Pores and Pumps - Transport of molecules across membranes via passive and active transport through pores, channels, and pumps. Provides compartmentalization.
Transformation - Enzymatic degradation or modification of cellular components like proteins, lipids, nucleic acids. Tightly regulated. Includes protein cleavage and ubiquitination.
In summary, the creational patterns represent different mechanisms cells use to construct the molecules, structures and organizational features they need for life. They build up the physical composition of the cell.

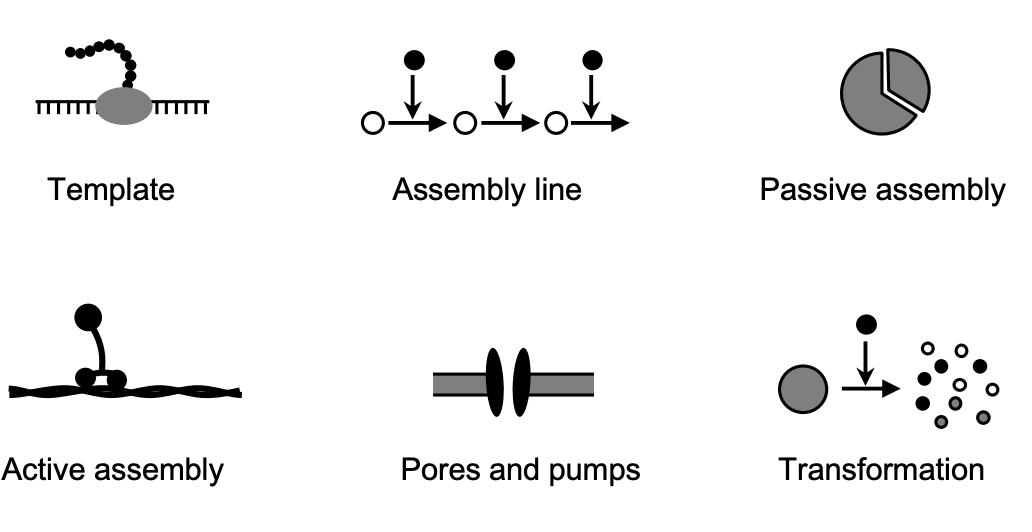
Template - Biosynthesis using a master copy as a template (e.g. DNA replication, transcription, translation). Includes kinetic proofreading for accuracy.
Assembly Line - Stepwise biosynthesis using a series of enzymes, like metabolic pathways. Requires negative feedback regulation.
Passive Assembly - Self-assembly due to favorable thermodynamics and random diffusion. Reversible. Examples are protein folding, dimerization, phase separations.
Active Assembly - Assembly requiring energy input and assistance from other cell components. Irreversible. Examples are chaperone-assisted folding, vesicle formation, cytoskeletal growth.
Pores and Pumps - Transport of molecules across membranes via passive and active transport through pores, channels, and pumps. Provides compartmentalization.
Transformation - Enzymatic degradation or modification of cellular components like proteins, lipids, nucleic acids. Tightly regulated. Includes protein cleavage and ubiquitination.
In summary, the creational patterns represent different mechanisms cells use to construct the molecules, structures and organizational features they need for life. They build up the physical composition of the cell.
Structural design patterns
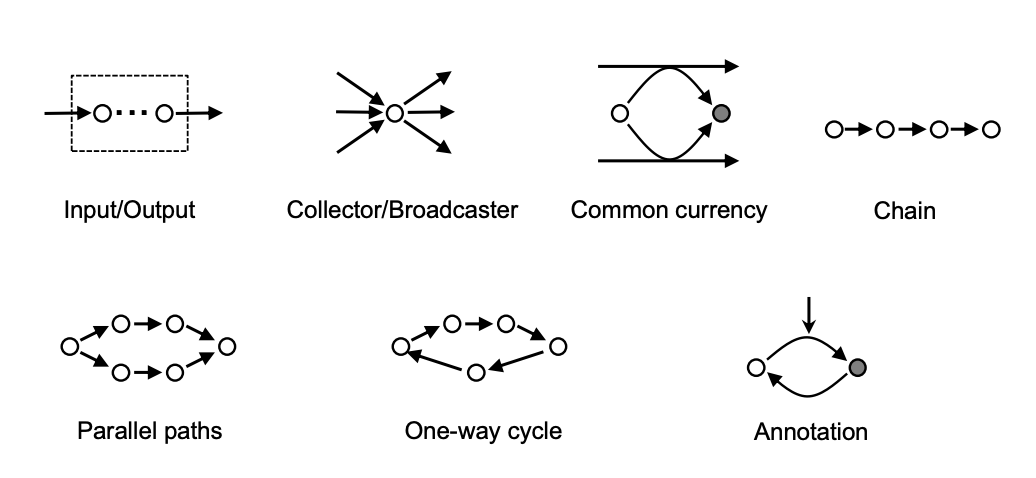
Input/Output - Elements that input material/information from environment and output material/information to serve a purpose. Examples are transporters in metabolism, receptors in signaling.
