
Happy to share a new paper I worked on!:
"Scalable High-Resolution Pixel-Space Image Synthesis with Hourglass Diffusion Transformers"
abs:
website:
A quick thread about the paper! ↓ (1/11) arxiv.org/abs/2401.11605
crowsonkb.github.io/hourglass-diff…

"Scalable High-Resolution Pixel-Space Image Synthesis with Hourglass Diffusion Transformers"
abs:
website:
A quick thread about the paper! ↓ (1/11) arxiv.org/abs/2401.11605
crowsonkb.github.io/hourglass-diff…

Before I continue, I want to mention this work was led by @RiversHaveWings, @StefanABaumann, @Birchlabs. @DanielZKaplan, @EnricoShippole were also valuable contributors. (2/11)
High-resolution image synthesis w/ diffusion is difficult without using multi-stage models (ex: latent diffusion). It's even more difficult for diffusion transformers due to O(n^2) scaling. So we want an easily scalable transformer arch for high-res image synthesis. (3/11)
That's exactly what we present with Hourglass Diffusion Transformer (HDiT)!
Our hierarchical transformer arch has an O(n) complexity, enabling it scale well to higher resolutions (4/11)
Our hierarchical transformer arch has an O(n) complexity, enabling it scale well to higher resolutions (4/11)
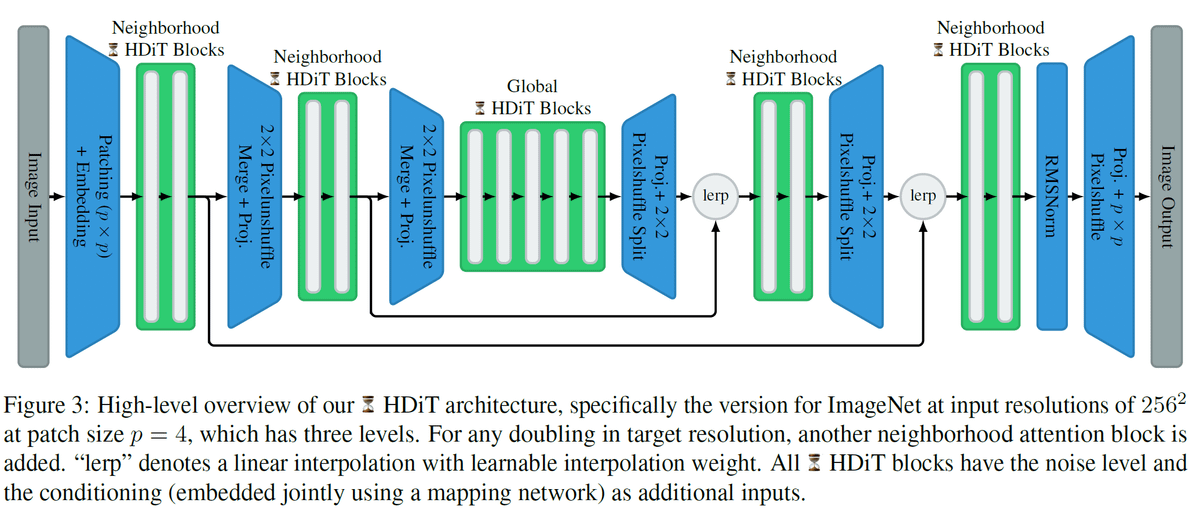
HDiT relies on merging/downsampling and splitting/upsampling operations implemented with Pixel Shuffling & Unshuffling to enable hierarchical processing of the images at different scales.
