Whisper powered by Apple Neural Engine! 🔥
The lads at @argmaxinc optimised Whisper to work at blazingly fast speeds on iOS and Mac!
> All code is MIT-licensed.
> Upto 3x faster than the competition.
> Neural Engine as well as Metal runners.
> Open source CoreML models.
> 2 lines of code :)
> Whisper & Whisper-Turbo (even faster variant)
(Look how it utilises ANE so beautifully in the video showing their sample app on Mac!)
The lads at @argmaxinc optimised Whisper to work at blazingly fast speeds on iOS and Mac!
> All code is MIT-licensed.
> Upto 3x faster than the competition.
> Neural Engine as well as Metal runners.
> Open source CoreML models.
> 2 lines of code :)
> Whisper & Whisper-Turbo (even faster variant)
(Look how it utilises ANE so beautifully in the video showing their sample app on Mac!)
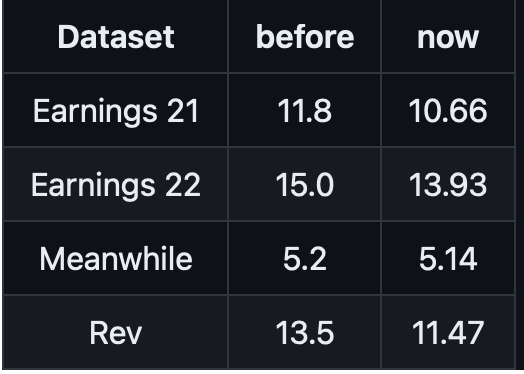
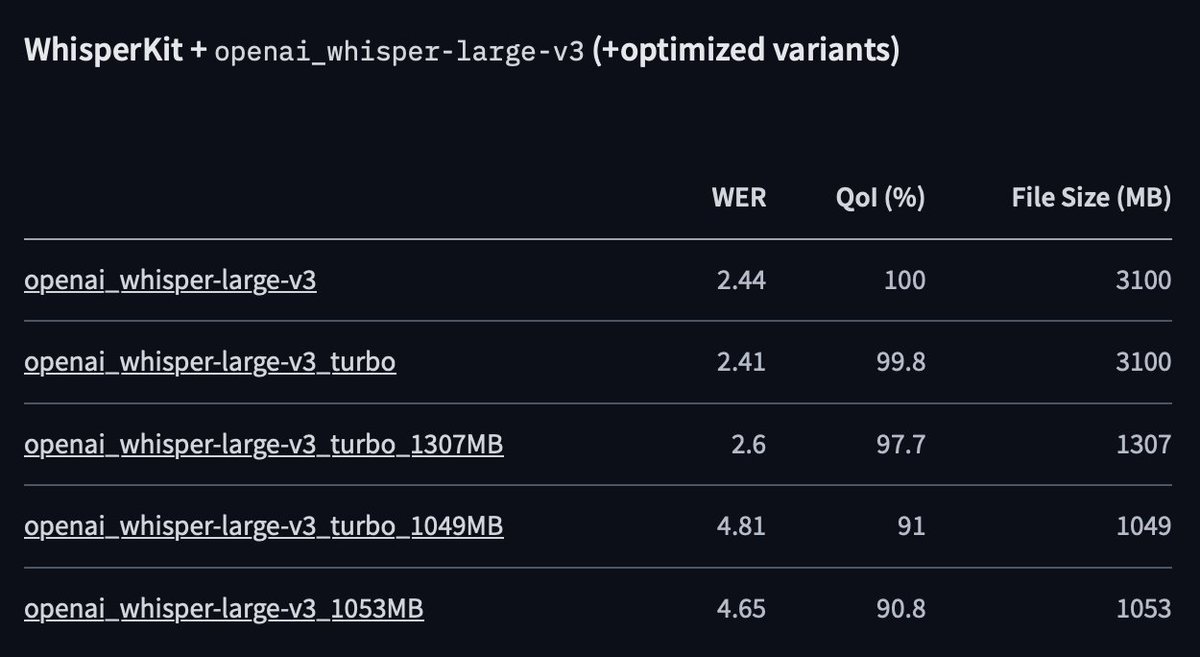
@argmaxinc The Whisper-Turbo variants bring the memory requirements down by up-to 1/3rd ⚡
*With quite a little drop in performance.
*With quite a little drop in performance.
• • •
Missing some Tweet in this thread? You can try to
force a refresh