Collector/Broadcaster - Convergence and divergence of information flow through master regulators. Examples are transcription factors, TOR proteins, hormones.
Common Currency - Use of a few standard energy/chemical sources repeatedly, like ATP, NADH. Related to bow tie architecture.
Chain - Linear sequence of reactions, like metabolic pathways or signaling cascades.
Parallel Paths - Multiple complementary pathways, like aerobic/anaerobic metabolism or signaling feedforward loops.
One-way Cycle - Circular pathway with return of downstream products to upstream to sustain the cycle. Examples are TCA cycle, cell cycle.
Annotation - Reversible covalent or noncovalent modification of proteins or DNA to represent information. Example is phosphorylation.
In summary, the structural patterns represent network connectivity motifs that solve problems of system inputs/outputs, information consolidation, substrate channeling, versatility, and temporal records.
Input/Output - Elements that input material/information from environment and output material/information to serve a purpose. Examples are transporters in metabolism, receptors in signaling.
Collector/Broadcaster - Convergence and divergence of information flow through master regulators. Examples are transcription factors, TOR proteins, hormones.
Common Currency - Use of a few standard energy/chemical sources repeatedly, like ATP, NADH. Related to bow tie architecture.
Chain - Linear sequence of reactions, like metabolic pathways or signaling cascades.
Parallel Paths - Multiple complementary pathways, like aerobic/anaerobic metabolism or signaling feedforward loops.
One-way Cycle - Circular pathway with return of downstream products to upstream to sustain the cycle. Examples are TCA cycle, cell cycle.
Annotation - Reversible covalent or noncovalent modification of proteins or DNA to represent information. Example is phosphorylation.
In summary, the structural patterns represent network connectivity motifs that solve problems of system inputs/outputs, information consolidation, substrate channeling, versatility, and temporal records.
Behavioral design patterns
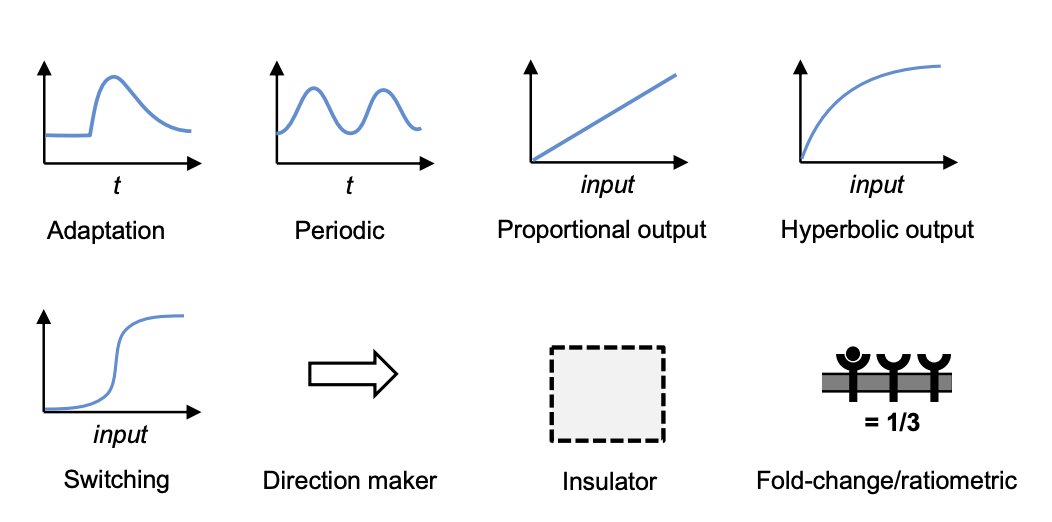
Adaptation - Return to baseline after a perturbation, through negative feedback. Achieves homeostasis/tolerance. Examples are osmoregulation and chemotaxis.
Periodic - Networks that produce oscillations, like cell cycle and circadian clocks. Require negative feedback with time delay.
Proportional Output - Linear input-output relation over a range. Improves information transmission. Achieved through negative or feedforward feedback.
Hyperbolic Output - Response saturates at high input levels. Maintains sensitivity over wide range. Caused by enzyme saturation.
Switching - Ultrasensitive all-or-none response. Produced by multistep phosphorylation, positive feedback.
