1/n An ontology of Large Language Model (LLM) powered Multi-Agents
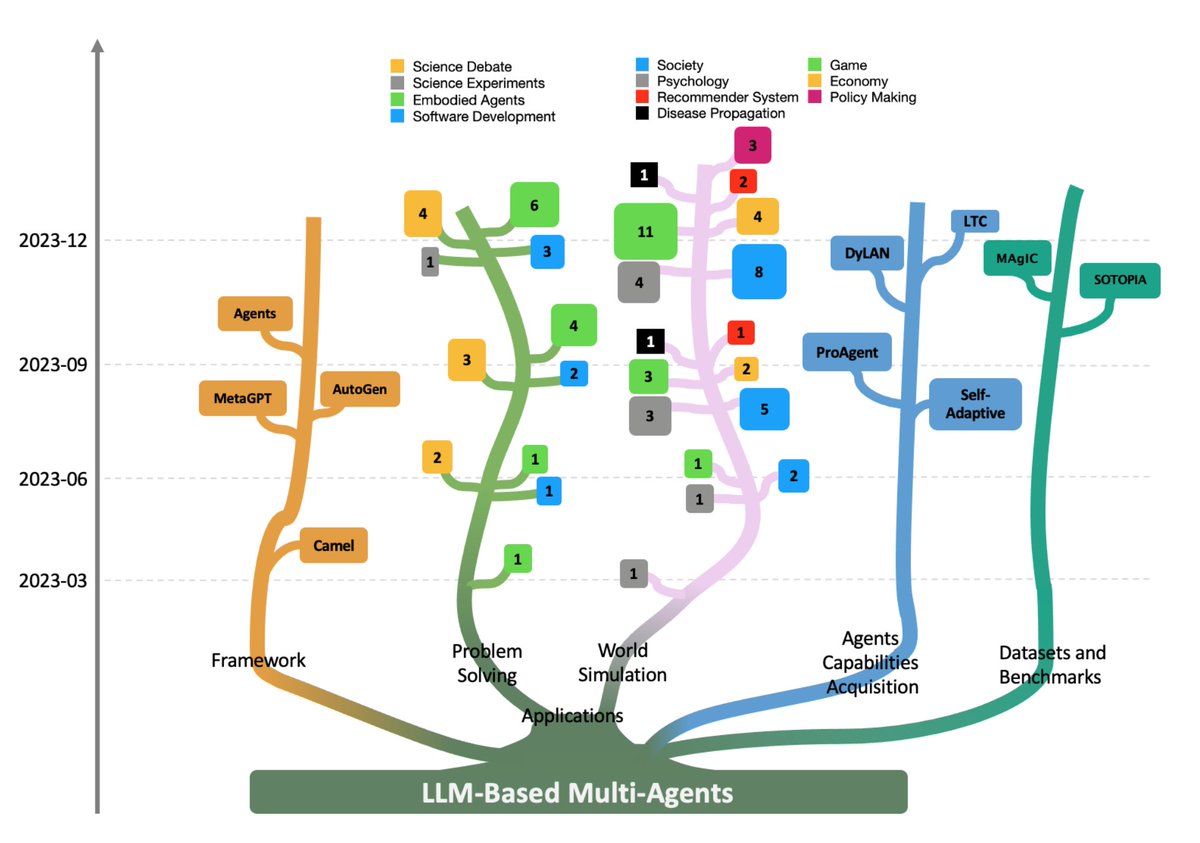
- Single LLM-based agents have shown promising capabilities such as planning, tool use, memory, and decision making. This has motivated research into multi-agent systems.
- LLM-multi agent (LLM-MA) systems aim to leverage multiple specialized agents collaborating together, providing advanced problem solving compared to single agents.
Existing Issues
- Most existing work focuses on single LLM-based agents. There is a lack of systematic analysis of emergent capabilities and issues in LLM-MA systems.
- Early LLM-MA systems have been developed independently. There is an absence of a unified blueprint and taxonomy to connect different aspects like agent profiling, communication protocols etc.
- There is a gap in benchmarks and evaluation methods tailored for assessing collaborative intelligence of LLM-MA systems. Metrics focused on individual agents may overlook emergent group behaviors.
- Open challenges remain in scaling LLM-MA systems, managing collective capabilities, mitigating issues like hallucination, and expanding applications to complex real-world problems.
In summary, while single LLM-agents have made strides, there are open questions regarding formulating, analyzing, evaluating and advancing collaborative multi-agent systems for sophisticated tasks. Establishing a unified blueprint can accelerate progress.
