
🇦🇺 Co-founder: @AnswerDotAI/@FastDotAI ;
Prev: Professor@UQ; Stanford fellow; @kaggle founding president; founder @fastmail/@enlitic/…
https://t.co/16UBFTWzwQ
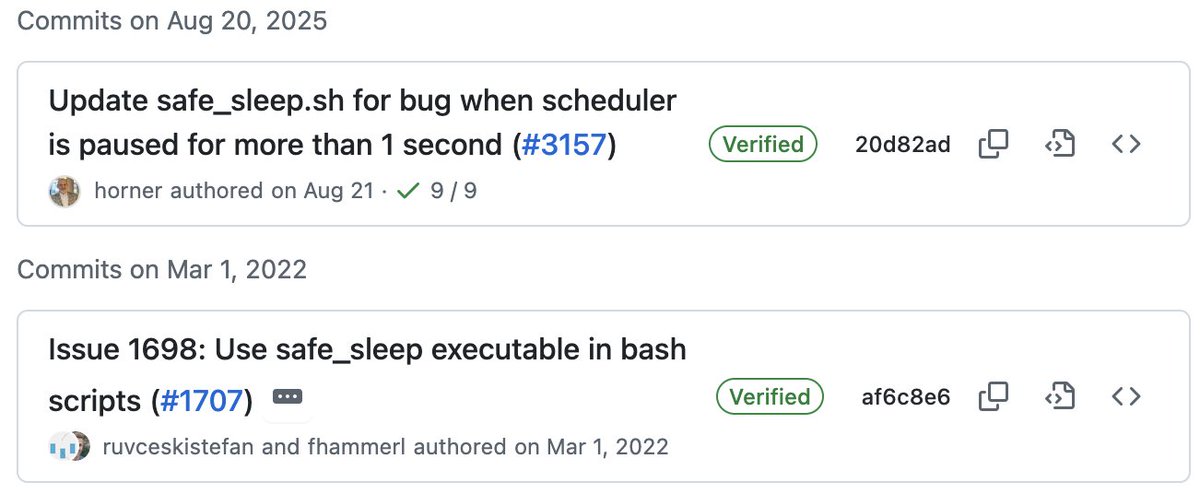 `safe_sleep` was added in 2022.
`safe_sleep` was added in 2022.

 Here is the full original: daodejing.org .
Here is the full original: daodejing.org .

 If you are using a Chinese cloud based service hosted in China, then your data will be sent to a server in China.
If you are using a Chinese cloud based service hosted in China, then your data will be sent to a server in China. ModernBERT is available as a slot-in replacement for any BERT-like model, with both 139M param and 395M param sizes.
ModernBERT is available as a slot-in replacement for any BERT-like model, with both 139M param and 395M param sizes.
 Here's the official API docs with details on pricing:
Here's the official API docs with details on pricing: To get started, head over to the home page: .
To get started, head over to the home page: .


 To replicate:
To replicate: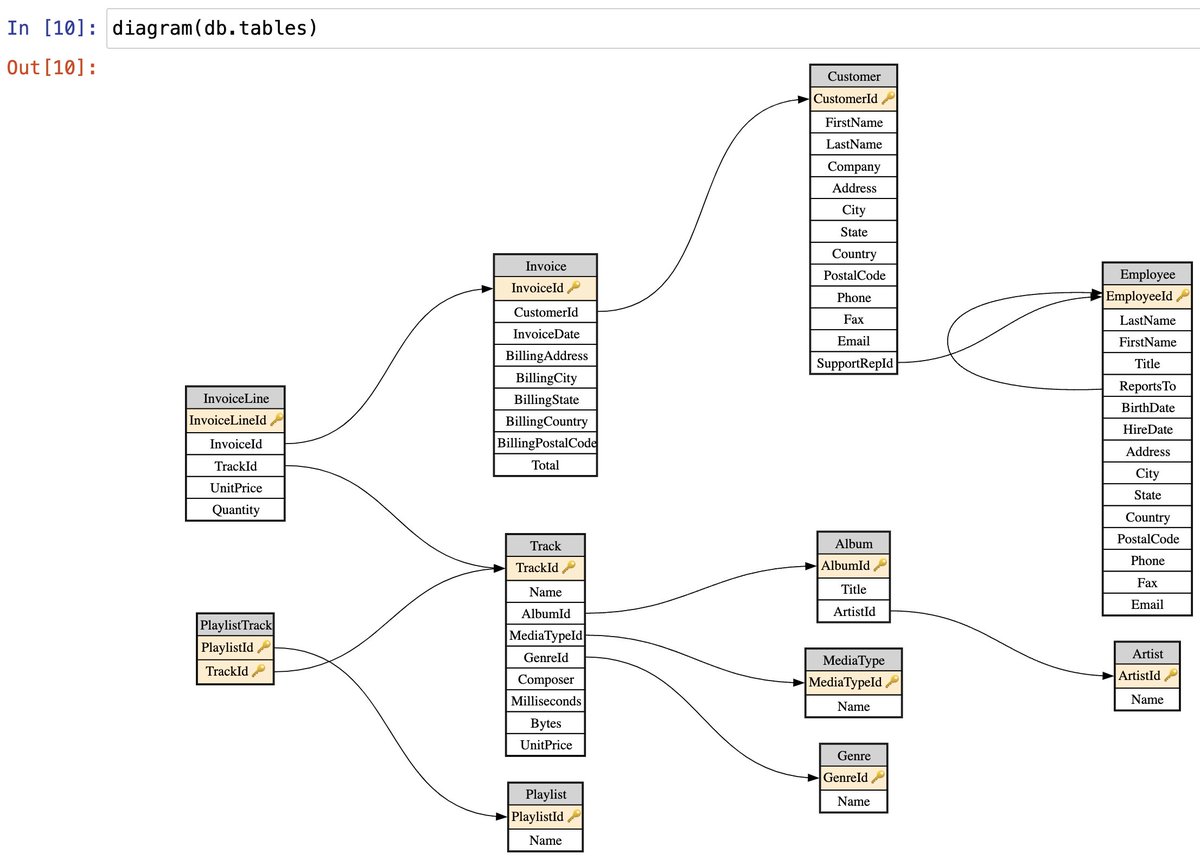 To install it, just do `pip install fastlite`. It'll install sqlite-utils automatically. (And sqlite itself is already installed with Python.)
To install it, just do `pip install fastlite`. It'll install sqlite-utils automatically. (And sqlite itself is already installed with Python.)