Announcing StripedHyena 7B — an open source model using an architecture that goes beyond Transformers achieving faster performance and longer context.
It builds on the lessons learned in past year designing efficient sequence modeling architectures.
together.ai/blog/stripedhy…

It builds on the lessons learned in past year designing efficient sequence modeling architectures.
together.ai/blog/stripedhy…

This release includes StripedHyena-Hessian-7B (SH 7B), a base model, & StripedHyena-Nous-7B (SH-N 7B), a chat model. Both use a hybrid architecture based on our latest on scaling laws of efficient architectures.
Both models are available on Together API!
api.together.xyz/playground/cha…
Both models are available on Together API!
api.together.xyz/playground/cha…
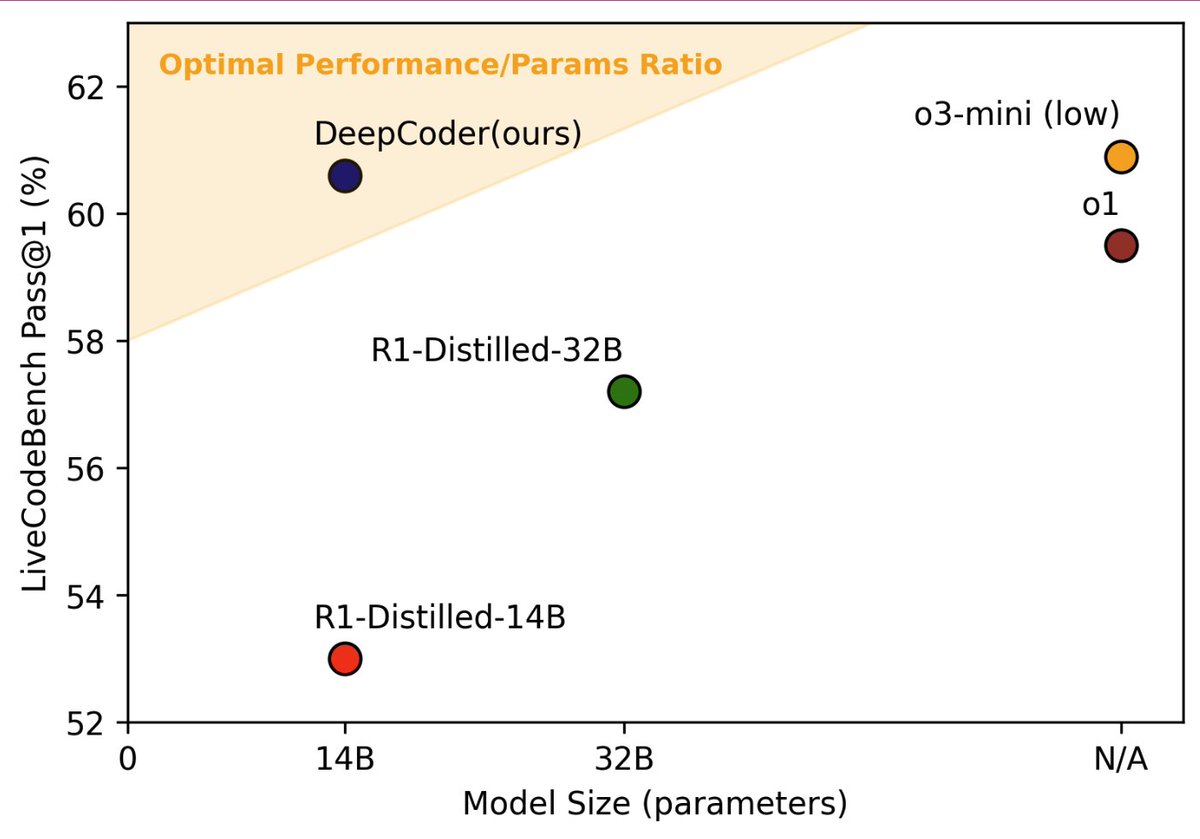
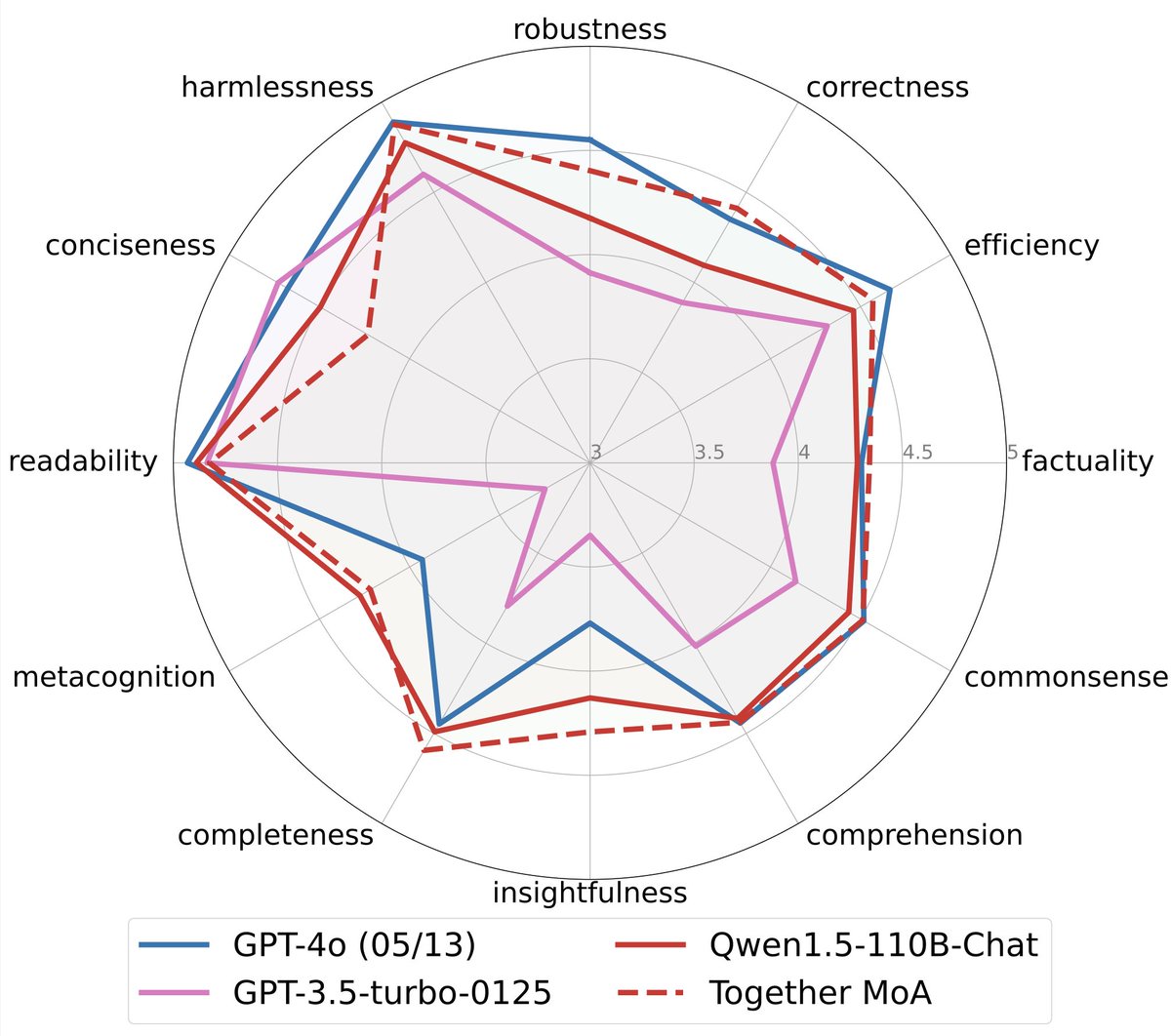
StripedHyena is the first alternative model competitive with the best open-source Transformers in short and long-context evaluations. Achieves comparable performance with Llama-2, Yi & Mistral 7B on OpenLLM leaderboard, outperforming on long-context summarization.
