Large language models (LLMs) and knowledge graphs (KGs) are complementary technologies that balance each other's strengths and weaknesses when combined:
- LLMs have a strong capability for understanding and generating natural language, but can sometimes hallucinate facts.
- KGs explicitly represent factual knowledge in a structured format, but lack language understanding.
- Together, LLMs can provide context and nuance to the rigid facts in KGs, while KGs can ground the free-flowing text from LLMs in reality.
- The intuitive knowledge in LLMs complements the logical knowledge in KGs. KGs can enhance LLMs with external knowledge to improve reasoning and reliability. LLMs can help KGs better utilize textual data.
- By synergizing, LLMs and KGs can achieve enhanced performance on language and knowledge intensive tasks compared to using either technology alone. Their partnership enables fulfilling AI's promise to augment human intelligence through a fusion of data-driven and knowledge-driven approaches.
In summary, the complementary strengths of large neural language models and structured knowledge graphs make them ideal partners for AI systems aiming to combine reasoning, language, and knowledge capabilities. Their synergistic unification can overcome limitations of both approaches.

- LLMs have a strong capability for understanding and generating natural language, but can sometimes hallucinate facts.
- KGs explicitly represent factual knowledge in a structured format, but lack language understanding.
- Together, LLMs can provide context and nuance to the rigid facts in KGs, while KGs can ground the free-flowing text from LLMs in reality.