Skip connections are implemented using learnable linear interp. (5/11)
Skip connections are implemented using learnable linear interp. (5/11)
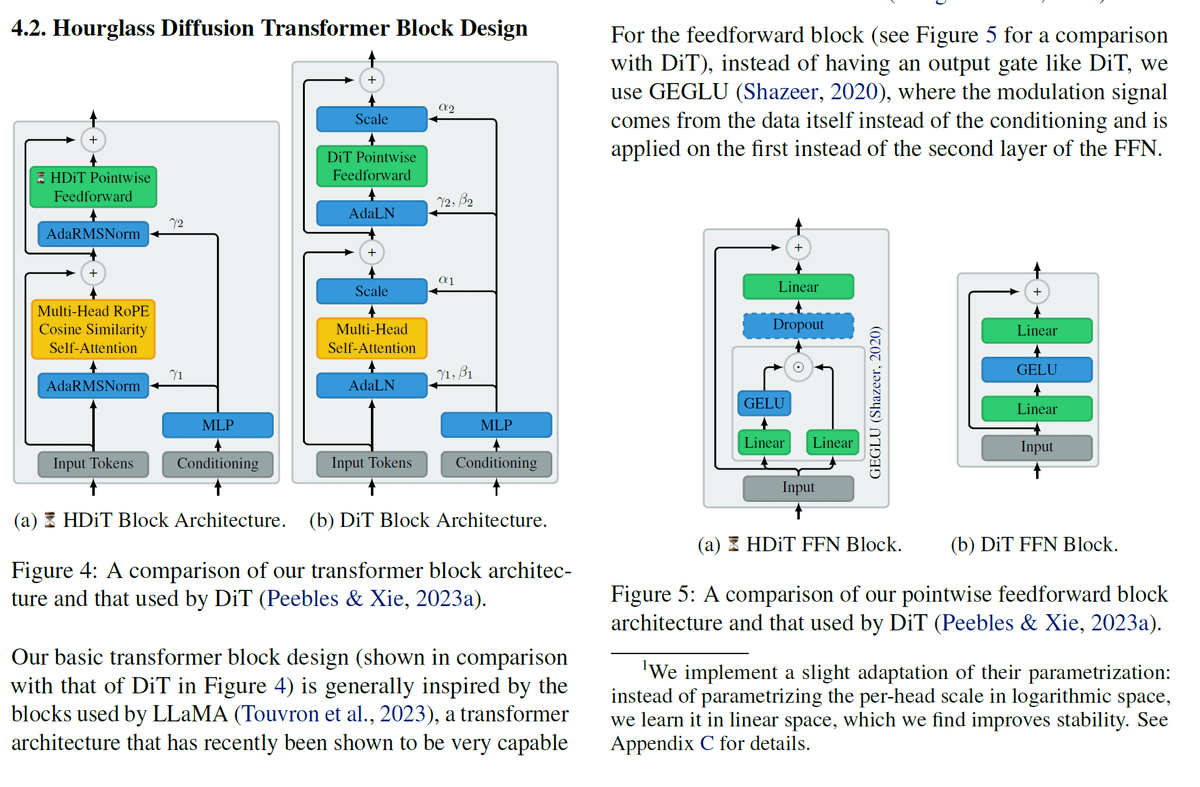
Our Transformer blocks utilize recent best practices and tricks for Transformers, like RoPE, cosine similarity self-attention, RMSNorm, GeGLU, etc. These Transformer modifications have previously been minimally explored in the context of diffusion. (6/11)
