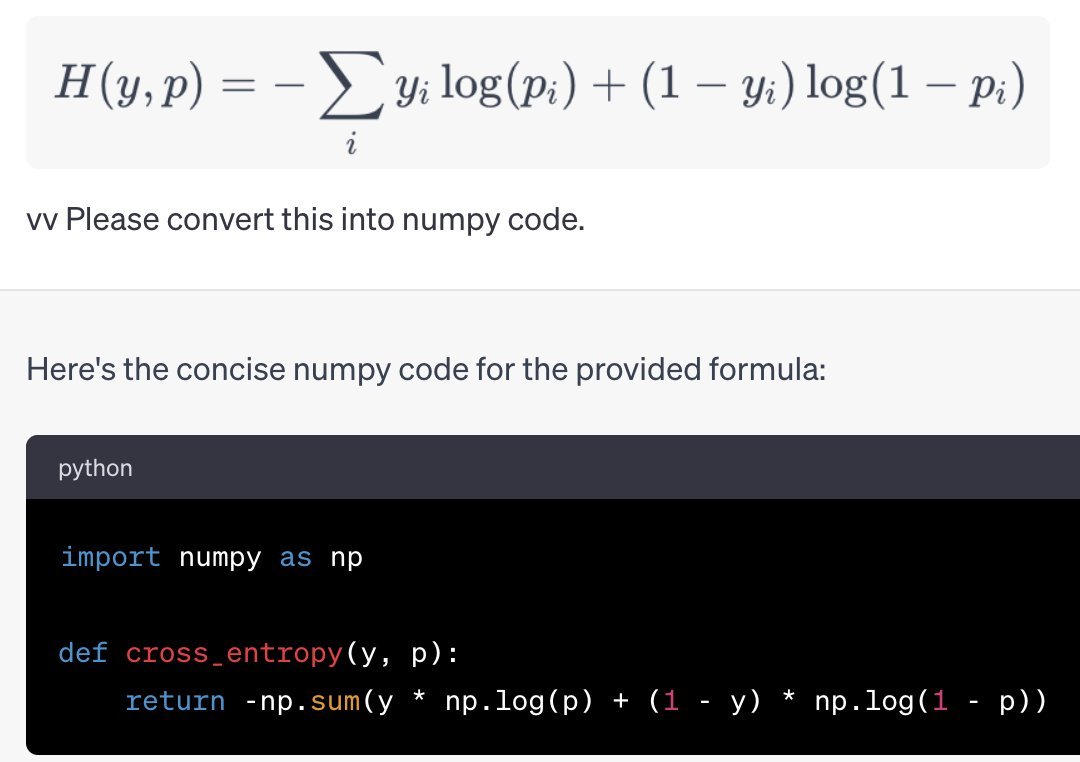
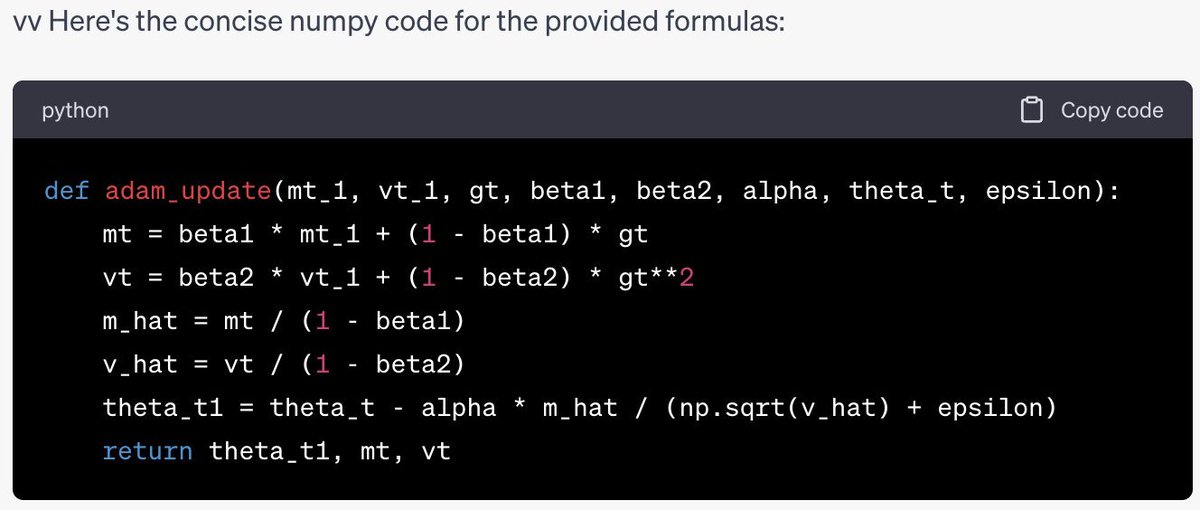
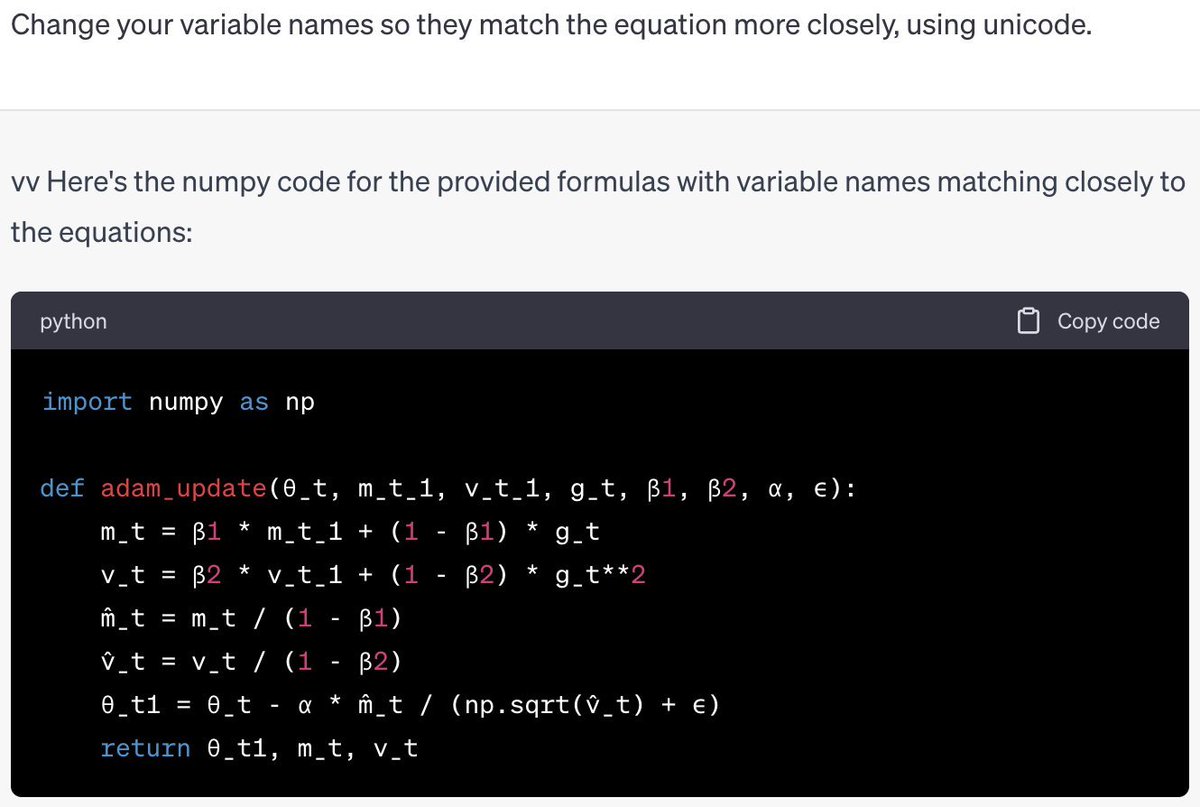
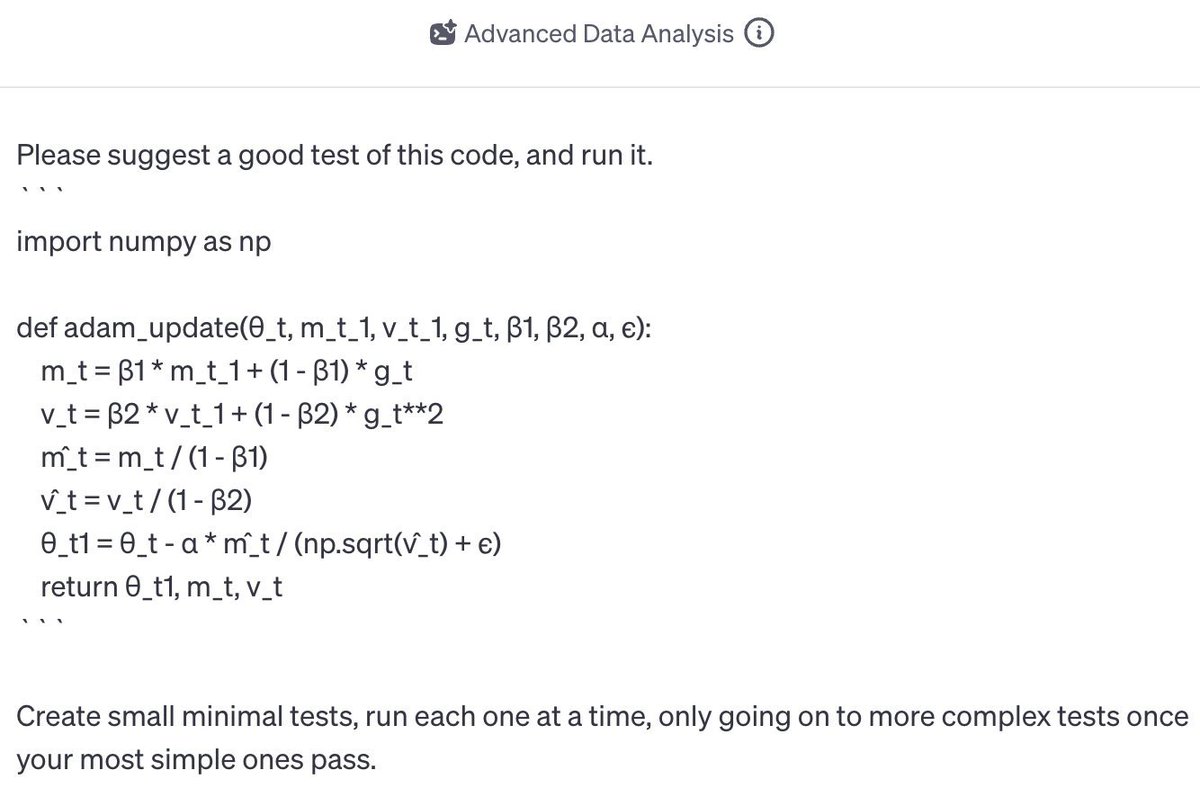
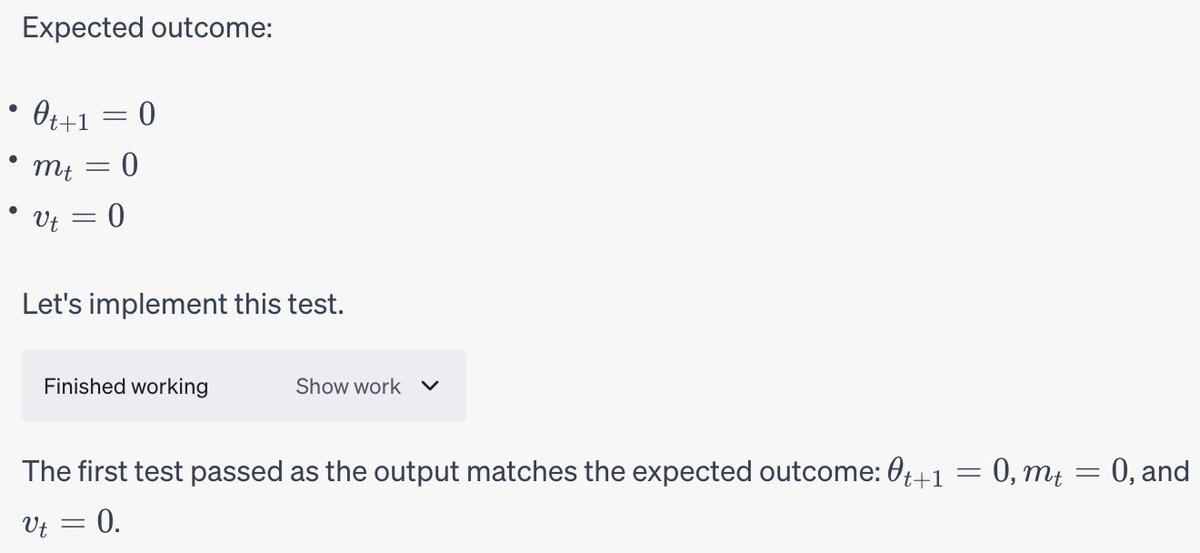
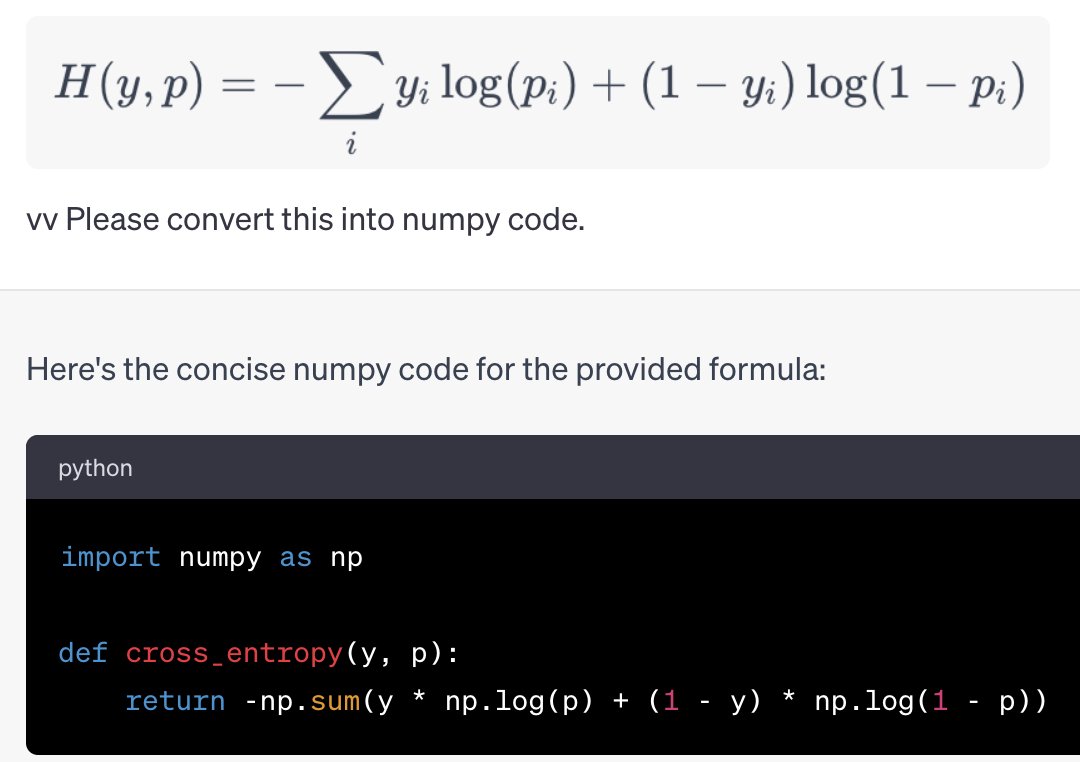
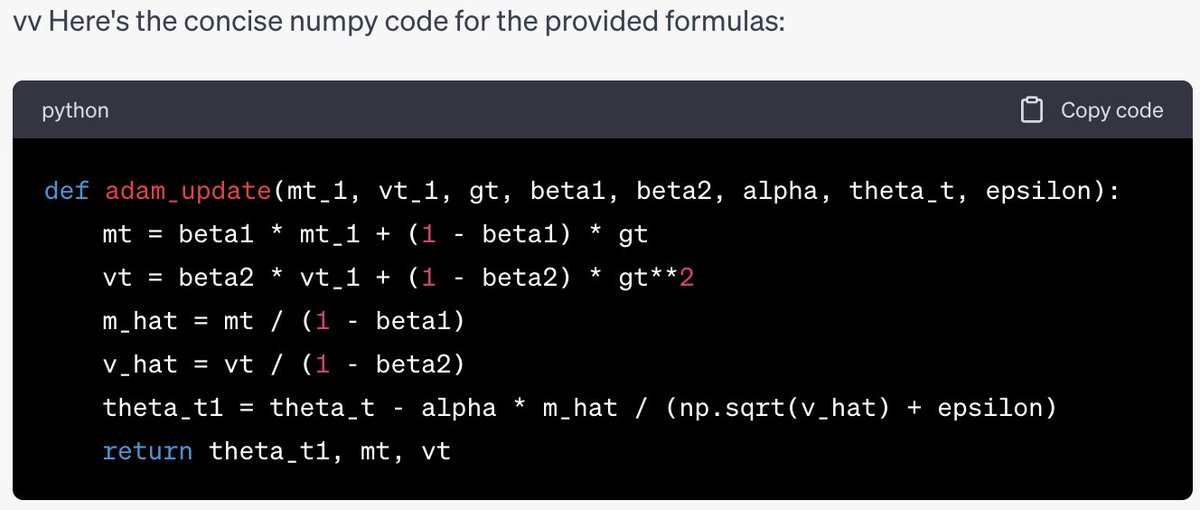
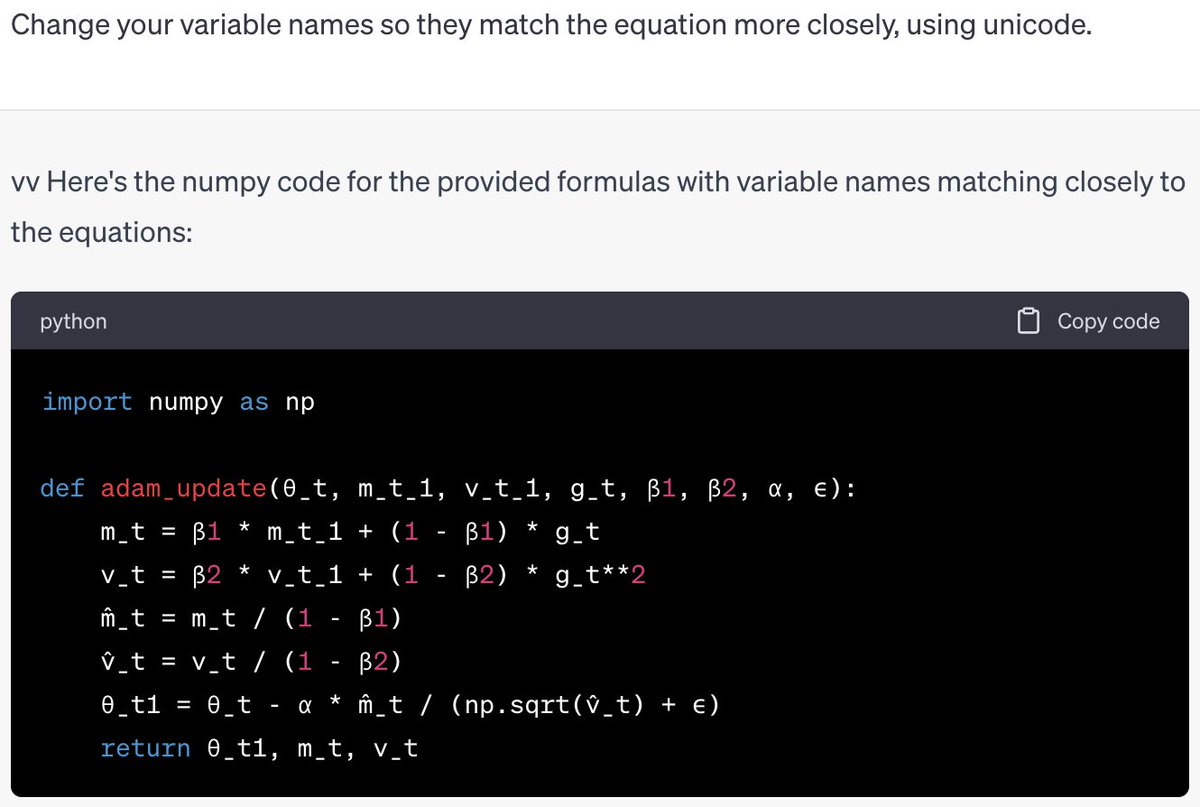
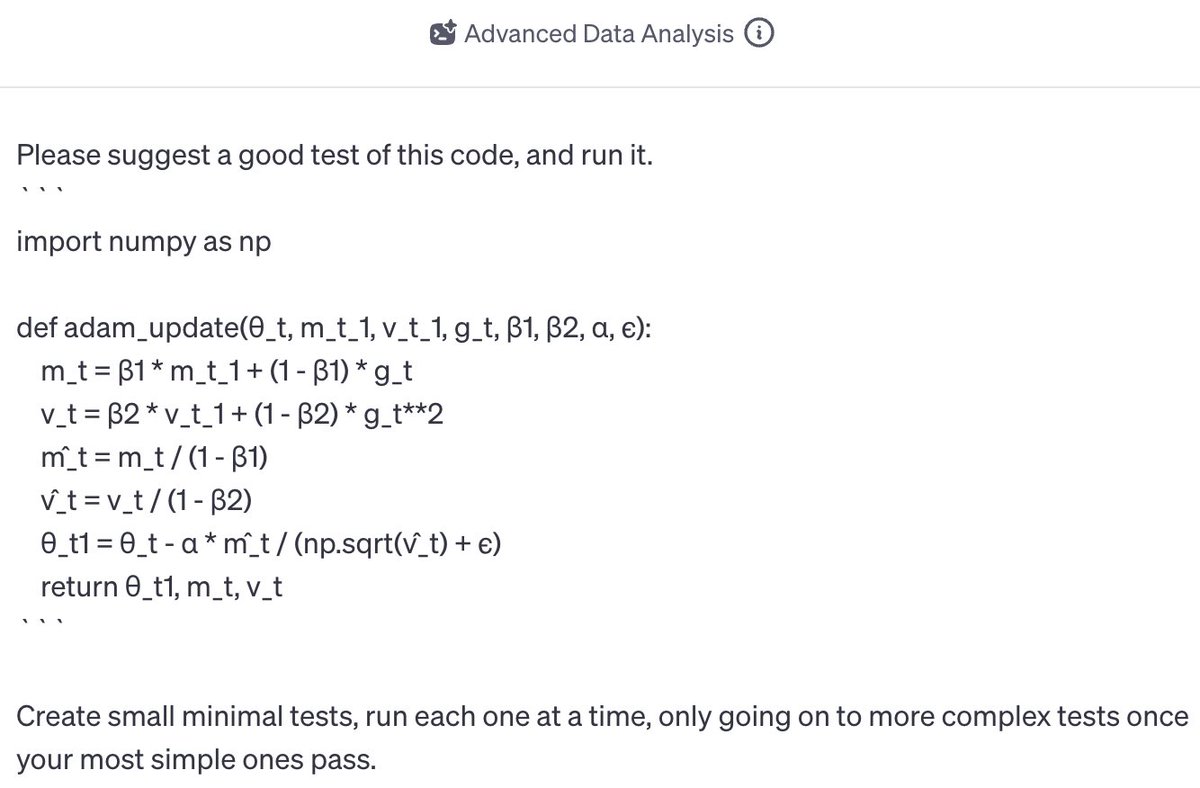
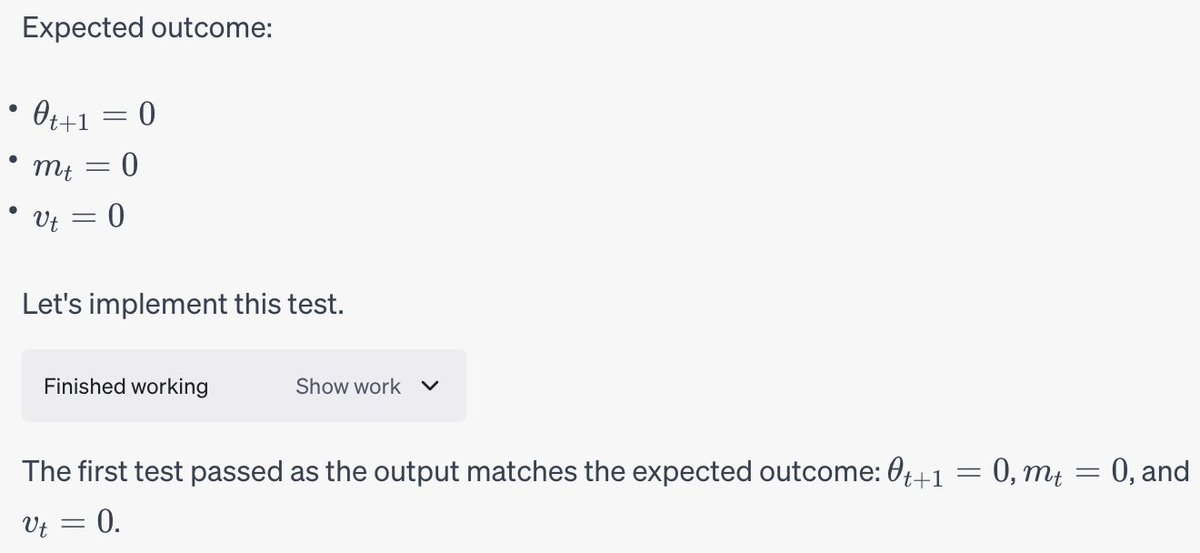
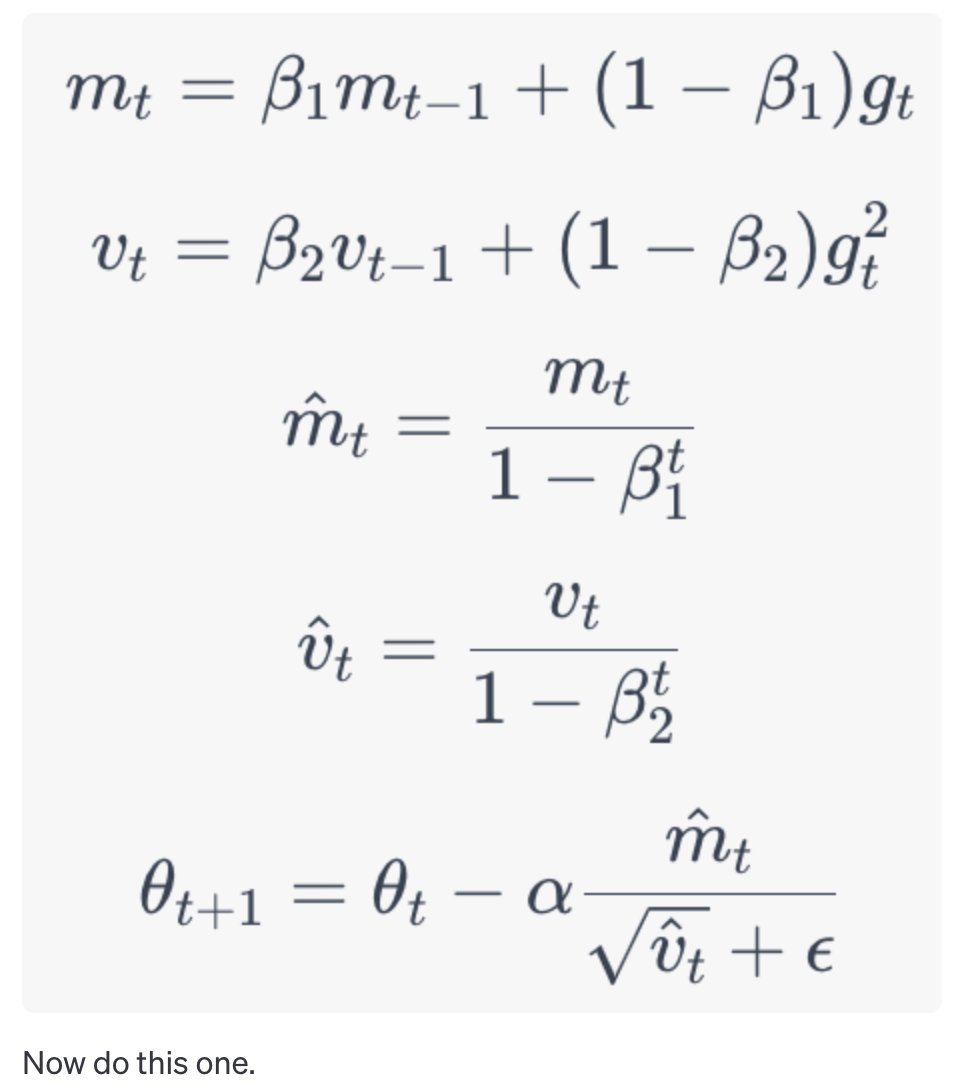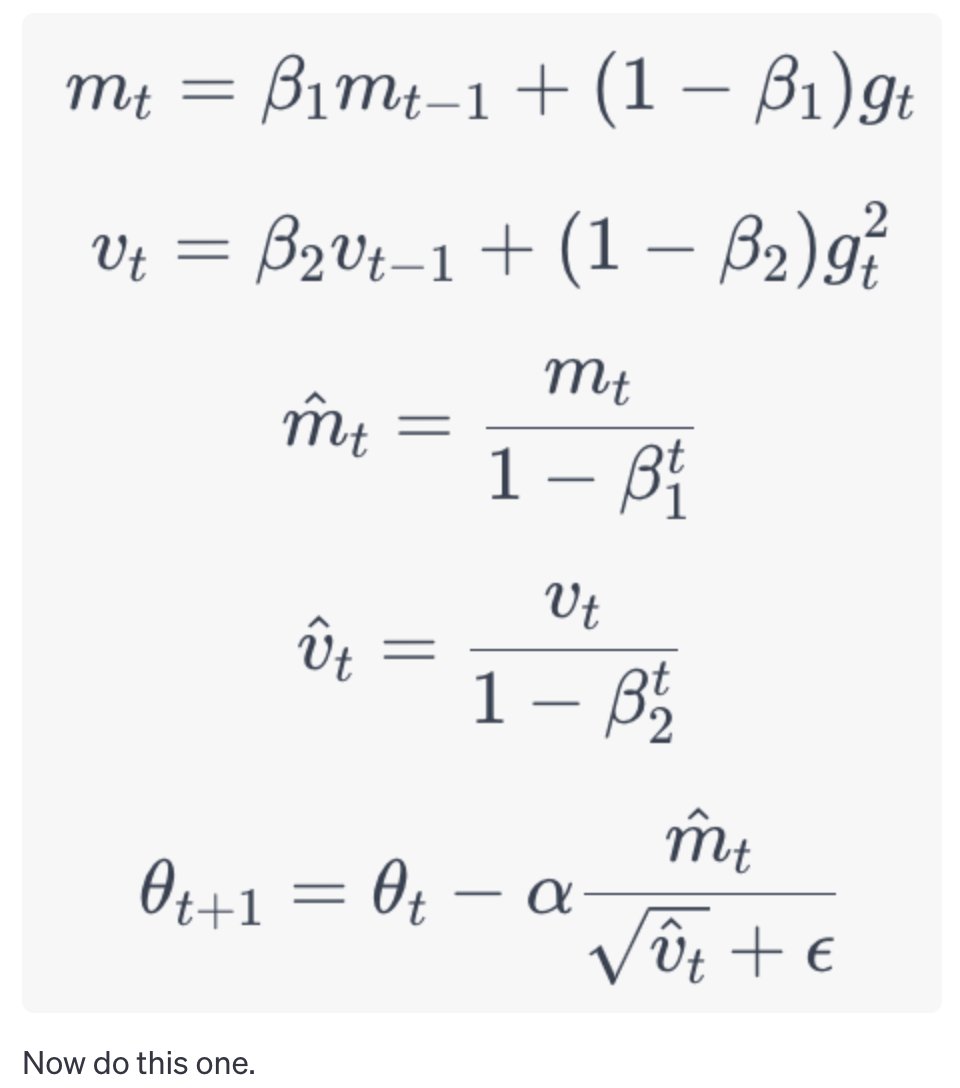OK