- The intuitive knowledge in LLMs complements the logical knowledge in KGs. KGs can enhance LLMs with external knowledge to improve reasoning and reliability. LLMs can help KGs better utilize textual data.
- By synergizing, LLMs and KGs can achieve enhanced performance on language and knowledge intensive tasks compared to using either technology alone. Their partnership enables fulfilling AI's promise to augment human intelligence through a fusion of data-driven and knowledge-driven approaches.
In summary, the complementary strengths of large neural language models and structured knowledge graphs make them ideal partners for AI systems aiming to combine reasoning, language, and knowledge capabilities. Their synergistic unification can overcome limitations of both approaches.

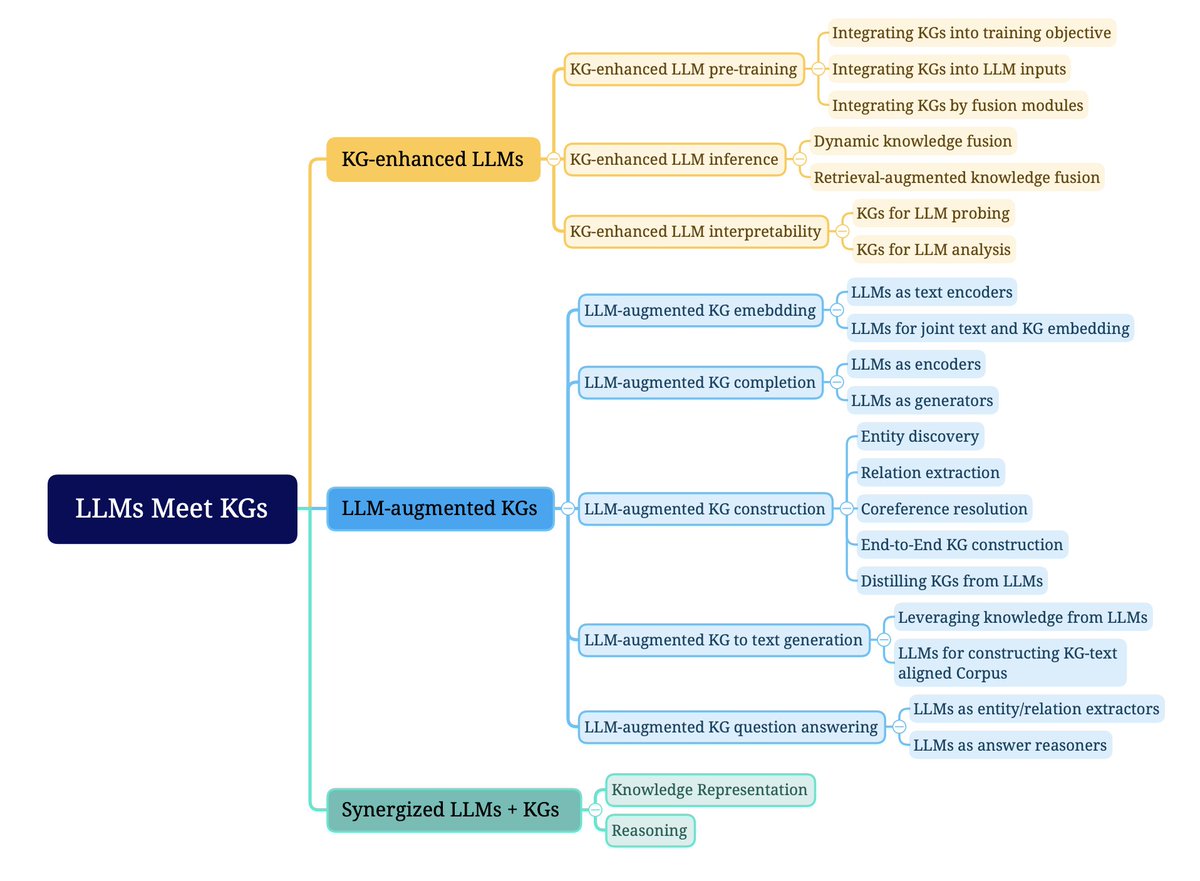
Unifying large language models (LLMs) and knowledge graphs (KGs) fit in three main frameworks:
1) KG-enhanced LLMs:
- Incorporating KGs into LLMs during pre-training or inference stages
- Using KGs to analyze and interpret LLMs
- Aims to improve LLMs' knowledge awareness, performance and interpretability
2) LLM-augmented KGs:
- Applying LLMs to enhance various KG-related tasks like embedding, completion, construction, question answering
- Aims to handle limitations of conventional KG methods in processing text, unseen entities etc.
3) Synergized LLMs + KGs:
- Integrating LLMs and KGs into a unified model/framework
- Mutual enhancement of capabilities e.g. linguistic knowledge of LLMs + factual knowledge of KGs
- Aims for bidirectional reasoning combining strengths of both approaches
1) KG-enhanced LLMs:
- Incorporating KGs into LLMs during pre-training or inference stages
- Using KGs to analyze and interpret LLMs
- Aims to improve LLMs' knowledge awareness, performance and interpretability
2) LLM-augmented KGs:
- Applying LLMs to enhance various KG-related tasks like embedding, completion, construction, question answering
- Aims to handle limitations of conventional KG methods in processing text, unseen entities etc.
3) Synergized LLMs + KGs:
- Integrating LLMs and KGs into a unified model/framework
- Mutual enhancement of capabilities e.g. linguistic knowledge of LLMs + factual knowledge of KGs
- Aims for bidirectional reasoning combining strengths of both approaches
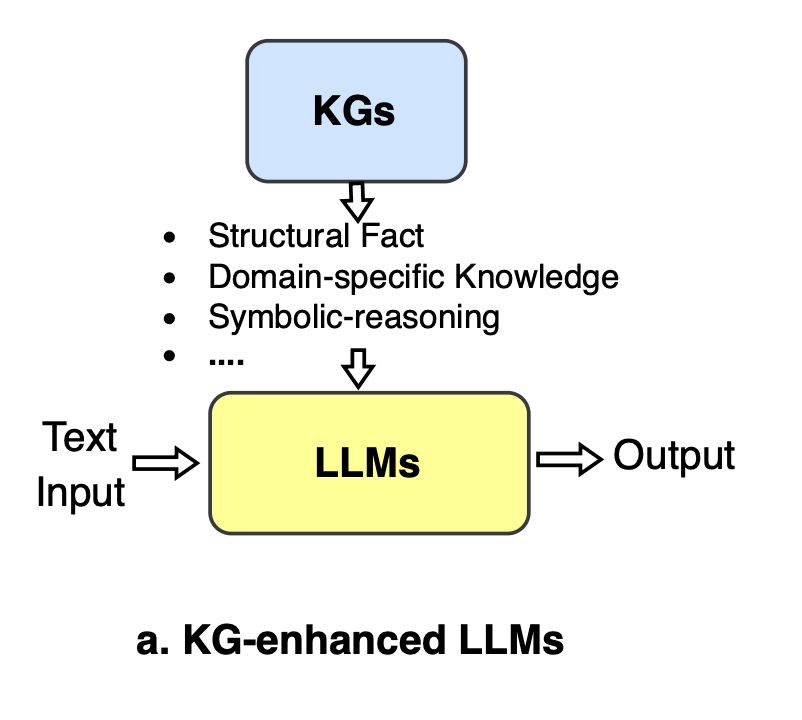
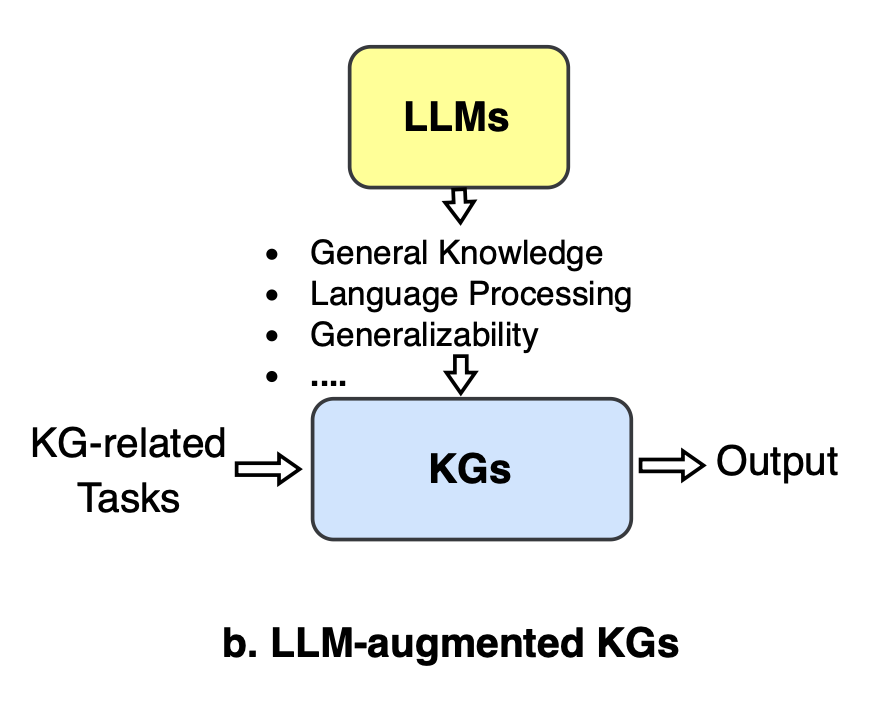
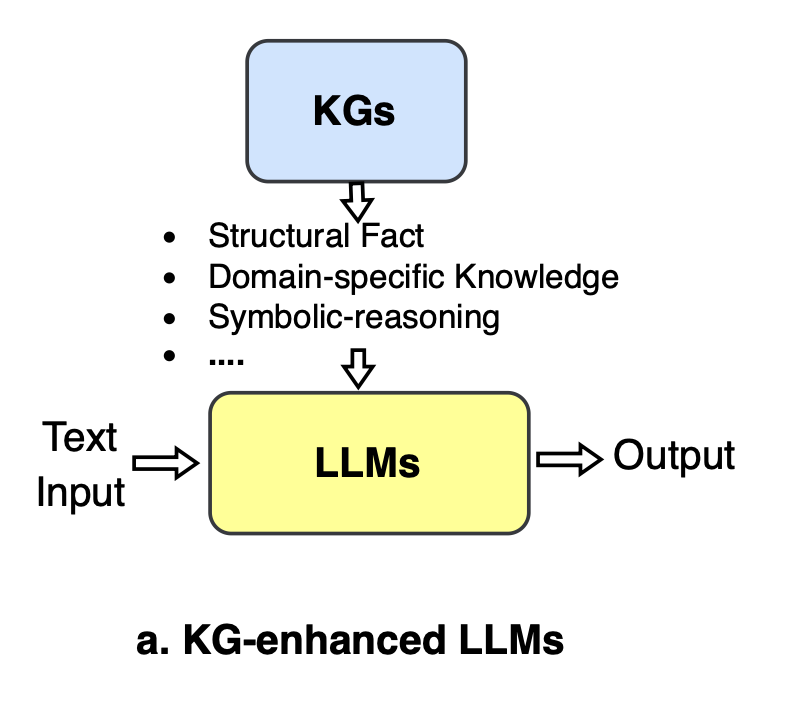
KG-enhanced LLMs
- Goal is to enhance LLMs with knowledge graphs (KGs) to improve their knowledge awareness, performance, and interpretability
- KG-enhanced LLM pre-training: Injecting KG knowledge into LLMs during pre-training stage through:
1) Training objectives that incorporate KG entities and relations
2) Modifying LLM inputs to include KG triples
3) Additional encoders or fusion modules to process KGs separately
- KG-enhanced LLM inference: Keeping KGs separate from LLMs during inference to allow incorporating latest knowledge without retraining. Methods include:
1) Dynamic knowledge fusion using graph networks or attention to fuse KGs with LLM context representations
2) Retrieval-augmented knowledge fusion that retrieves relevant KG facts dynamically during inference
- KG-enhanced LLM interpretability: Using KGs to analyze and explain LLMs by:
1) Probing - converting KG facts to cloze statements to test LLMs' knowledge
2) Analysis - aligning LLM outputs with KG at each step to trace reasoning process and knowledge origins
- Goal is to enhance LLMs with knowledge graphs (KGs) to improve their knowledge awareness, performance, and interpretability