- Single LLM-based agents have shown promising capabilities such as planning, tool use, memory, and decision making. This has motivated research into multi-agent systems.
- LLM-multi agent (LLM-MA) systems aim to leverage multiple specialized agents collaborating together, providing advanced problem solving compared to single agents.
Existing Issues
- Most existing work focuses on single LLM-based agents. There is a lack of systematic analysis of emergent capabilities and issues in LLM-MA systems.
- Early LLM-MA systems have been developed independently. There is an absence of a unified blueprint and taxonomy to connect different aspects like agent profiling, communication protocols etc.
- There is a gap in benchmarks and evaluation methods tailored for assessing collaborative intelligence of LLM-MA systems. Metrics focused on individual agents may overlook emergent group behaviors.
- Open challenges remain in scaling LLM-MA systems, managing collective capabilities, mitigating issues like hallucination, and expanding applications to complex real-world problems.
In summary, while single LLM-agents have made strides, there are open questions regarding formulating, analyzing, evaluating and advancing collaborative multi-agent systems for sophisticated tasks. Establishing a unified blueprint can accelerate progress.
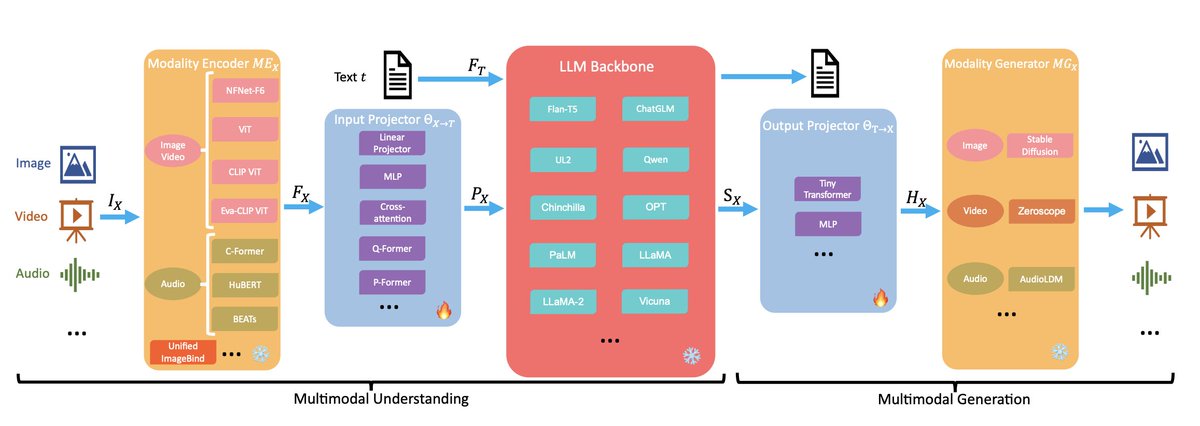