everyone's asking me for my take on the OpenAI stuff, so here it is. I have a strong feeling about what's going on, but no internal info so this is just me talking.
The first point to make is that the Dev Day was (IMO) an absolute embarrassment.
The first point to make is that the Dev Day was (IMO) an absolute embarrassment.
I could barely watch the keynote. It was just another bland corp-speak bunch of product updates.
For those researchers I know that were involved from the beginning, this must have felt nausea-inducing.
The plan was AGI, lifting society to a new level. We got Laundry Buddy.
For those researchers I know that were involved from the beginning, this must have felt nausea-inducing.
The plan was AGI, lifting society to a new level. We got Laundry Buddy.

When OAI was founded I felt like it was gonna but a rough ride. It was created by a bunch of brilliant researchers that I knew and respected, plus some huge names from outside the field: Elon, GDB, and sama, none of who I'd ever come across at any AI/ML conference or meetup.
Everything I'd heard about those 3 was that they were brilliant operators and that they did amazing work. But it felt likely to be a huge culture shock on all sides.
But the company absolutely blossomed nonetheless.
But the company absolutely blossomed nonetheless.
With the release of Codex, however, we had the first culture clash that was beyond saving: those who really believed in the safety mission were horrified that OAI was releasing a powerful LLM that they weren't 100% sure was safe. The company split, and Anthropic was born.
Now OAI accelerated in its new direction. It wasn't open any more, and it decided to pursue profits to fund its non-profit goals.
Nonetheless, the company remained controlled by the non-profit, and therefore by its board.
Nonetheless, the company remained controlled by the non-profit, and therefore by its board.

Suddenly sama, the CEO, was everywhere. Giving keynotes, talking to world leaders, and raising billions of dollars. He's widely regarded as one of the most ambitious and effective operators in the world.
I wondered how his ambition could gel with the legally binding mission.
I wondered how his ambition could gel with the legally binding mission.

My guess is that watching the keynote would have made the mismatch between OpenAI's mission and the reality of its current focus impossible to ignore. I'm sure I wasn't the only one that cringed during it.
I think the mismatch between mission and reality was impossible to fix.
I think the mismatch between mission and reality was impossible to fix.
Overall, I expect that the OAI board's move will turn out to be a critical enabler of OAI's ability to delivery on its mission.
In the future, aspirational people looking for power and profits will *not* be drawn to the company, and instead it'll hire and retain true believers.
In the future, aspirational people looking for power and profits will *not* be drawn to the company, and instead it'll hire and retain true believers.
I'm gonna take back my "ngmi" from the day before the sama move.
I feel much more positive about the company now.
I feel much more positive about the company now.
https://twitter.com/HamelHusain/status/1725655686913392933
Alright forget what I said about Laundry Buddy.
https://twitter.com/jeremyphoward/status/1725791074088784136
• • •
Missing some Tweet in this thread? You can try to
force a refresh