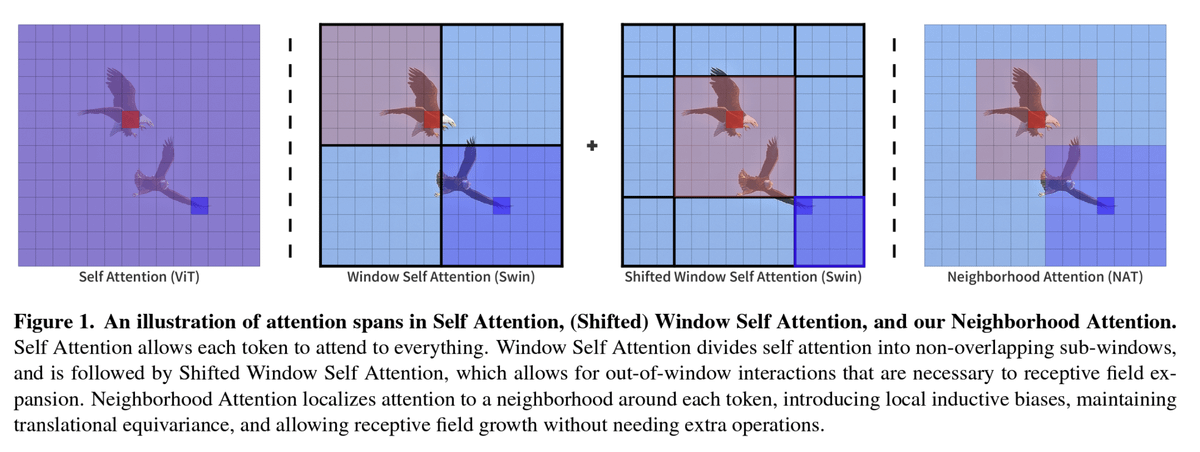
Finally, what enables the O(n) scaling is the use of local self-attention at the higher resolution blocks in HDiT. While Shifted Window attention (Swin) is a very common form of local attention, we instead find that Neighborhood attention performs better (figure from that paper)
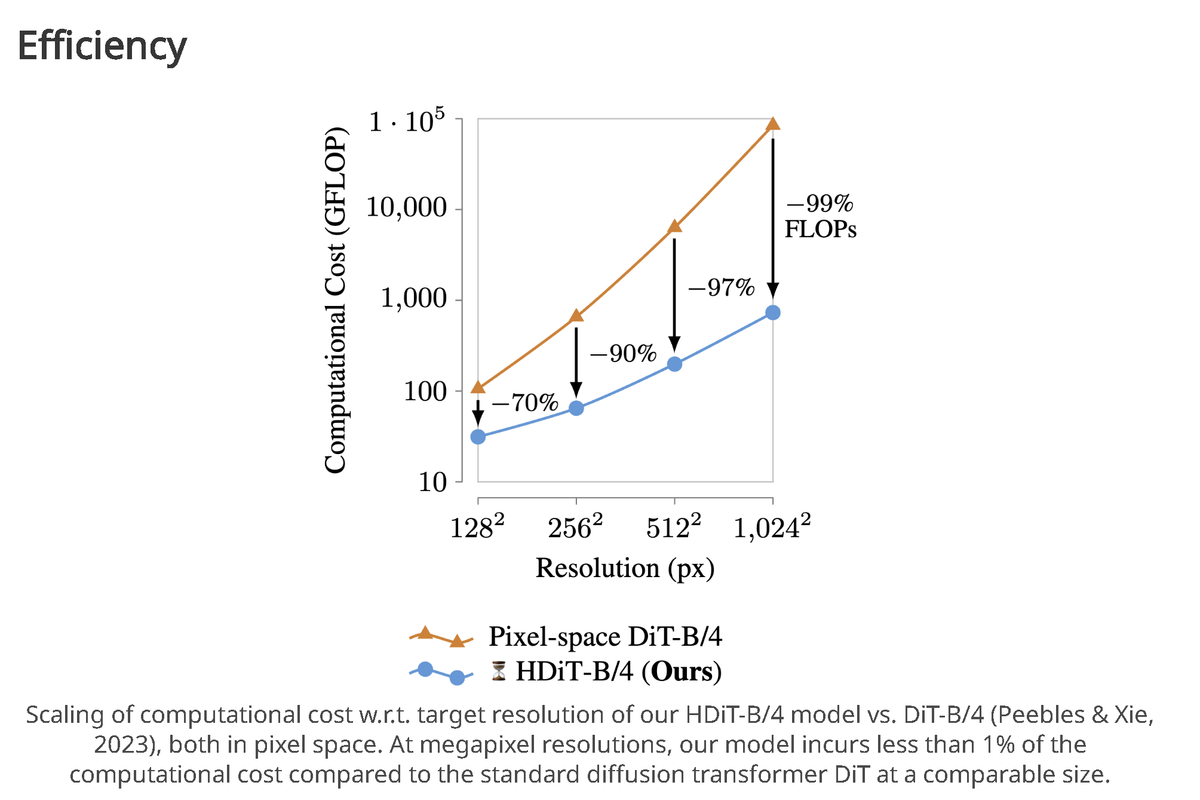
Onto the results!