- KG-enhanced LLM pre-training: Injecting KG knowledge into LLMs during pre-training stage through:
1) Training objectives that incorporate KG entities and relations
2) Modifying LLM inputs to include KG triples
3) Additional encoders or fusion modules to process KGs separately
- KG-enhanced LLM inference: Keeping KGs separate from LLMs during inference to allow incorporating latest knowledge without retraining. Methods include:
1) Dynamic knowledge fusion using graph networks or attention to fuse KGs with LLM context representations
2) Retrieval-augmented knowledge fusion that retrieves relevant KG facts dynamically during inference
- KG-enhanced LLM interpretability: Using KGs to analyze and explain LLMs by:
1) Probing - converting KG facts to cloze statements to test LLMs' knowledge
2) Analysis - aligning LLM outputs with KG at each step to trace reasoning process and knowledge origins
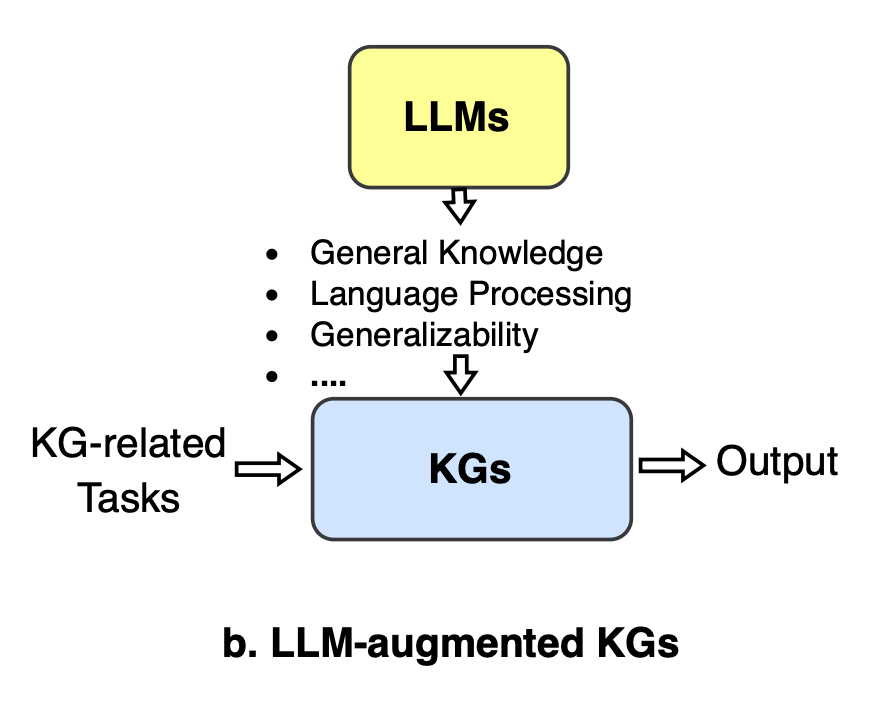
LLMs can augment knowledge graphs (KGs)
- LLMs can help improve various KG-related tasks due to their natural language processing capabilities.
- LLM-augmented KG embedding: Encoding textual descriptions of KG entities and relations using LLMs to enrich their representations. LLMs can be used as additional text encoders or directly for joint text and KG embedding.
- LLM-augmented KG completion: LLMs can encode or generate missing facts, outperforming methods that just use graph structure. LLMs can act as encoders (encoding context) or generators (predicting entities).
- LLM-augmented KG construction: Applying LLMs for tasks like named entity recognition, entity typing, linking and relation extraction to construct KGs from text. Recent works explore end-to-end KG construction and distilling KGs from LLMs.