Direction Maker - Reactions driven in one direction by energetics or substrate/product ratios. Example is ATP hydrolysis.
Insulator - Boundaries that isolate subnetworks, through localization, standardized connections, amplification/feedback. Improves modularity.
Fold-Change Detection - Output depends on fractional change in input, not absolute levels. Examples are chemotaxis, NF-kB, and Wnt pathways.
In summary, the behavioral patterns represent dynamics that enable adaptation, rhythmicity, information transmission, sensitivity, decision thresholds, irreversibility, modularity, and fractional sensing.
Adaptation - Return to baseline after a perturbation, through negative feedback. Achieves homeostasis/tolerance. Examples are osmoregulation and chemotaxis.
Periodic - Networks that produce oscillations, like cell cycle and circadian clocks. Require negative feedback with time delay.
Proportional Output - Linear input-output relation over a range. Improves information transmission. Achieved through negative or feedforward feedback.
Hyperbolic Output - Response saturates at high input levels. Maintains sensitivity over wide range. Caused by enzyme saturation.
Switching - Ultrasensitive all-or-none response. Produced by multistep phosphorylation, positive feedback.
Direction Maker - Reactions driven in one direction by energetics or substrate/product ratios. Example is ATP hydrolysis.
Insulator - Boundaries that isolate subnetworks, through localization, standardized connections, amplification/feedback. Improves modularity.
Fold-Change Detection - Output depends on fractional change in input, not absolute levels. Examples are chemotaxis, NF-kB, and Wnt pathways.
In summary, the behavioral patterns represent dynamics that enable adaptation, rhythmicity, information transmission, sensitivity, decision thresholds, irreversibility, modularity, and fractional sensing.
A. Design Patterns Provide Abstraction and Reveal Common Solutions
- Design patterns encourage abstraction of biochemical networks into generalized behaviors and solutions.
- This allows parallels and differences between systems to be better recognized.
- Provides understanding of the functional "tools" cells have available and why mechanisms operate as they do.
- Facilitates identification of recurring problems and conserved solutions across biology.
B. Can Also Apply Patterns More Narrowly
- Design patterns can be identified at various levels, from specific molecules to multi-cellular organisms.
- This paper focuses on reaction networks in individual cells.
- But patterns could also be applied more narrowly, e.g. to the components of one signaling pathway.
- The EGFR/ERK pathway could be deconstructed into hierarchical and interlinked patterns for better understanding.
C. Connects Back to Computer Science Origins
- Design patterns originated in computer science to capture common programming solutions.
- This raises the question of what capabilities are needed for whole cell simulations.
- The biological design patterns represent solutions such simulations would need to incorporate.
- AI/ML methods could also potentially identify patterns automatically from network data.
D. Suggests Universal Principles of Biochemical Cells
- Cells face recurring problems of constructing components, connecting them, and animating behaviors.
- The solutions are design patterns that may be universal principles of life.
- If biochemical cells evolved again, the same problems and solutions would likely arise.
- Even alien life may exhibit the same patterns, as they reflect fundamental constraints.
- The patterns may constitute organizational principles that self-assemble in any biochemical cell.
- Design patterns encourage abstraction of biochemical networks into generalized behaviors and solutions.
- This allows parallels and differences between systems to be better recognized.
- Provides understanding of the functional "tools" cells have available and why mechanisms operate as they do.
- Facilitates identification of recurring problems and conserved solutions across biology.
B. Can Also Apply Patterns More Narrowly
- Design patterns can be identified at various levels, from specific molecules to multi-cellular organisms.
- This paper focuses on reaction networks in individual cells.
- But patterns could also be applied more narrowly, e.g. to the components of one signaling pathway.
- The EGFR/ERK pathway could be deconstructed into hierarchical and interlinked patterns for better understanding.
C. Connects Back to Computer Science Origins
- Design patterns originated in computer science to capture common programming solutions.
- This raises the question of what capabilities are needed for whole cell simulations.
- The biological design patterns represent solutions such simulations would need to incorporate.
- AI/ML methods could also potentially identify patterns automatically from network data.
D. Suggests Universal Principles of Biochemical Cells
- Cells face recurring problems of constructing components, connecting them, and animating behaviors.
- The solutions are design patterns that may be universal principles of life.
- If biochemical cells evolved again, the same problems and solutions would likely arise.
- Even alien life may exhibit the same patterns, as they reflect fundamental constraints.
- The patterns may constitute organizational principles that self-assemble in any biochemical cell.
These are inspiring patterns and you have to wonder how they may relate to patterns in Artificial Fluency (i.e., Large Language Models). intuitionmachine.gumroad.com/l/gpt4
• • •
Missing some Tweet in this thread? You can try to
force a refresh