
Developer Experience & Community @OpenAI | ex @huggingface | F1 fan | Here for @at_sofdog’s wisdom | *opinions my own
 Here's the 1B Flash model:
Here's the 1B Flash model: You can check out the model weights here:
You can check out the model weights here: step 1: omz
step 1: omz 

 Check out the model here:
Check out the model here: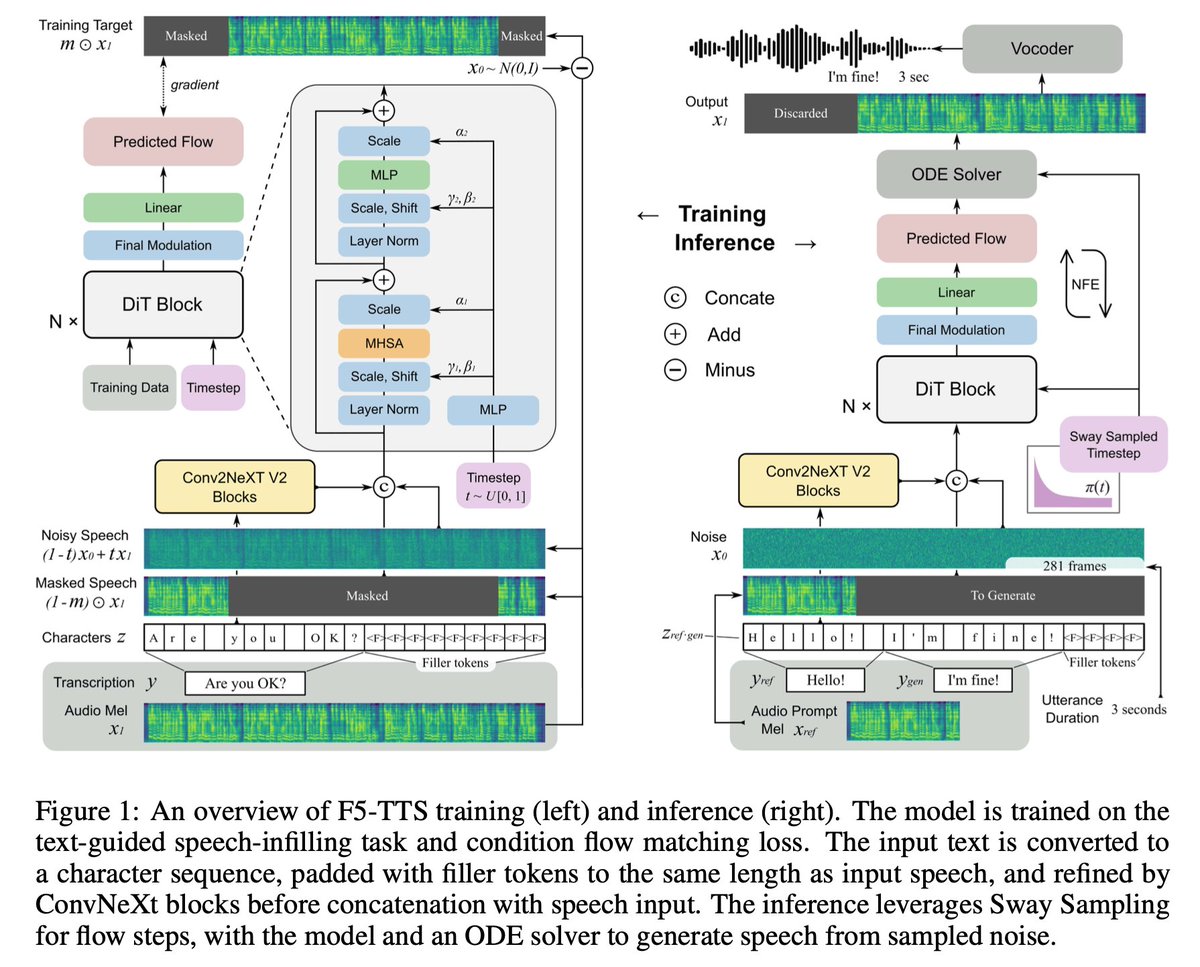
 Link to the report:
Link to the report:

 Check out all the models here:
Check out all the models here:

 Optimised matmul kernels for int-2,4,8 coming soon!
Optimised matmul kernels for int-2,4,8 coming soon! Check out the checkpoints here:
Check out the checkpoints here: