✅Feature selection and Feature scaling are crucial Feature Engineering steps - Explained in Simple terms.
A quick thread 👇🏻🧵
#MachineLearning #Coding #100DaysofCode #deeplearning #DataScience
PC : Research Gate
A quick thread 👇🏻🧵
#MachineLearning #Coding #100DaysofCode #deeplearning #DataScience
PC : Research Gate
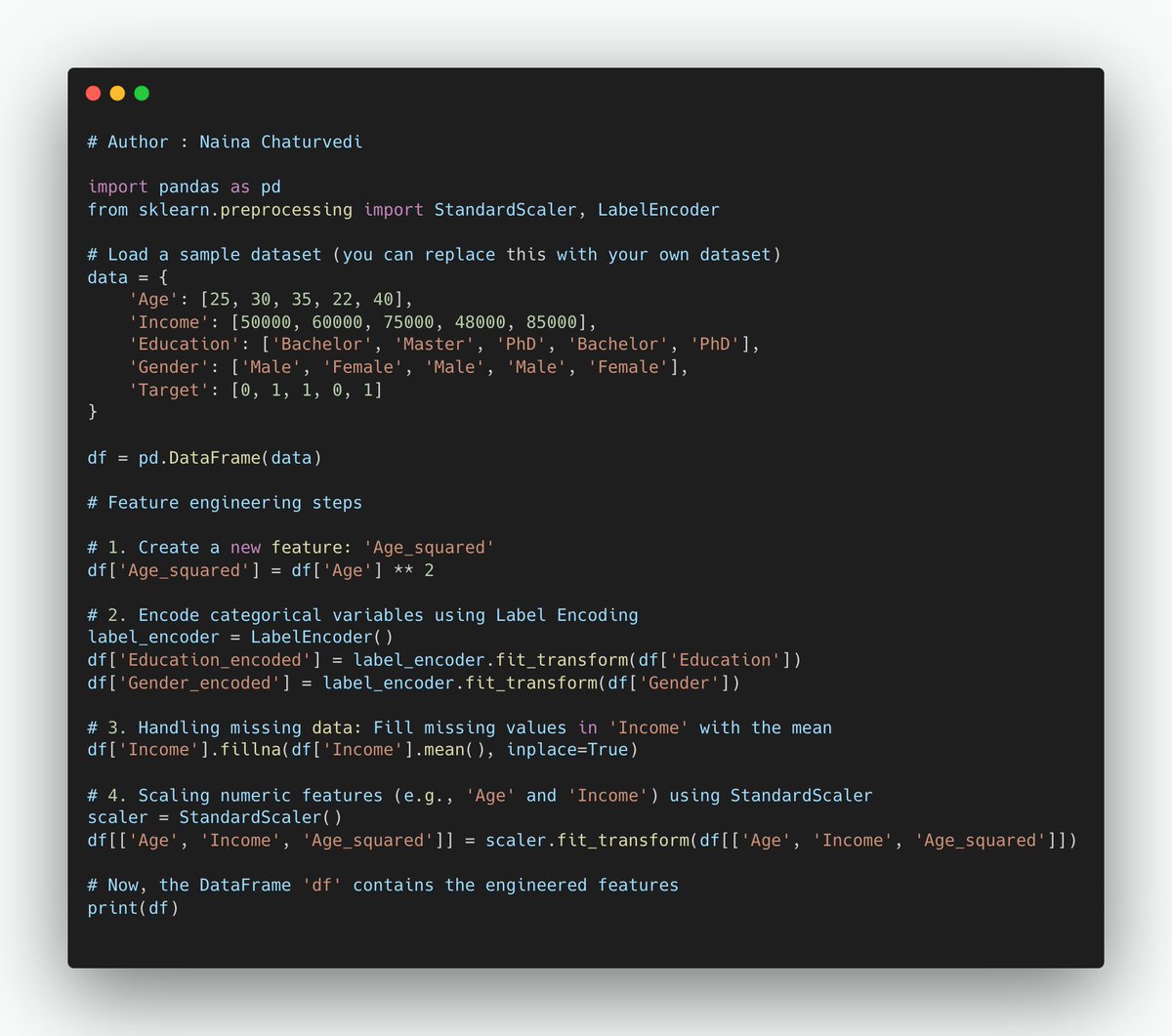
1/ Feature selection is the process of choosing a subset of the most relevant features (variables or columns) from your dataset. It involves excluding less informative or redundant features to improve model performance and reduce computational complexity.

2/ When to Use It:
High-Dimensional Data: Feature selection is crucial when you have a high-dimensional dataset, meaning there are many features compared to the number of data points. High dimensionality can lead to overfitting and increased computational costs.
High-Dimensional Data: Feature selection is crucial when you have a high-dimensional dataset, meaning there are many features compared to the number of data points. High dimensionality can lead to overfitting and increased computational costs.

3/ Multicollinearity: When features in your dataset are highly correlated (multicollinearity), it's challenging for models to differentiate their individual effects. Feature selection helps address this issue by choosing the most informative features.
4/ Improve Model Efficiency: In cases where you have a limited amount of computational resources or time, reducing the number of features through selection can lead to faster model training and evaluation.

5/ Why to Use It:
Improved Model Performance: Feature selection can lead to models with better generalization and reduced overfitting, as they focus on the most relevant information.
Improved Model Performance: Feature selection can lead to models with better generalization and reduced overfitting, as they focus on the most relevant information.
6/ Feature scaling (or feature normalization) is process of standardizing or scaling values of different features to bring them to a common scale or distribution. It ensures that magnitudes of features do not disproportionately influence certain machine learning algorithms.
7/ When to Use It:
Model Sensitivity to Feature Magnitudes: Some machine learning models, like k-Nearest Neighbors (KNN) and Support Vector Machines (SVM), are sensitive to magnitudes of features. In such cases, feature scaling is critical to make algorithm work effectively.
Model Sensitivity to Feature Magnitudes: Some machine learning models, like k-Nearest Neighbors (KNN) and Support Vector Machines (SVM), are sensitive to magnitudes of features. In such cases, feature scaling is critical to make algorithm work effectively.
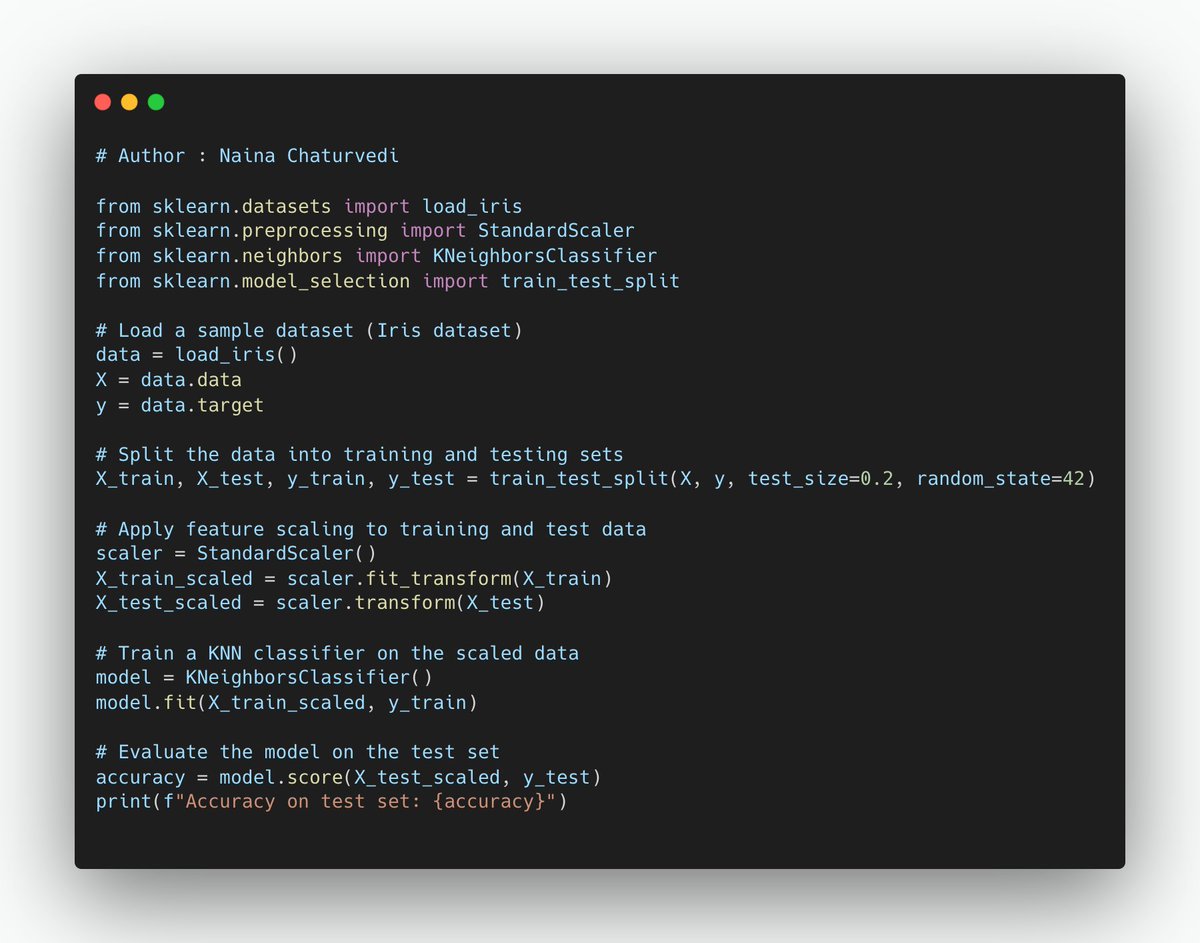
8/ Comparing Features on Different Scales: When different features have different scales or units (e.g., age in years vs. income in thousands of dollars), feature scaling helps make features comparable.

9/ Why to Use It:
Improved Model Performance: Feature scaling ensures that all features contribute equally to the model's predictions. Without scaling, features with larger magnitudes can dominate the learning process.
Improved Model Performance: Feature scaling ensures that all features contribute equally to the model's predictions. Without scaling, features with larger magnitudes can dominate the learning process.
10/ Faster Convergence: In algorithms like gradient-based optimization, feature scaling can lead to faster convergence, as it helps the optimization process.
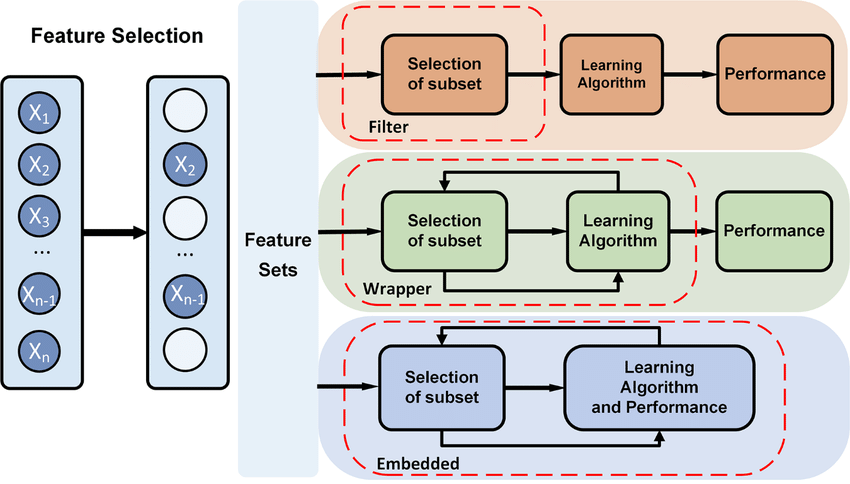
11/ Types of Feature Selection:
Filter methods involve evaluating the relevance of features based on their intrinsic properties, such as statistical measures or correlation with the target variable. These methods do not consider the machine learning model's performance.
Filter methods involve evaluating the relevance of features based on their intrinsic properties, such as statistical measures or correlation with the target variable. These methods do not consider the machine learning model's performance.
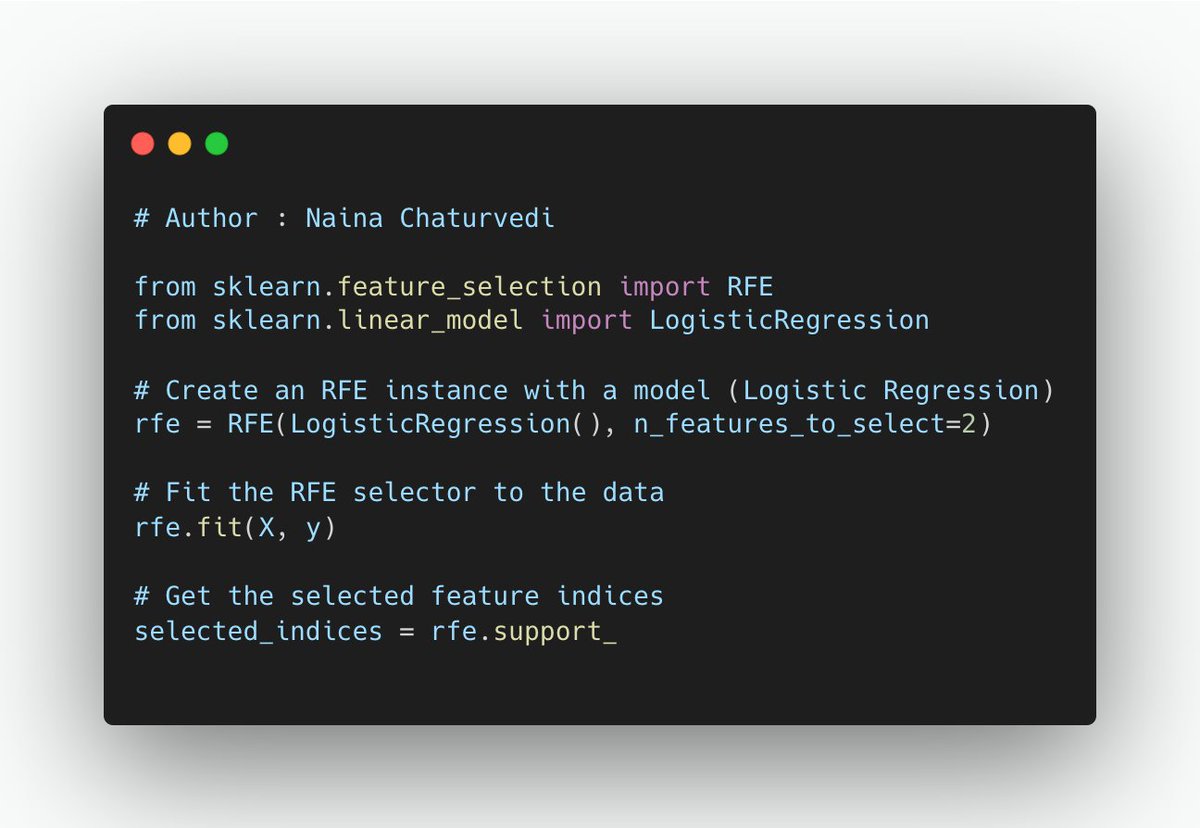
12/ Wrapper methods evaluate feature subsets by training and testing a machine learning model with each subset. These methods are computationally expensive but can provide the best feature subset for a specific model.
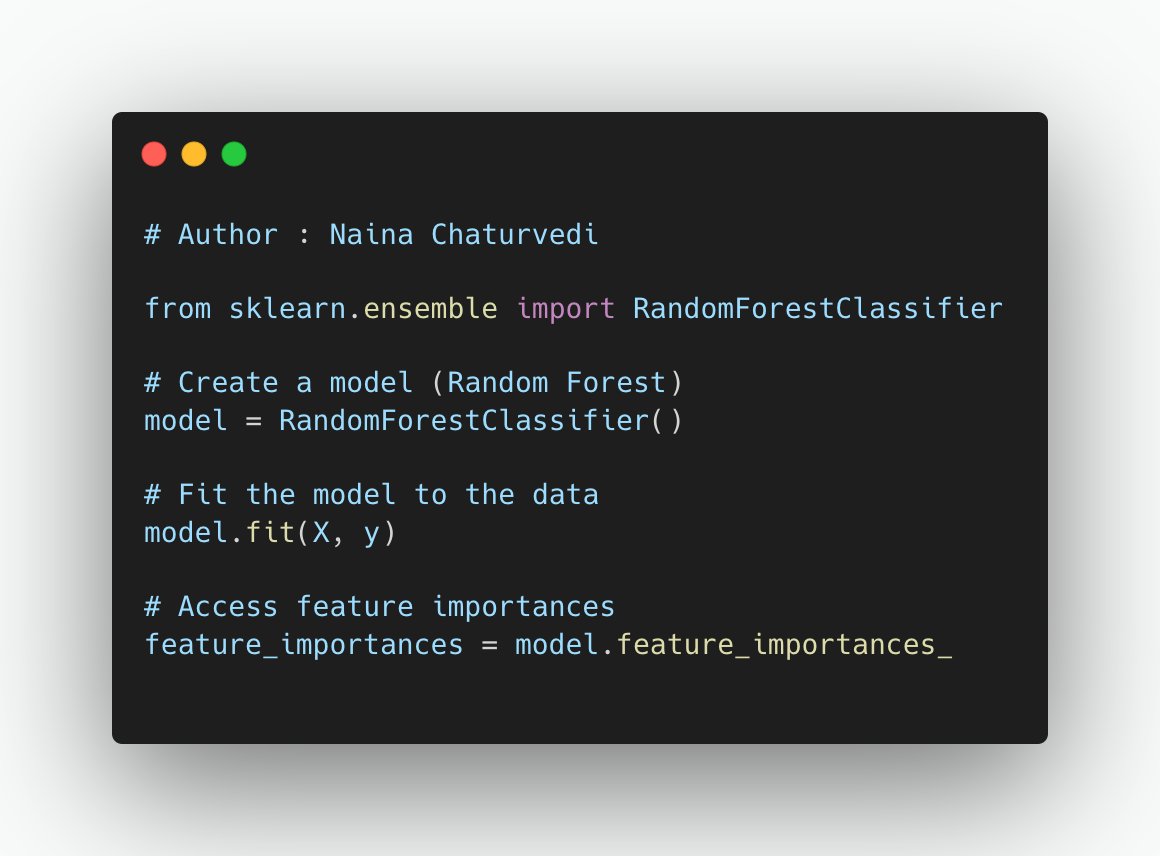
13/ Embedded methods incorporate feature selection into the model training process. Feature importance is determined as the model is being built, and less important features are pruned.
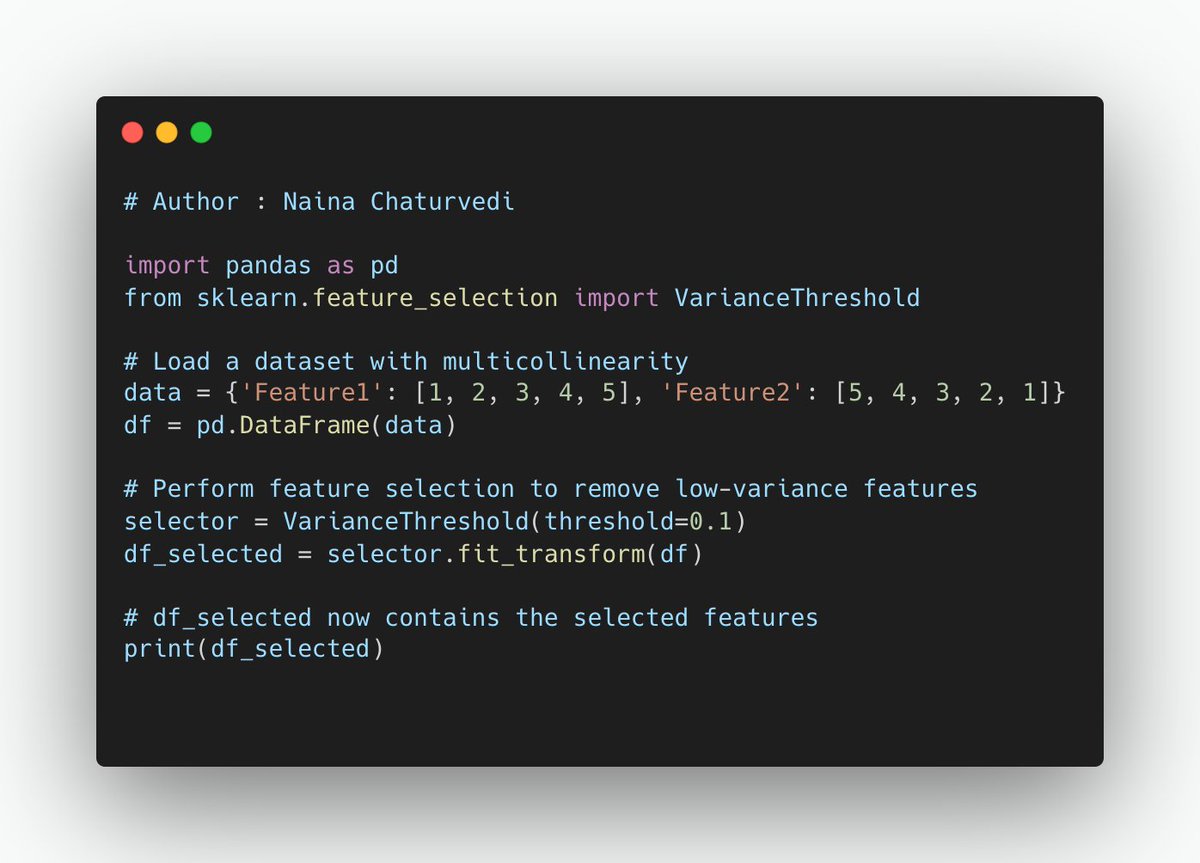
14/ Filter methods -
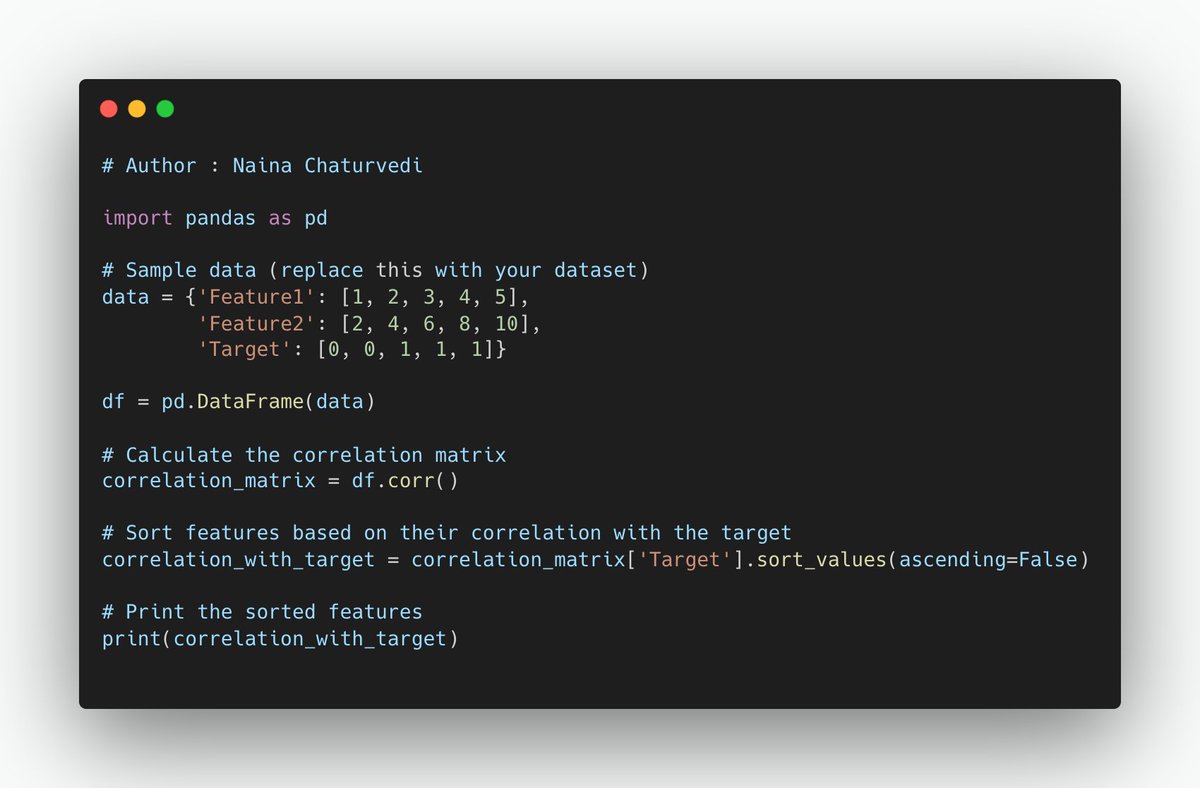
Correlation measures the linear relationship between two numerical variables. In feature selection, you can compute the correlation between each feature and the target variable. Features with a high correlation with the target are considered relevant.
Correlation measures the linear relationship between two numerical variables. In feature selection, you can compute the correlation between each feature and the target variable. Features with a high correlation with the target are considered relevant.
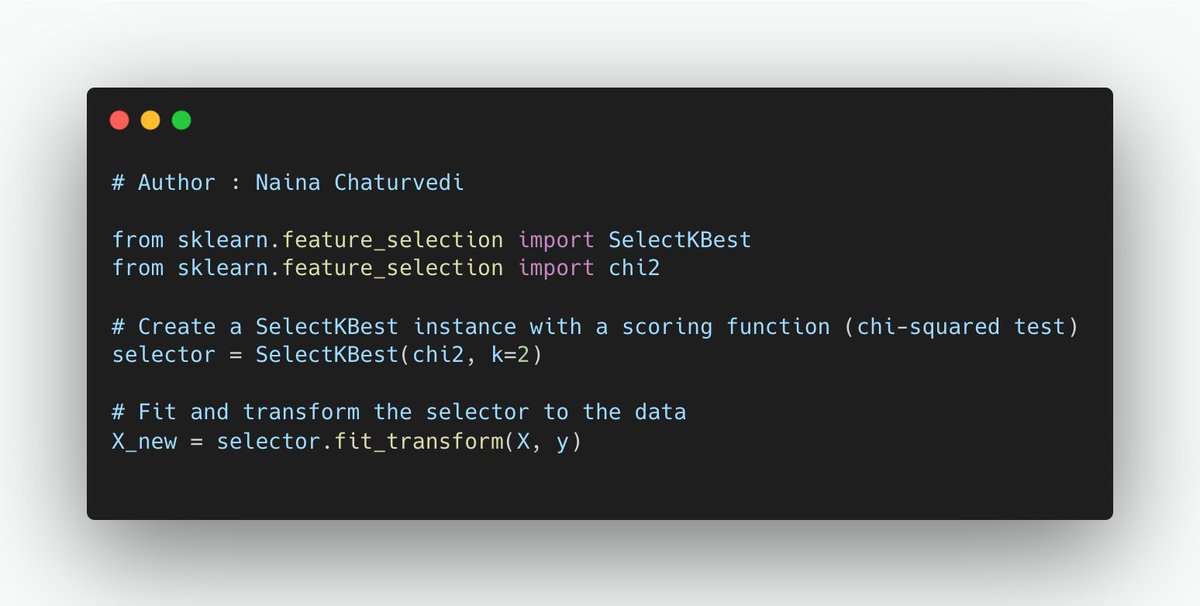
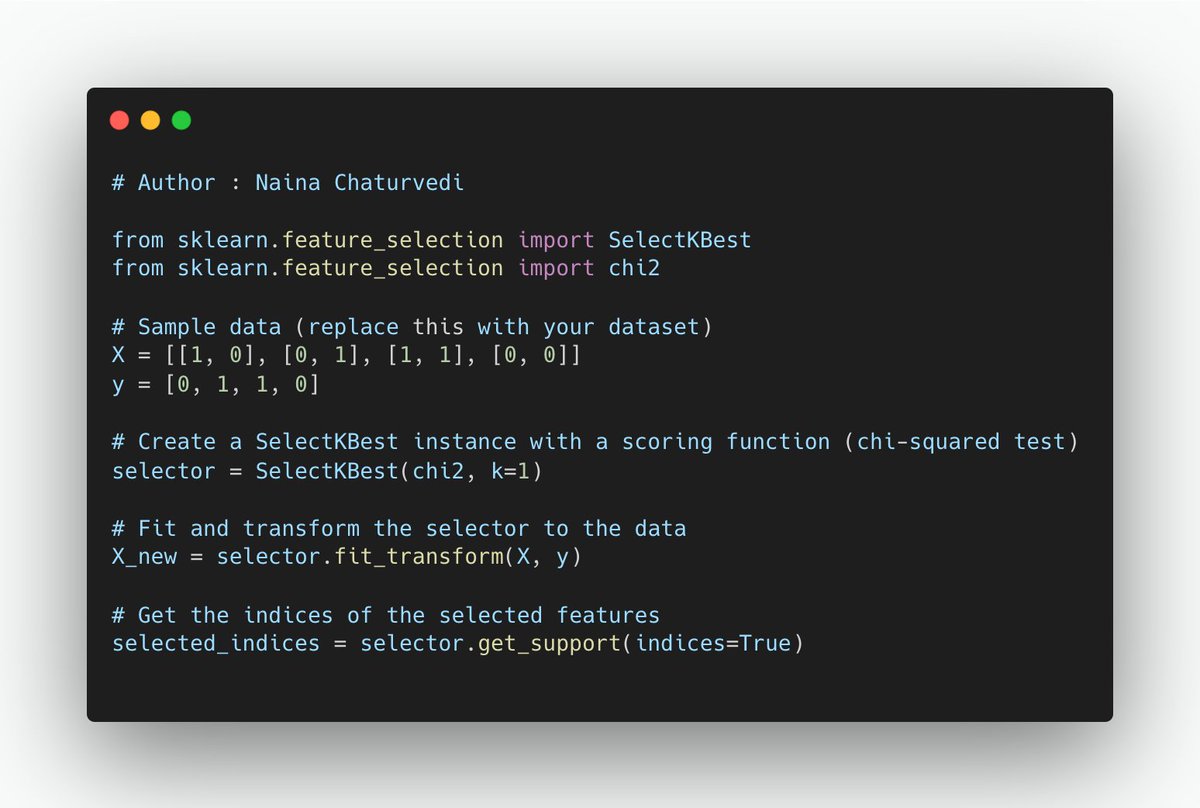
15/ The chi-squared test assesses the statistical dependence between two categorical variables. In feature selection, you can use the chi-squared test to measure the independence of each categorical feature from the target variable.
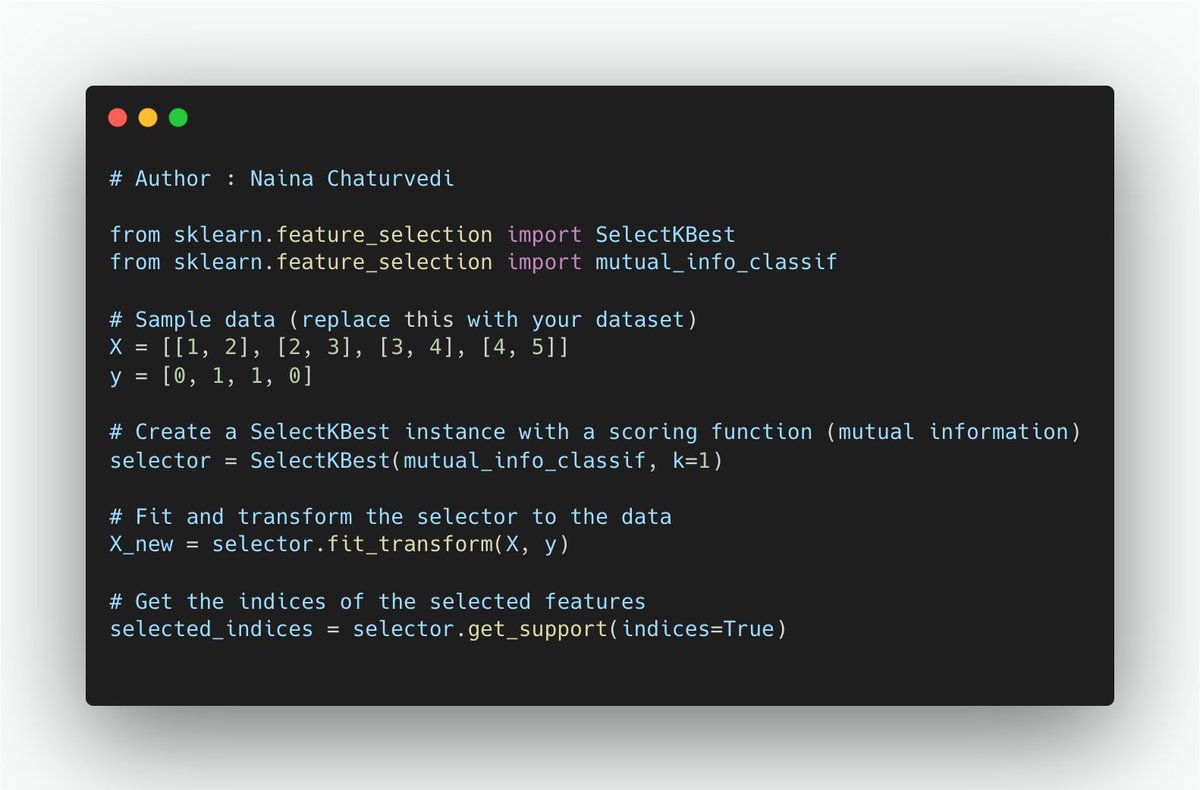
16/ Mutual information measures the amount of information shared between two variables. In feature selection, you can compute the mutual information between each feature and the target variable. Features with high mutual information are considered relevant.
17/ Wrapper Methods:
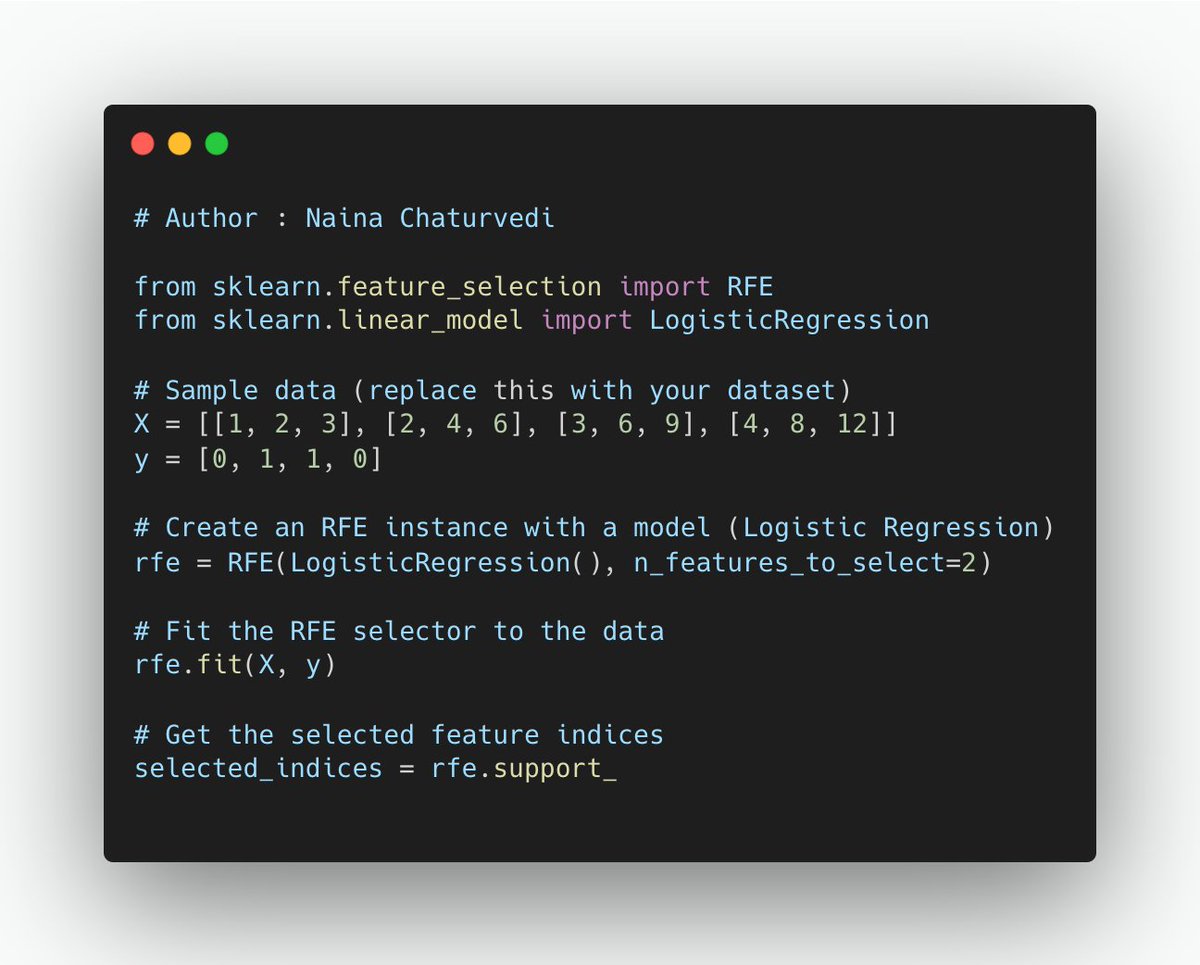
RFE is an iterative method that starts with all features and removes the least important feature in each iteration based on model performance. The process continues until the desired number of features is achieved or until performance deteriorates.
RFE is an iterative method that starts with all features and removes the least important feature in each iteration based on model performance. The process continues until the desired number of features is achieved or until performance deteriorates.
18/ Forward and backward selection methods are stepwise feature selection techniques. Forward selection starts with an empty set of features and adds one feature at a time based on model performance. Backward selection begins with all features and removes one feature at a time.
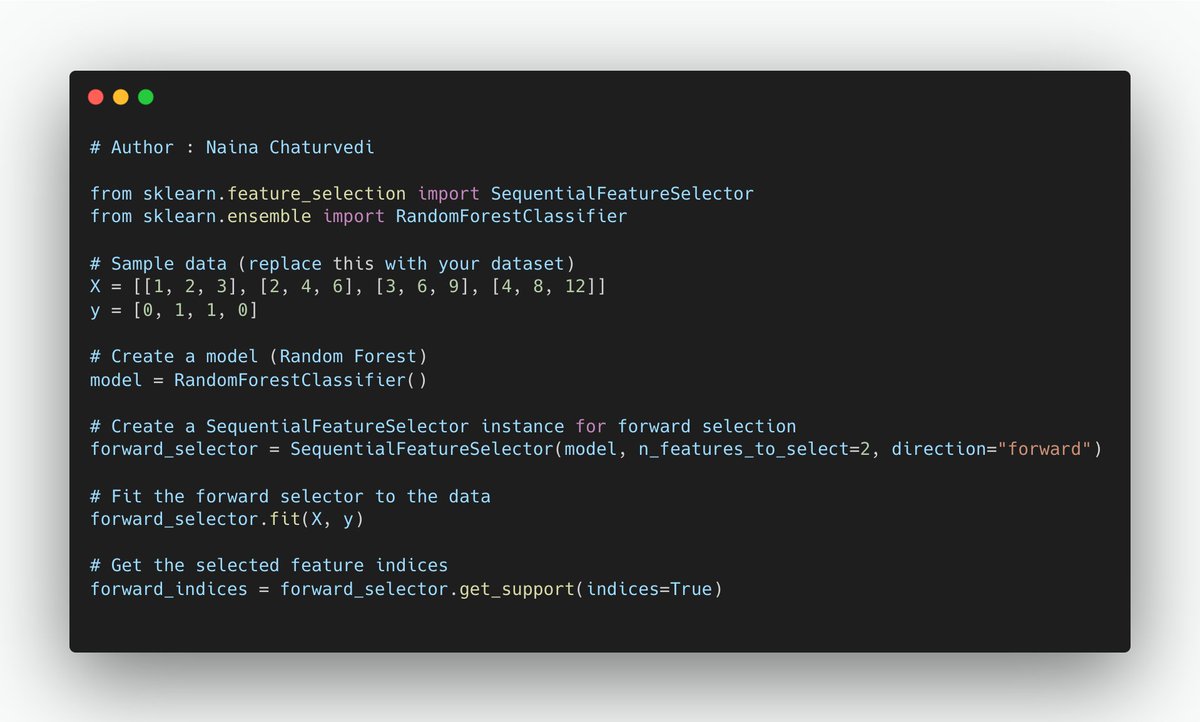
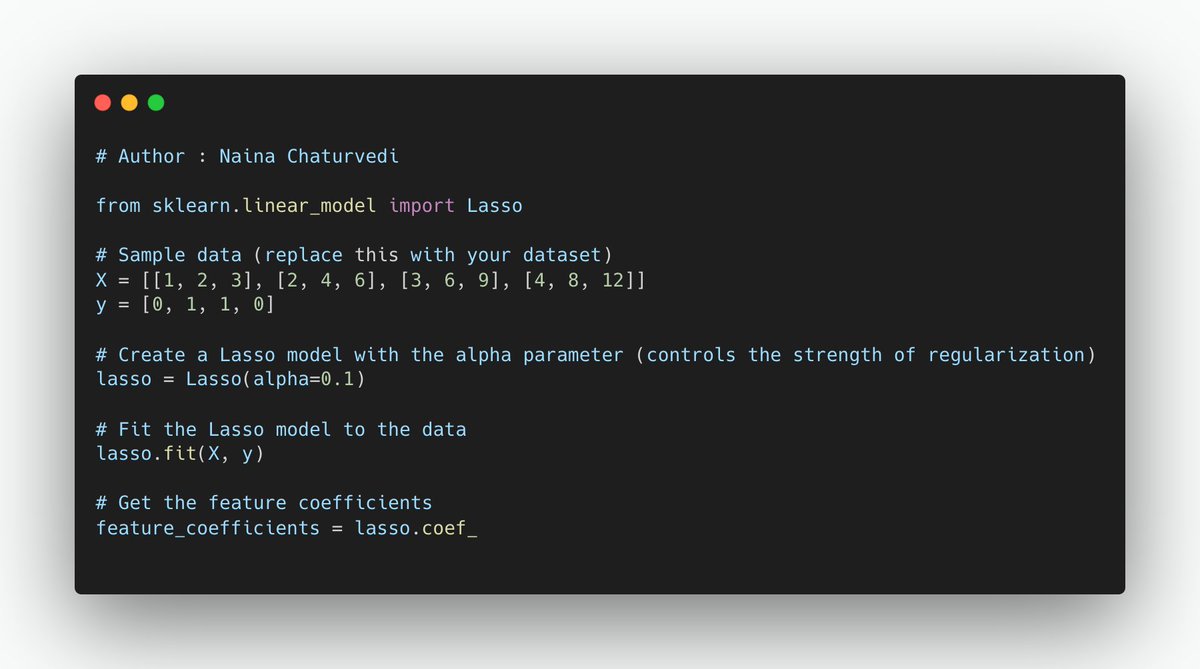
19/ Embedded Methods:
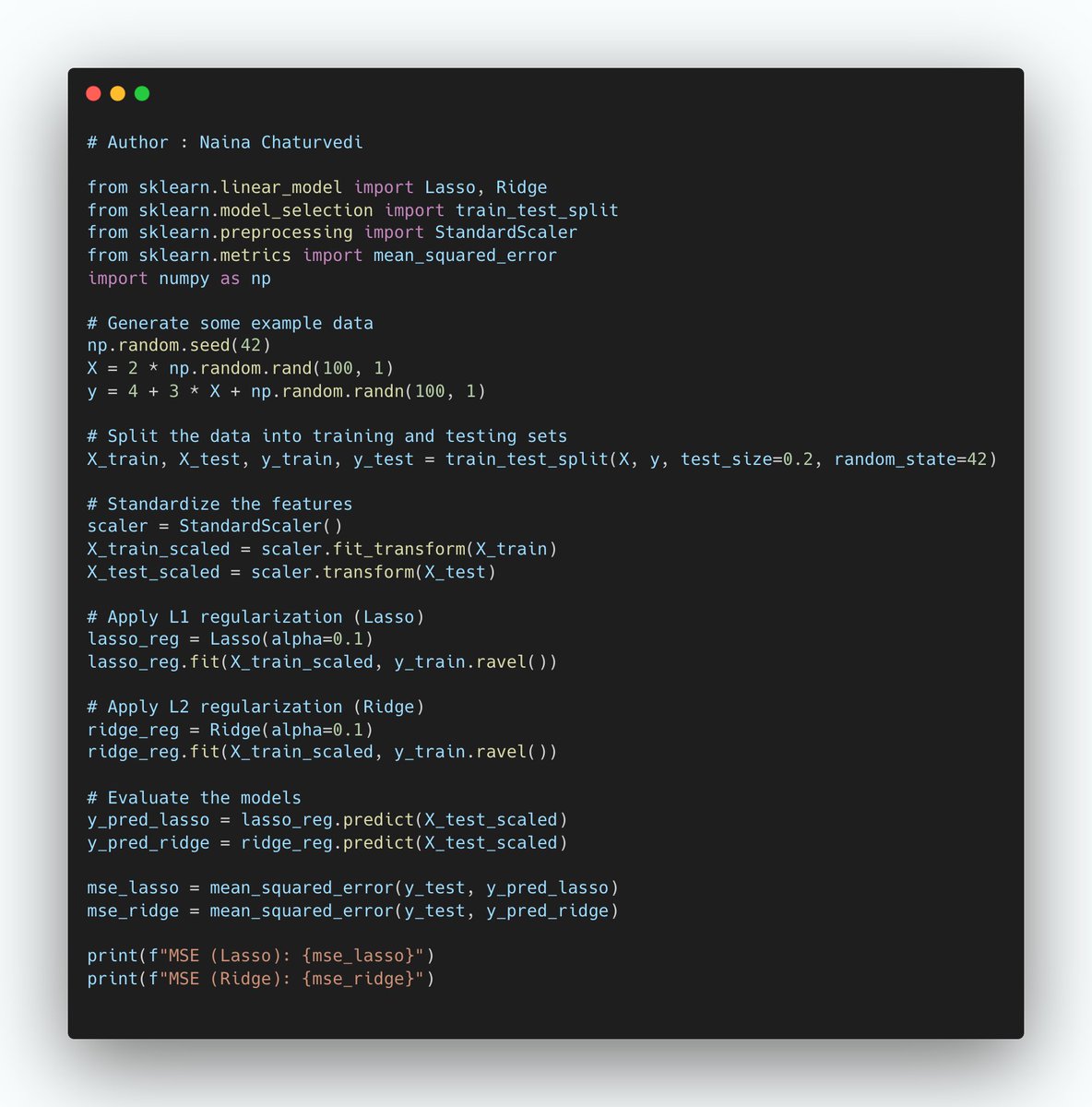
L1 regularization adds a penalty term to the linear regression or logistic regression model's cost function, which encourages the model to minimize the absolute values of the feature coefficients.
L1 regularization adds a penalty term to the linear regression or logistic regression model's cost function, which encourages the model to minimize the absolute values of the feature coefficients.
20/ Tree-based methods like Random Forest can assess feature importance while building the model. Features that contribute the most to reducing impurity (e.g., Gini impurity) or increasing information gain are considered important.
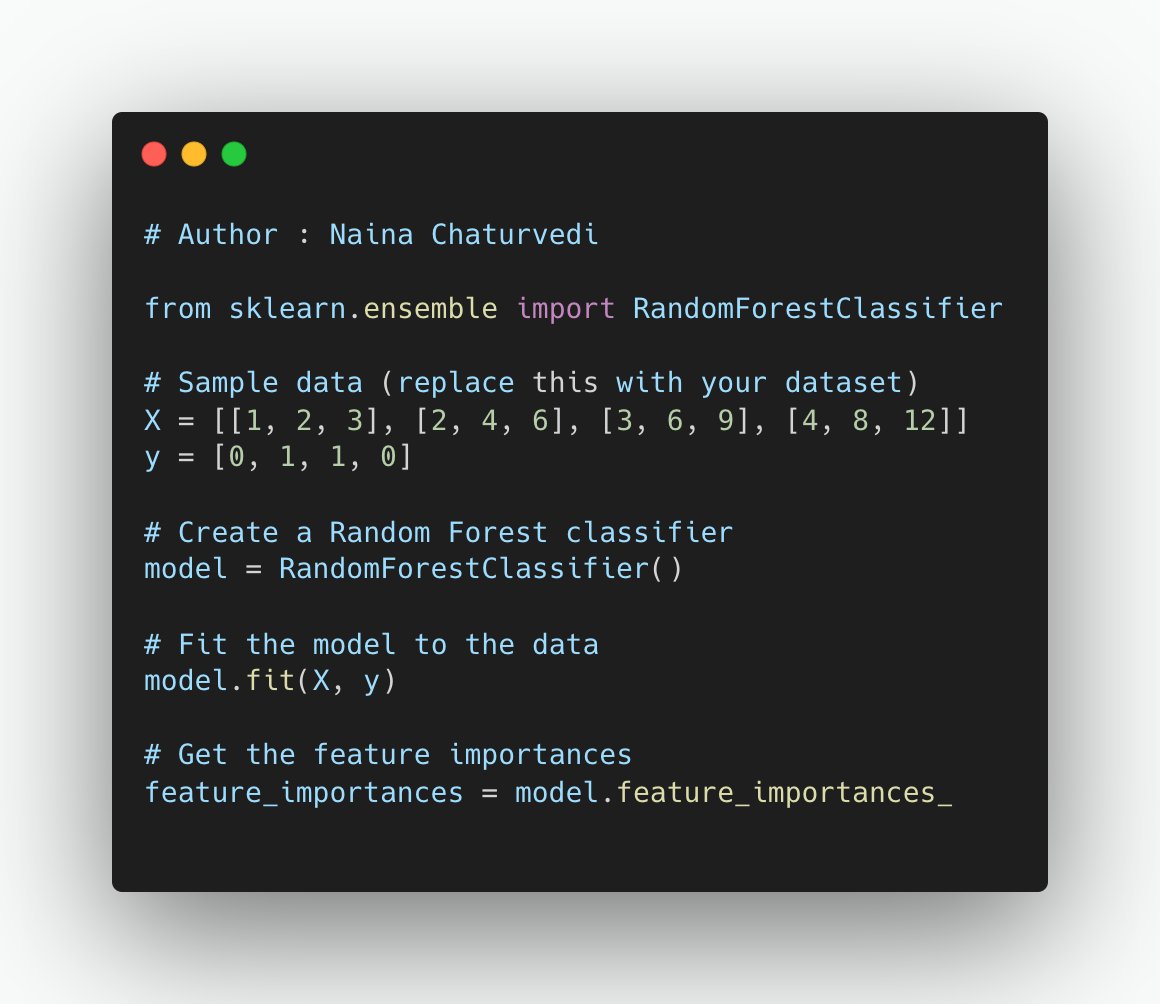
21/ Feature Importance Scores:
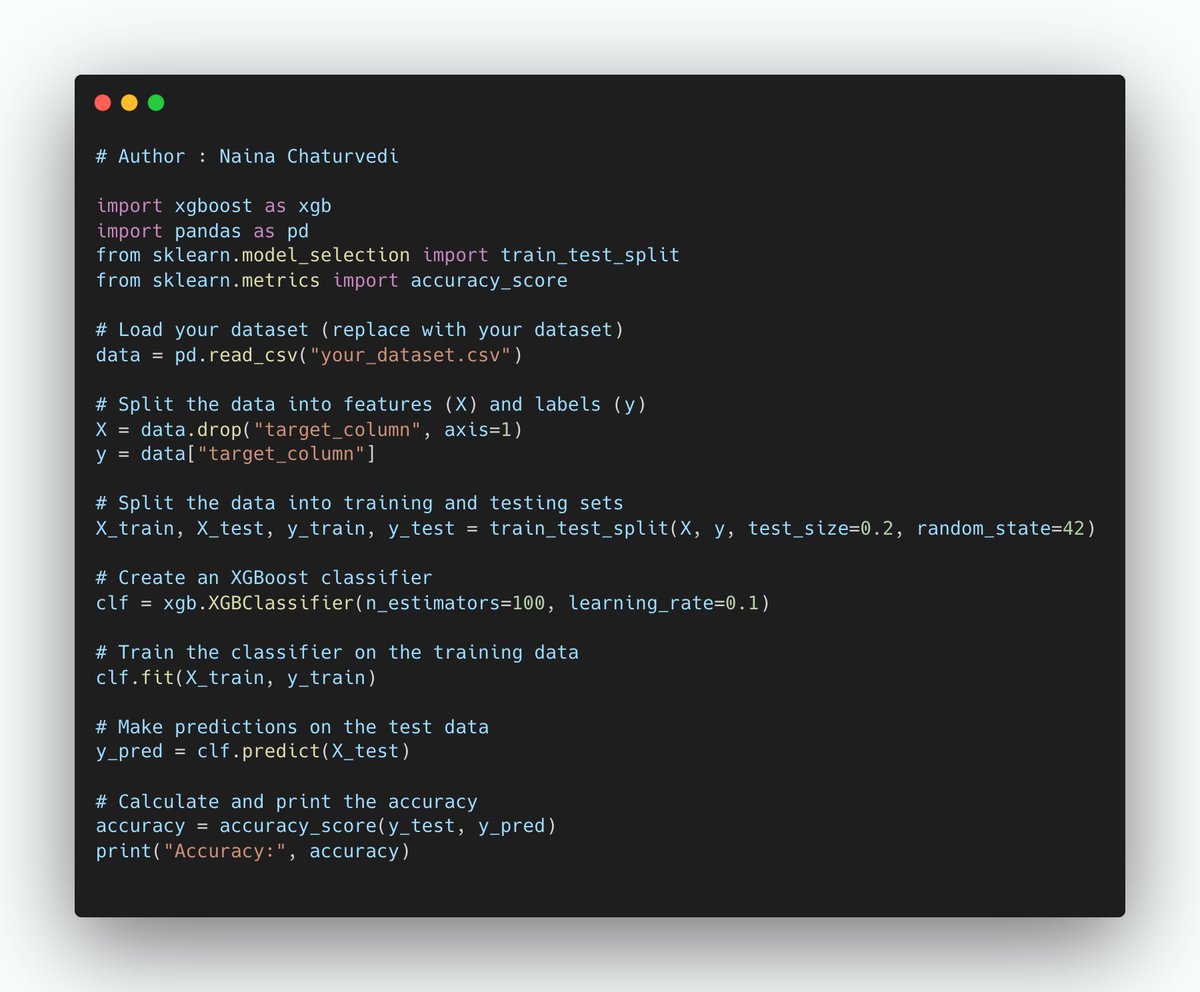
Feature importance scores are a valuable tool for understanding the impact of individual features on a machine learning model's predictions. These scores can be obtained from tree-based models like Random Forest, XGBoost, and LightGBM.
Feature importance scores are a valuable tool for understanding the impact of individual features on a machine learning model's predictions. These scores can be obtained from tree-based models like Random Forest, XGBoost, and LightGBM.

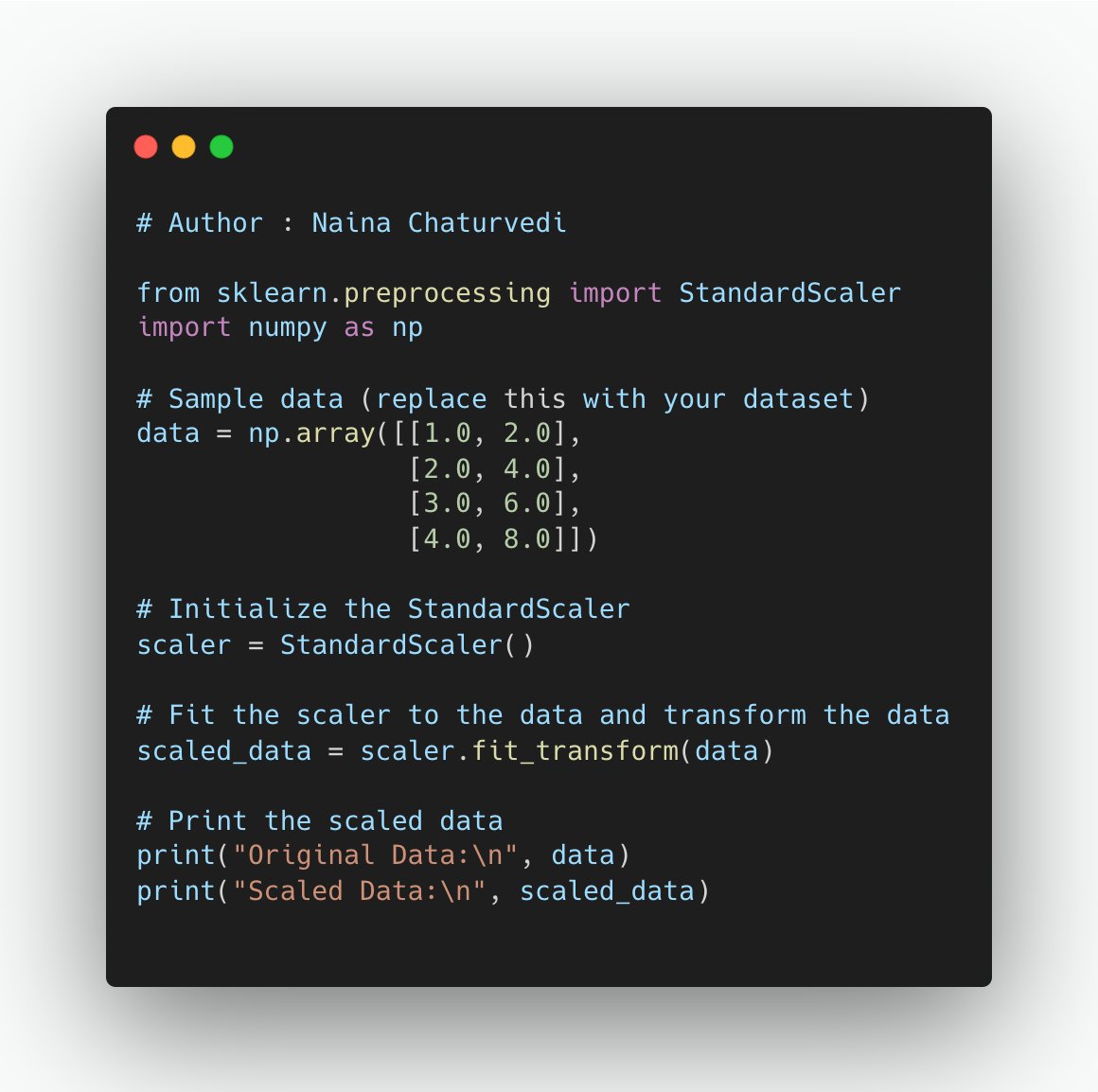
22/ Common Feature Scaling Techniques:
Standardization (Z-score scaling): This method scales features to have a mean of 0 and a standard deviation of 1. It preserves the shape of the original distribution.
Standardization (Z-score scaling): This method scales features to have a mean of 0 and a standard deviation of 1. It preserves the shape of the original distribution.

23/ Min-Max Scaling: This method scales features to a specific range, often [0, 1] or [-1, 1]. It shifts and stretches the feature values to fit within the desired range.
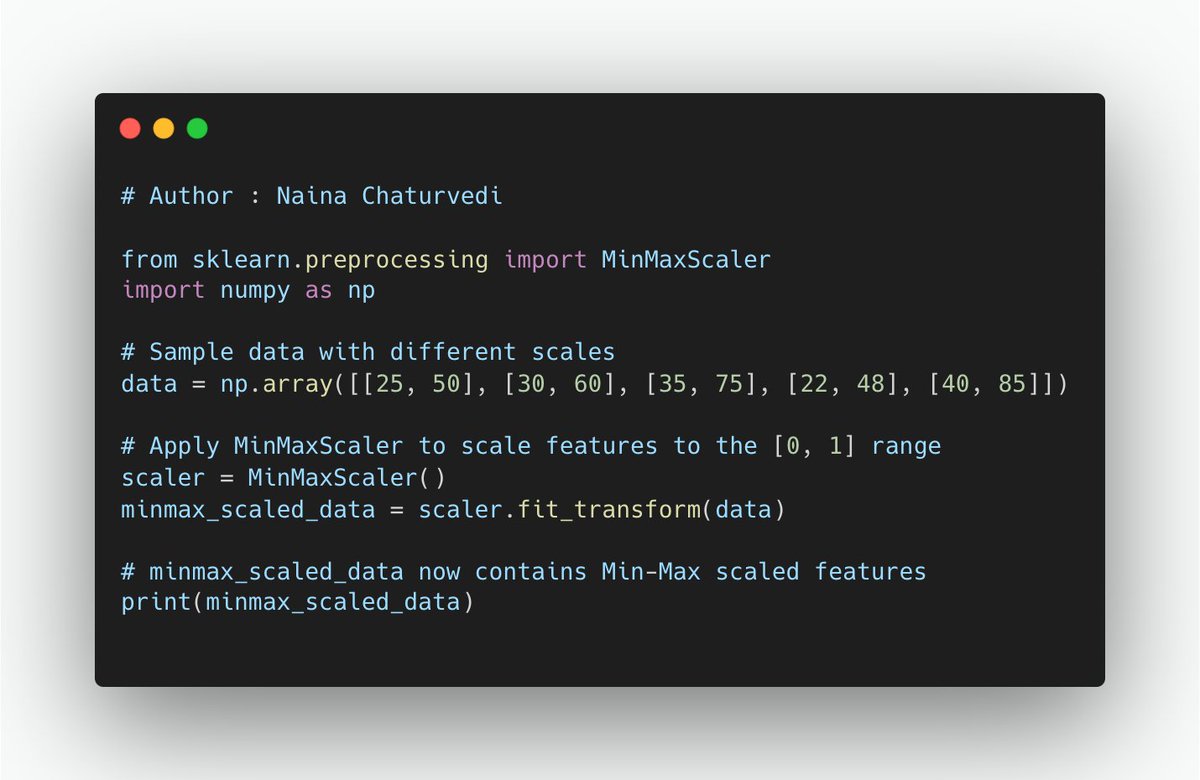
24/ Robust scaling is a technique that scales features based on the median and the interquartile range (IQR). It's more robust to outliers because it uses the median and quartiles rather than the mean and standard deviation.

25/ When to Scale Features:
Distance-Based Algorithms: Algorithms that use distances between data points are sensitive to feature scaling. For example, KNN) calculates distances between data points to make predictions.
Distance-Based Algorithms: Algorithms that use distances between data points are sensitive to feature scaling. For example, KNN) calculates distances between data points to make predictions.

26/ Gradient Descent-Based Algorithms: Machine learning algorithms that use gradient descent for optimization, such as linear regression and support vector machines, are generally more effective when features are scaled. Scaling speeds up convergence.
27/ Algorithms That Typically Benefit from Feature Scaling:
k-Nearest Neighbors (k-NN): This algorithm relies on the Euclidean distance between data points. Feature scaling ensures that all features have a similar impact on the distance calculations.
k-Nearest Neighbors (k-NN): This algorithm relies on the Euclidean distance between data points. Feature scaling ensures that all features have a similar impact on the distance calculations.
28/ Linear Regression: Feature scaling helps in linear regression by improving the convergence of gradient descent, leading to faster and more accurate model training.
29/ Support Vector Machines (SVM): SVM aims to find a hyperplane that maximizes the margin between classes. Feature scaling is crucial for SVM to prevent any single feature from dominating the margin calculation.
30/ Algorithms That Don't Require Feature Scaling:
Decision Trees and Random Forests: Tree-based algorithms make splits in the feature space based on feature values. These algorithms are not sensitive to feature scaling and can handle unscaled data effectively.
Decision Trees and Random Forests: Tree-based algorithms make splits in the feature space based on feature values. These algorithms are not sensitive to feature scaling and can handle unscaled data effectively.
31/ How Scaling Can Be Affected by Outliers:
Outliers are data points that deviate significantly from majority of data in a dataset. When scaling features, outliers can have impact on scaling transformation, especially in techniques like Min-Max Scaling and Standardization.
Outliers are data points that deviate significantly from majority of data in a dataset. When scaling features, outliers can have impact on scaling transformation, especially in techniques like Min-Max Scaling and Standardization.
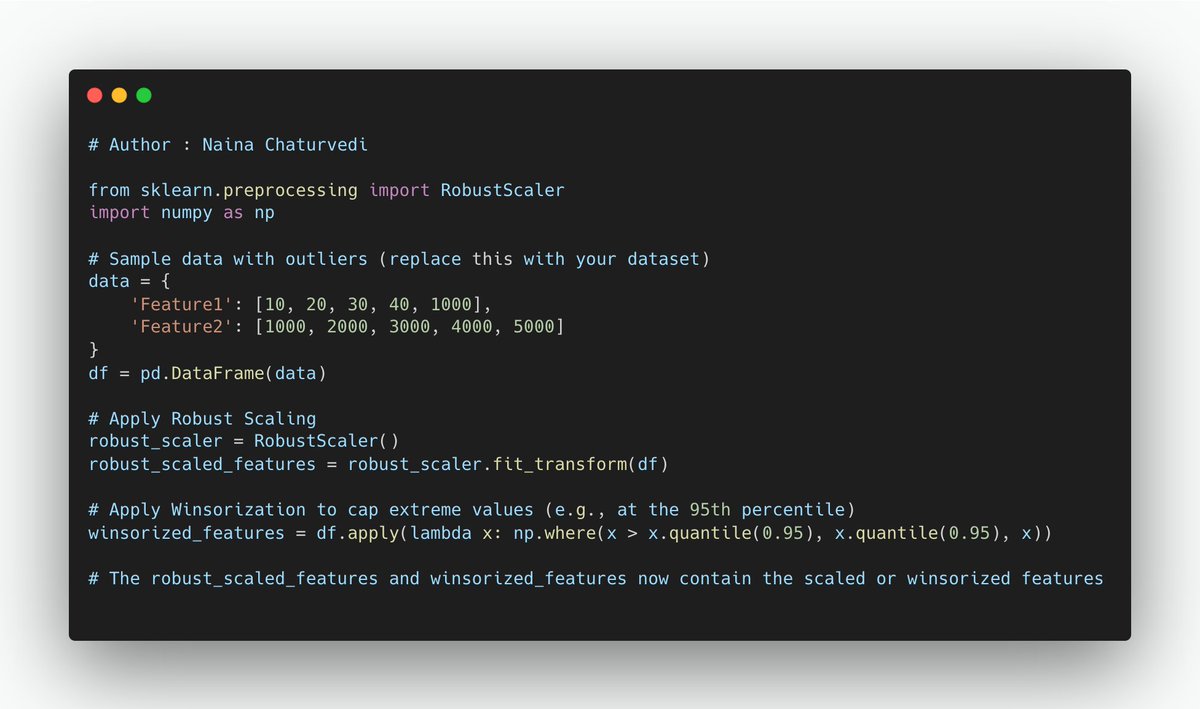
32/ Standardization (Z-score Scaling):
Mean-Centering: Standardization centers the data by subtracting the mean (average) of each feature from the data points. This results in a mean of 0 for each feature.
Mean-Centering: Standardization centers the data by subtracting the mean (average) of each feature from the data points. This results in a mean of 0 for each feature.

33/ Unit Variance: It scales the features to have a standard deviation of 1, which means that the variance of each feature is equal.
Outlier Tolerance: Standardization is less sensitive to outliers because it uses the mean and standard deviation.
Outlier Tolerance: Standardization is less sensitive to outliers because it uses the mean and standard deviation.
34/Use Cases: Standardization is suitable when data follows a normal distribution (or approximately normal) and when the scale and spread of features are important. It is commonly used for linear models, support vector machines, and principal component analysis (PCA).
35/ Min-Max Scaling (Normalization):
Rescaling to a Range: Min-Max Scaling scales features to a specific range, typically [0, 1]. It linearly transforms the data so that the minimum value becomes 0, and the maximum value becomes 1.
Rescaling to a Range: Min-Max Scaling scales features to a specific range, typically [0, 1]. It linearly transforms the data so that the minimum value becomes 0, and the maximum value becomes 1.
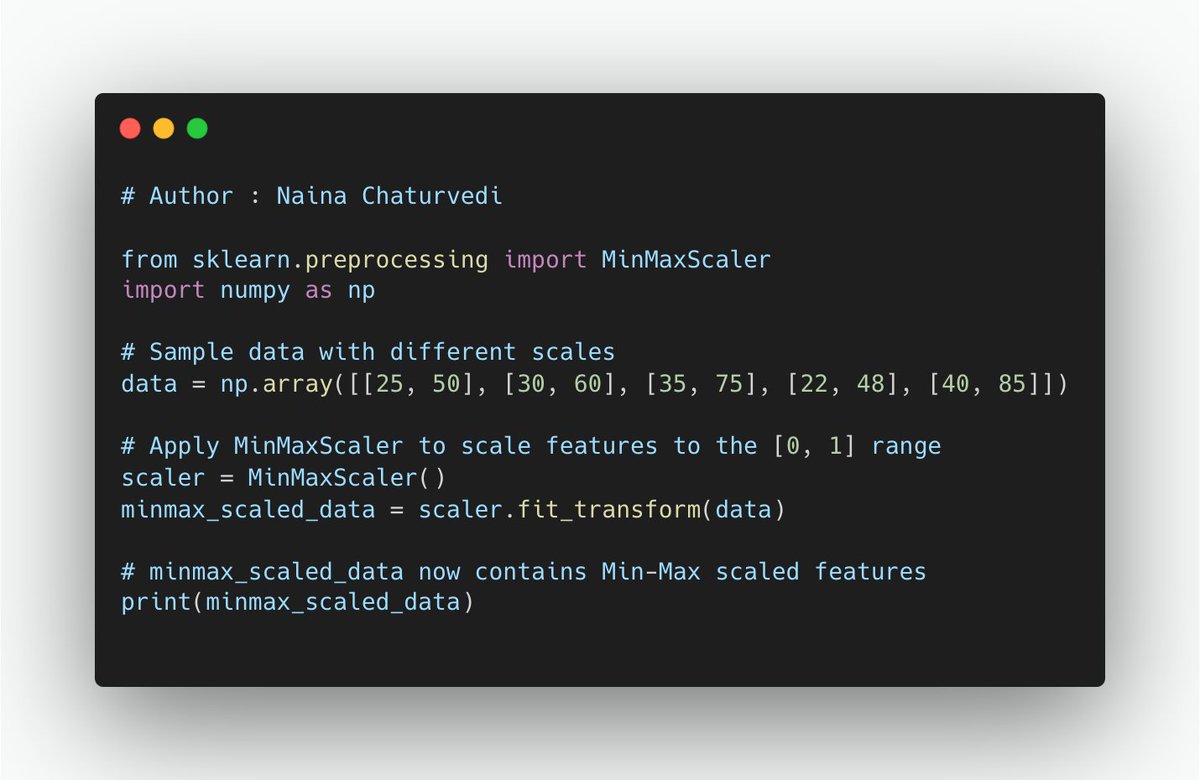
36/ Outlier Sensitivity: Min-Max Scaling can be sensitive to outliers, as it is influenced by the range of data values.
Use Cases: Min-Max Scaling is suitable when data doesn't follow a normal distribution and when absolute values & relationships between features are important.
Use Cases: Min-Max Scaling is suitable when data doesn't follow a normal distribution and when absolute values & relationships between features are important.
37/ Log-Scaling for Skewed Data:
A scaling technique used for data with highly skewed distributions. When data is heavily skewed, with a long tail towards higher values, applying log-scaling can help make the data more symmetrical and reduce the impact of extreme values.
A scaling technique used for data with highly skewed distributions. When data is heavily skewed, with a long tail towards higher values, applying log-scaling can help make the data more symmetrical and reduce the impact of extreme values.

• • •
Missing some Tweet in this thread? You can try to
force a refresh