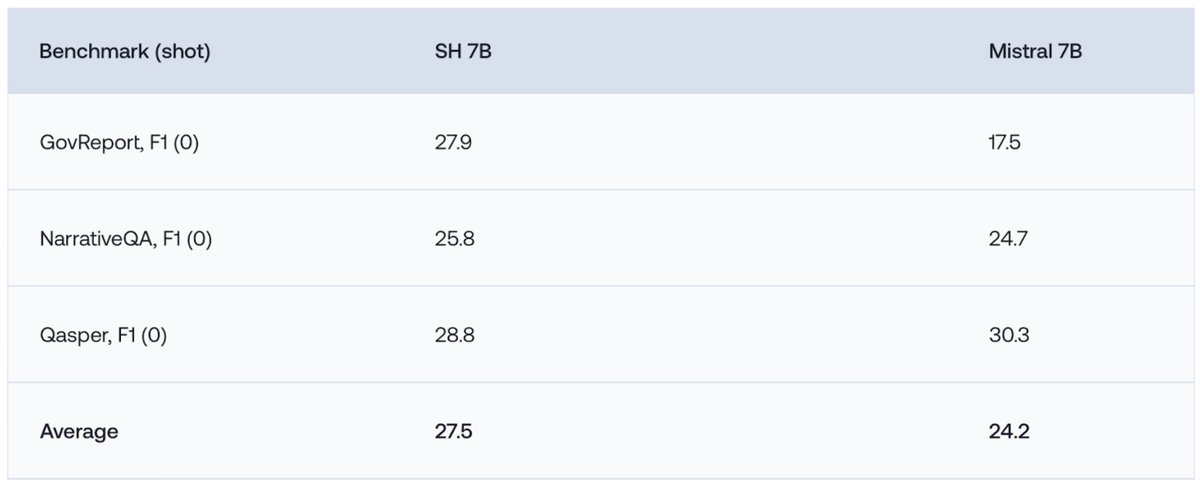
On short-context tasks, including OpenLLM leaderboard tasks, StripedHyena outperforms Llama-2 7B, Yi 7B and the strongest Transformer alternatives such as RWKV-Raven 14B:
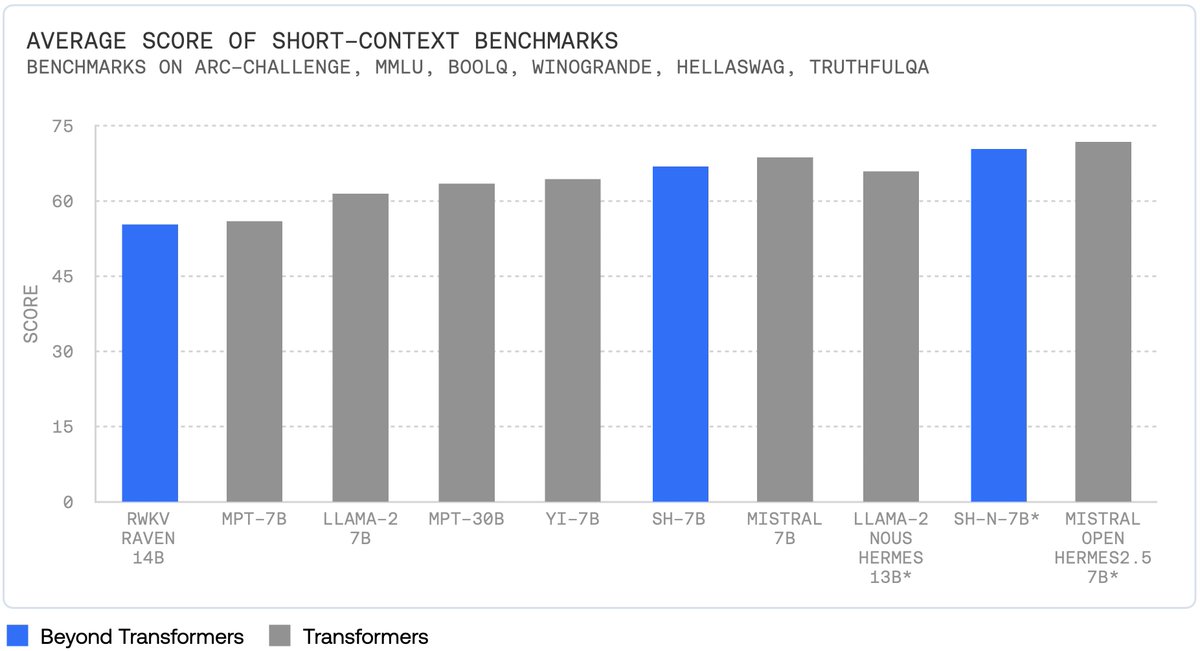
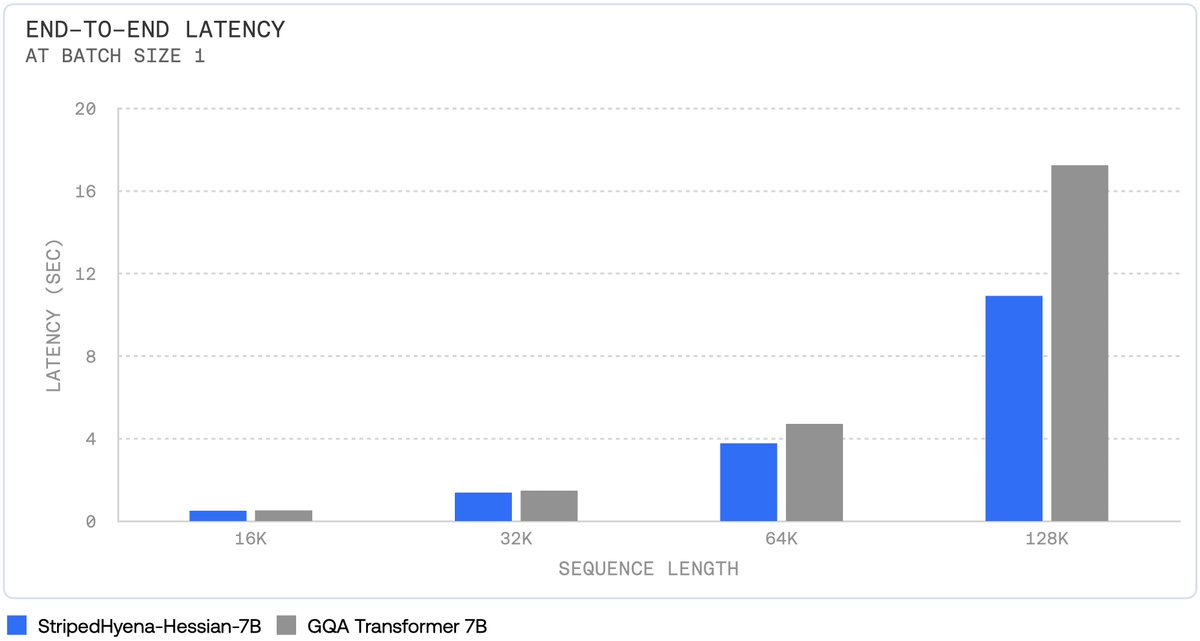
StripedHyena is faster and more memory efficient for long sequence training, fine-tuning, and generation. Using our latest research on fast kernels for gated convolutions (FlashFFTConv) and on efficient Hyena inference, StripedHyena is >30%, >50%, and >100% faster.
StripedHyena is designed using our latest research on scaling laws of efficient architectures. In particular, StripedHyena is a hybrid of attention and gated convolutions arranged in Hyena operators. Via a compute-optimal scaling protocol, we identify several ways to improve.
