✅Attention Mechanism in Transformers- Explained in Simple terms.
A quick thread 👇🏻🧵
#MachineLearning #Coding #100DaysofCode #deeplearning #DataScience
PC : Research Gate
A quick thread 👇🏻🧵
#MachineLearning #Coding #100DaysofCode #deeplearning #DataScience
PC : Research Gate
1/ Attention mechanism calculates attention scores between all pairs of tokens in a sequence. These scores are then used to compute weighted representations of each token based on its relationship with other tokens in the sequence.

2/ This process generates context-aware representations for each token, allowing the model to consider both the token's own information and information from other tokens.
3/ Three key components:
Query: Represents the token for which the model is calculating attention weights.
Key: Represents tokens used to compute the attention weights concerning the query.
Value: Represents the associated information or value related to the tokens.
Query: Represents the token for which the model is calculating attention weights.
Key: Represents tokens used to compute the attention weights concerning the query.
Value: Represents the associated information or value related to the tokens.

4/ When and Why to Use Attention Mechanism:
Long-Range Dependencies:Use cases involving long-range dependencies or relationships across tokens benefit from attention mechanisms.
Long-Range Dependencies:Use cases involving long-range dependencies or relationships across tokens benefit from attention mechanisms.
5/ Capturing Contextual Information:Tasks where understanding the context of each token in relation to others is essential, like sentiment analysis, question answering, or summarization.
6/ Variable Length Sequences:Attention mechanisms handle variable-length sequences effectively, allowing the model to process sequences of different lengths without fixed-size inputs.
7/ Learning Hierarchical Relationships:Models that need to learn hierarchical relationships or structures within sequences, such as in document analysis or language modeling.
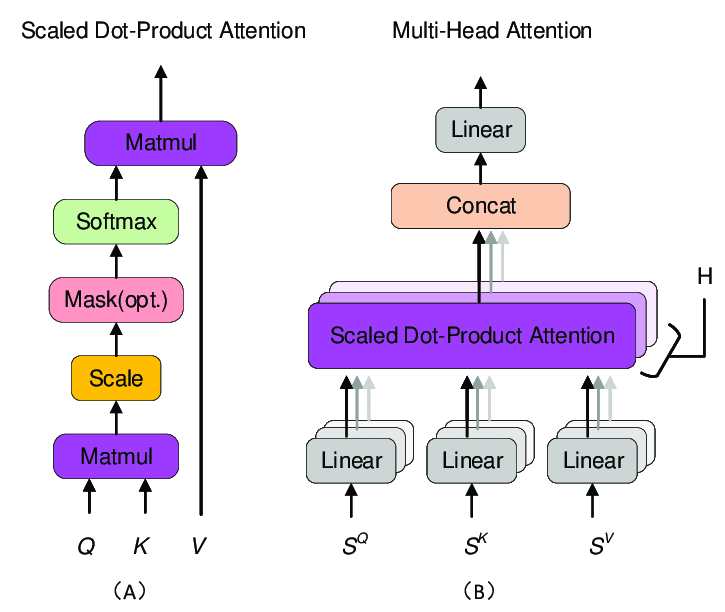
8/ Scaled dot-product attention mechanism involves three primary steps:
Calculate the dot product: Compute the dot product between the query and key vectors. This step measures the similarity or relevance between different words in the input sequence.
Calculate the dot product: Compute the dot product between the query and key vectors. This step measures the similarity or relevance between different words in the input sequence.

9/ Scale the dot products: Scaling the dot products by dividing them by the square root of the dimension of the key vectors. This step prevents the dot products from getting too large, which could lead to gradients becoming too small during training.
10/ Apply softmax: Pass the scaled dot products through a softmax function to obtain attention weights. These weights represent the importance or attention given to different words in the sequence.
11/ Multi-head attention mechanism helps the model capture various aspects or "heads" of relationships within the input data by projecting the input into multiple subspaces and performing self-attention in parallel.

12/ Positional encoding is crucial in transformers . It adds information about the order or position of words in a sequence to the input embeddings.

13/ One common method of positional encoding involves using sine and cosine functions with different frequencies to represent the position of tokens in a sequence. This encoding allows the model to differentiate between tokens based on their positions.
14/ The Transformer architecture is a pivotal model for sequence-to-sequence tasks that relies on self-attention mechanisms, enabling parallelization and capturing long-range dependencies.

15/ It consists of an encoder and a decoder, both containing multiple stacked layers, each composed of attention mechanisms and feed-forward neural networks.
16/ Masked self-attention mechanism prevents the model from peeking ahead during training by masking out future positions in the attention calculation. It ensures that each token attends only to previous tokens.

17/ Visualizing attention weights can provide insights into how a model attends to different parts of the input sequence. This process allows us to see which tokens are more influential when predicting specific outputs or generating sequences.

18/ Tips for Improved Performance:
Sparse Attention:Utilize attention mechanisms with sparsity patterns like Sparse Transformer or Longformer to handle longer sequences efficiently.
Sparse Attention:Utilize attention mechanisms with sparsity patterns like Sparse Transformer or Longformer to handle longer sequences efficiently.

19/ Larger Model Sizes:Scale up the model by increasing the number of layers, hidden dimensions, or heads, allowing the model to capture more complex patterns and information.
Depth and Width Variations:Experiment with variations in model depth and width.
Depth and Width Variations:Experiment with variations in model depth and width.
20/ Dropout and Layer Normalization:Use dropout regularization and layer normalization to prevent overfitting and stabilize training.
Weight Decay:Apply weight decay (L2 regularization) to penalize large weights and prevent the model from overfitting.
Weight Decay:Apply weight decay (L2 regularization) to penalize large weights and prevent the model from overfitting.
21/ Fine-tuning Pre-trained Models:Utilize pre-trained models (e.g., BERT, GPT, or RoBERTa) and fine-tune them on domain-specific or task-specific data to leverage learned representations.
Model Ensembling:
Combine predictions from multiple models to improve performance.
Model Ensembling:
Combine predictions from multiple models to improve performance.
22/ If you liked this post then subscribe and read more -
Github -
naina0405.substack.com
github.com/Coder-World04/…
Github -
naina0405.substack.com
github.com/Coder-World04/…
• • •
Missing some Tweet in this thread? You can try to
force a refresh