- LLM-augmented KG-to-text generation: LLMs can generate high-quality text describing KG facts, by encoding graph structure and alignments. Can also construct aligned KG-text corpora.
- LLM-augmented KGQA: LLMs are used to match questions to KG structure (as entity/relation extractors) or reason over retrieved facts (as answer generators).
- LLMs can help improve various KG-related tasks due to their natural language processing capabilities.
- LLM-augmented KG embedding: Encoding textual descriptions of KG entities and relations using LLMs to enrich their representations. LLMs can be used as additional text encoders or directly for joint text and KG embedding.
- LLM-augmented KG completion: LLMs can encode or generate missing facts, outperforming methods that just use graph structure. LLMs can act as encoders (encoding context) or generators (predicting entities).
- LLM-augmented KG construction: Applying LLMs for tasks like named entity recognition, entity typing, linking and relation extraction to construct KGs from text. Recent works explore end-to-end KG construction and distilling KGs from LLMs.
- LLM-augmented KG-to-text generation: LLMs can generate high-quality text describing KG facts, by encoding graph structure and alignments. Can also construct aligned KG-text corpora.
- LLM-augmented KGQA: LLMs are used to match questions to KG structure (as entity/relation extractors) or reason over retrieved facts (as answer generators).
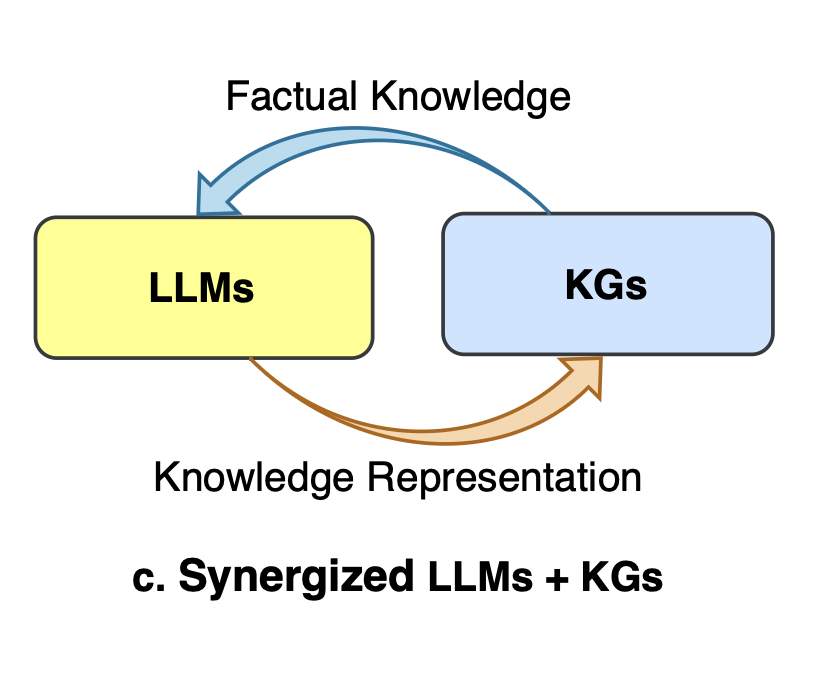
Synergizing LLMs and KGs
- For knowledge representation:
- Jointly pre-train LLMs and KGs to align their representations
- Methods like KEPLER and JointGT propose joint objectives to embed text and KGs in a shared space
- For reasoning:
- Apply LLMs and KGs together to combine their reasoning strengths
- In QA, methods use LLMs to process text and retrieve relevant KG facts, then reason over facts using KG structure
- In logical reasoning, LLMs can generate logic queries executed on KGs, with results fused back into LLMs
- Unified LLMs + KGs can enhance diverse applications like search, recommendations, and AI assistants
- For knowledge representation:
- Jointly pre-train LLMs and KGs to align their representations
- Methods like KEPLER and JointGT propose joint objectives to embed text and KGs in a shared space
- For reasoning:
- Apply LLMs and KGs together to combine their reasoning strengths
- In QA, methods use LLMs to process text and retrieve relevant KG facts, then reason over facts using KG structure
- In logical reasoning, LLMs can generate logic queries executed on KGs, with results fused back into LLMs
- Unified LLMs + KGs can enhance diverse applications like search, recommendations, and AI assistants

Here's is the source paper: arxiv.org/abs/2306.08302
Overview
• • •
Missing some Tweet in this thread? You can try to
force a refresh