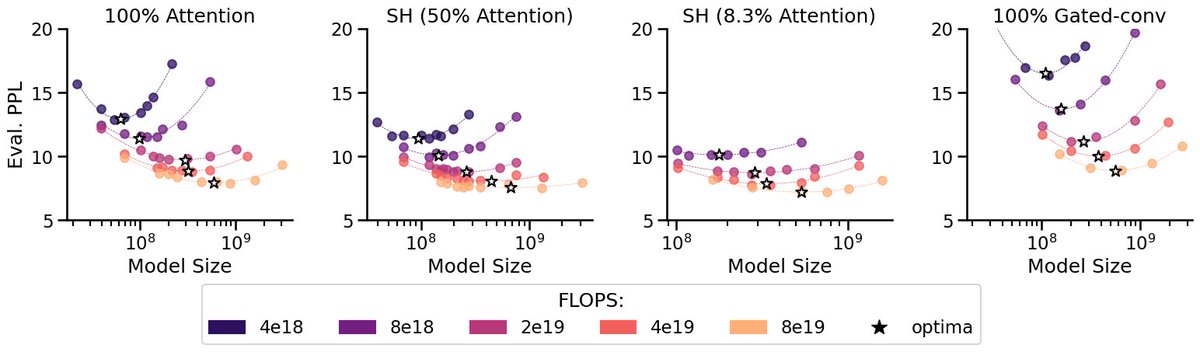
StripedHyena is optimized using a set of new model grafting techniques, enabling us to change the model architecture during training. We grafted architectural components of Transformers and Hyena, and trained on a mix of the RedPajama dataset, augmented with longer-context data.
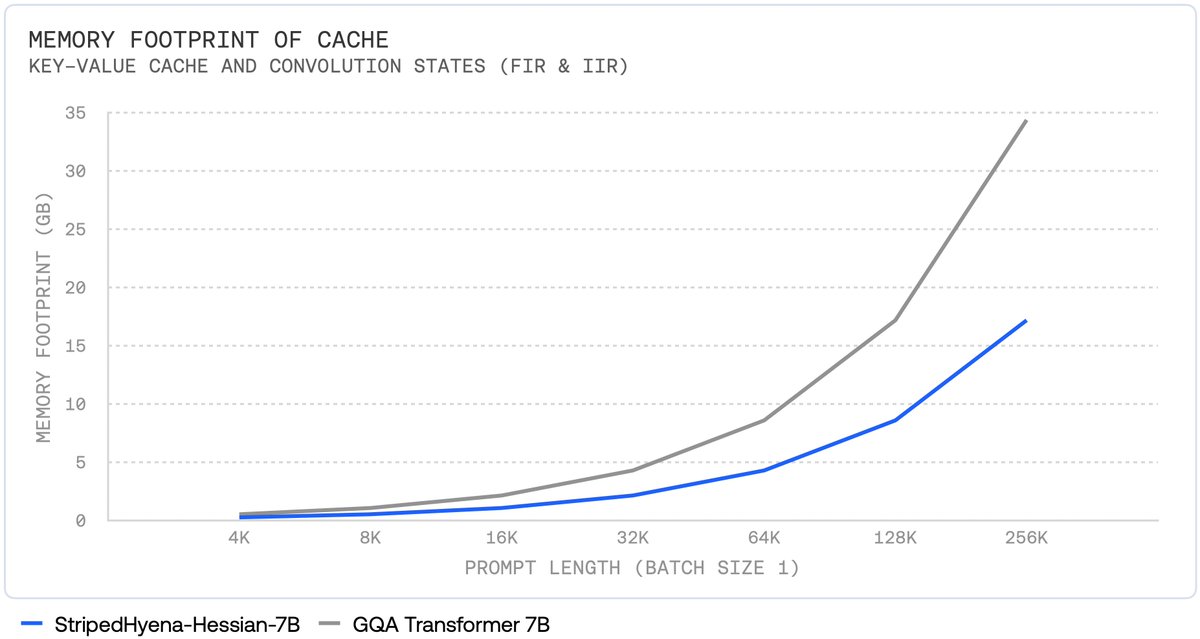
One additional advantage of StripedHyena is a >50% reduced memory footprint during autoregressive generation, compared to a Transformer (both with grouped-query attention).
This work would not have been possible without our collaborators @HazyResearch, @NousResearch, and @Hessian_AI.
It builds on our past work with @Mila_Quebec, @huggingface. We are grateful to open source AI community leaders including @AIatMeta, @AiEleuther, @MistralAI & others.
It builds on our past work with @Mila_Quebec, @huggingface. We are grateful to open source AI community leaders including @AIatMeta, @AiEleuther, @MistralAI & others.
• • •
Missing some Tweet in this thread? You can try to
force a refresh