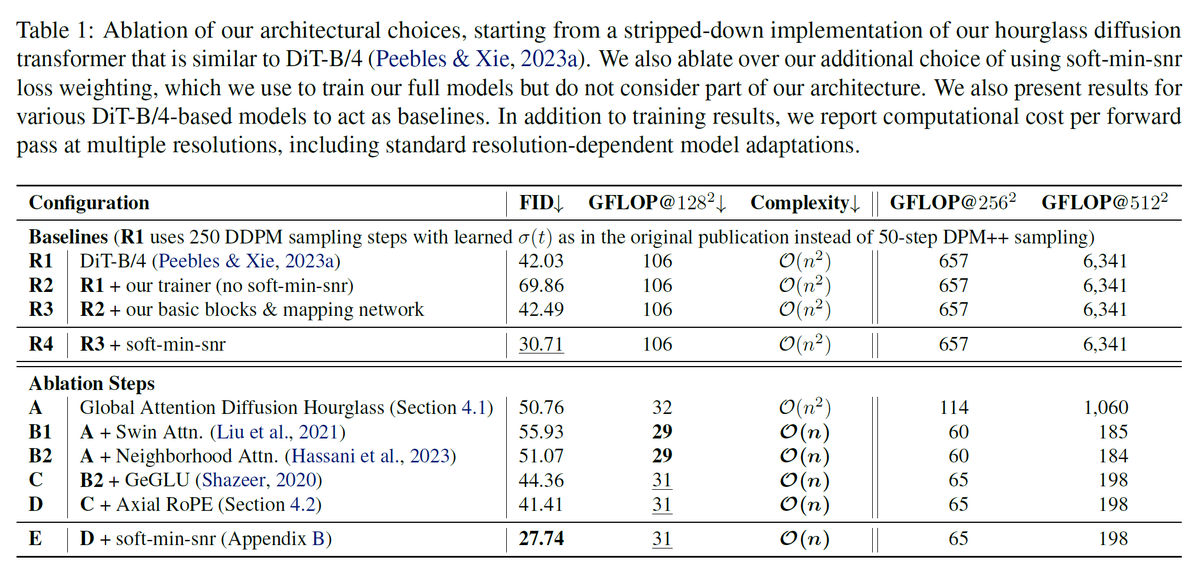
Our comprehensive ablation study demonstrates that our HDiT arch with transformer tricks (GeGLU, RoPE, etc.) and Neighborhood Attention outperforms DiT whilst incurring fewer FLOPs. (8/11)
Our comprehensive ablation study demonstrates that our HDiT arch with transformer tricks (GeGLU, RoPE, etc.) and Neighborhood Attention outperforms DiT whilst incurring fewer FLOPs. (8/11)
We train an 85M param HDiT on FFHQ 1024x1024 and obtain a new SOTA for diffusion models...
The FID doesn't beat StyleGANs but note that FID is often biased towards GAN samples.
Qualitatively, the generations look quite good! (9/11)
The FID doesn't beat StyleGANs but note that FID is often biased towards GAN samples.
Qualitatively, the generations look quite good! (9/11)

We also train a 557M param model on ImageNet 256x256 that performs better than DiT-XL/2 and comparable to other SOTA models. (10/11)

Overall, we believe there is significant promise in this architecture for high-resolution image synthesis.
You can give it a try here!:
(11/11)github.com/crowsonkb/k-di…
You can give it a try here!:
(11/11)github.com/crowsonkb/k-di…
Tweet from co-author @Birchlabs who all of you should follow!
https://twitter.com/Birchlabs/status/1749623819113800115
Tweet from @RiversHaveWings, who originally came up with HDiT (follow her too!):
https://twitter.com/RiversHaveWings/status/1749623266749358492
• • •
Missing some Tweet in this thread? You can try to
force a refresh