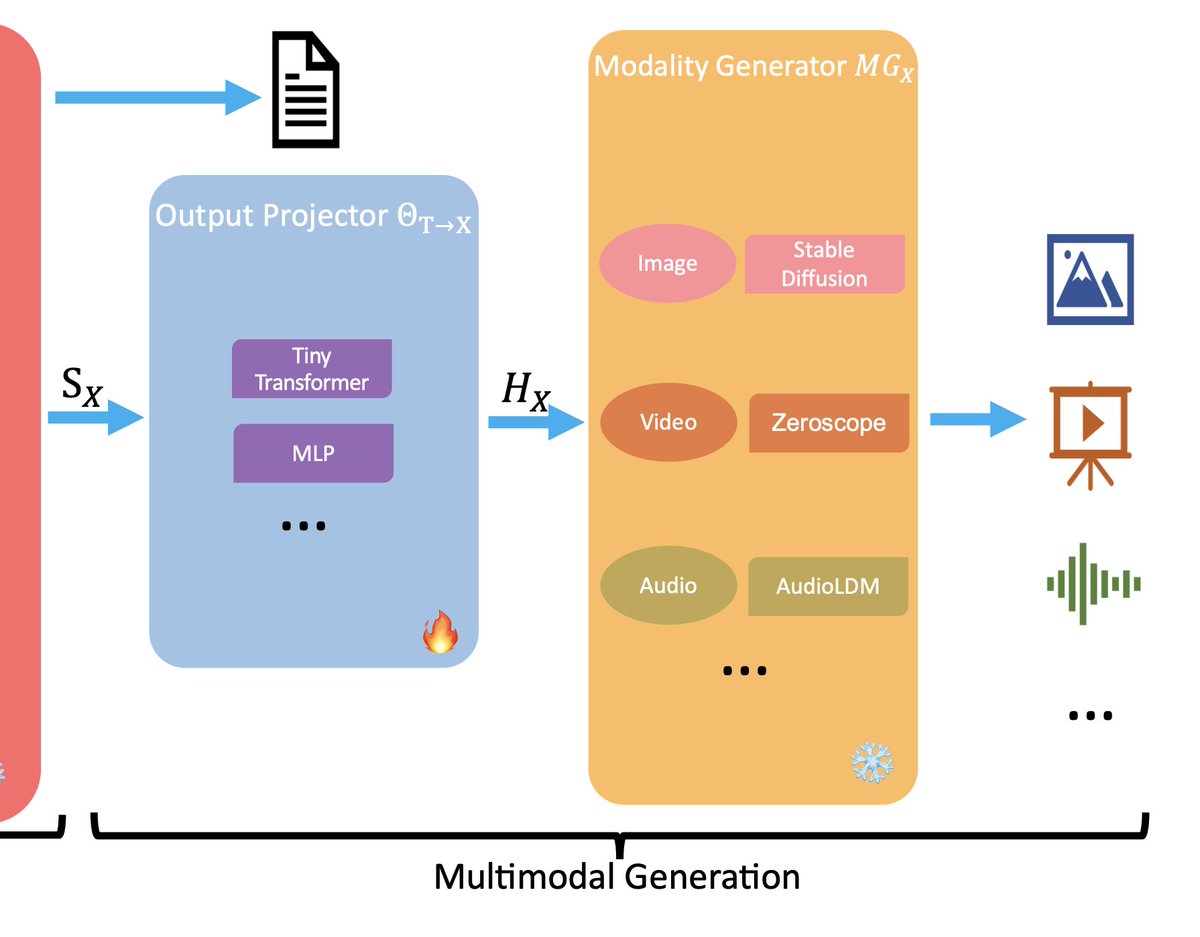
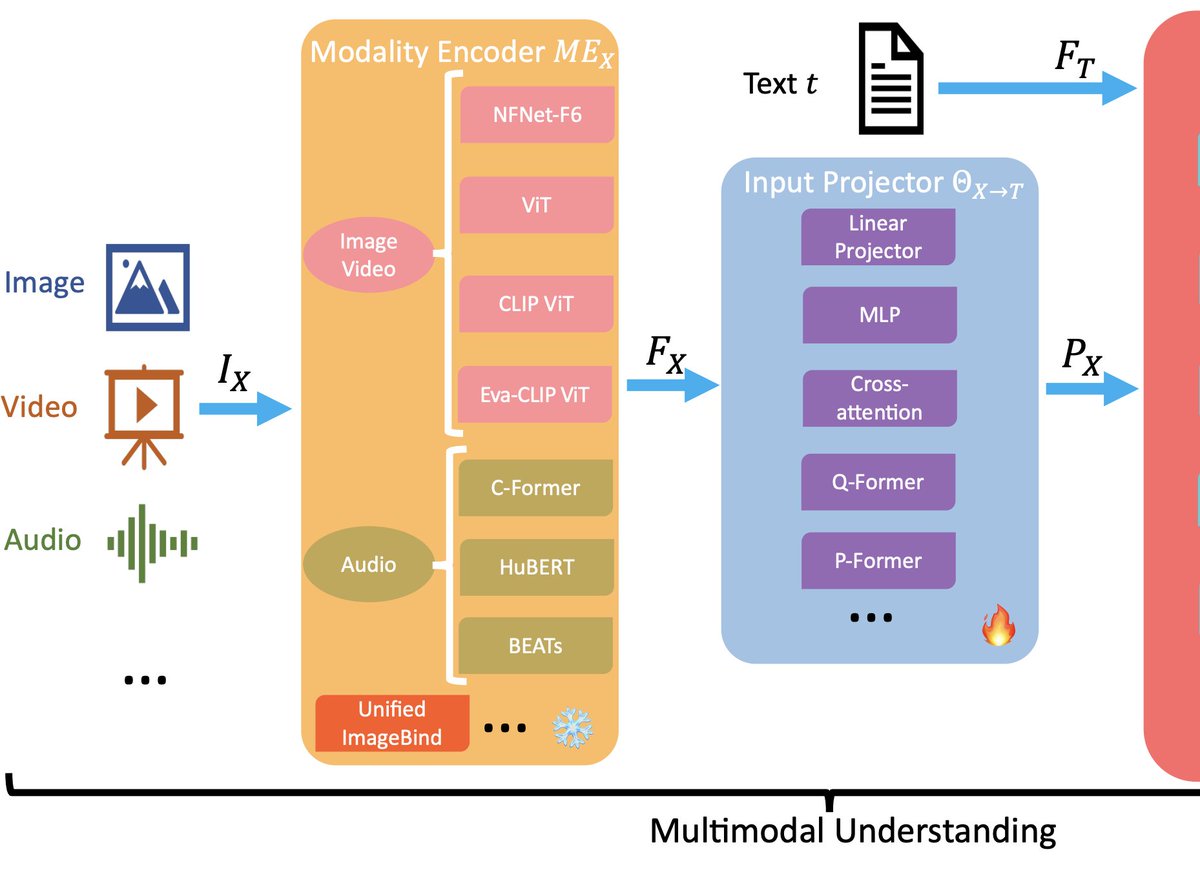
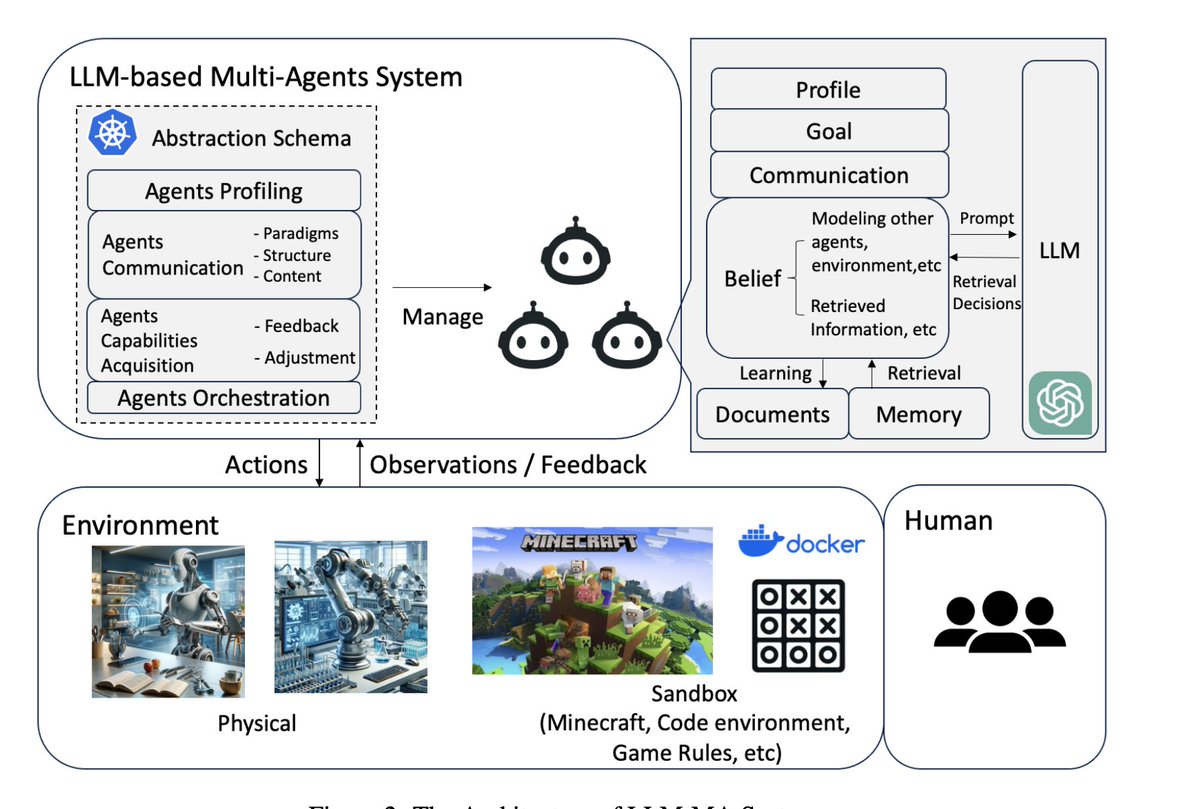
2/n The LLM-based multi-agent (LLM-MA) ontology consists of four key components:
1. Agents-Environment Interface:
This refers to how agents perceive and interact with the environment (sandbox, physical, or none). Environments could be software applications, embodied robot systems, gaming simulations etc.
2. Agent Profiling:
It deals with characterizing distinct agents based on aspects like roles, capabilities, constraints etc. Common methods are pre-defined profiles, model-generated profiles, or data-derived profiles.
3. Agent Communication:
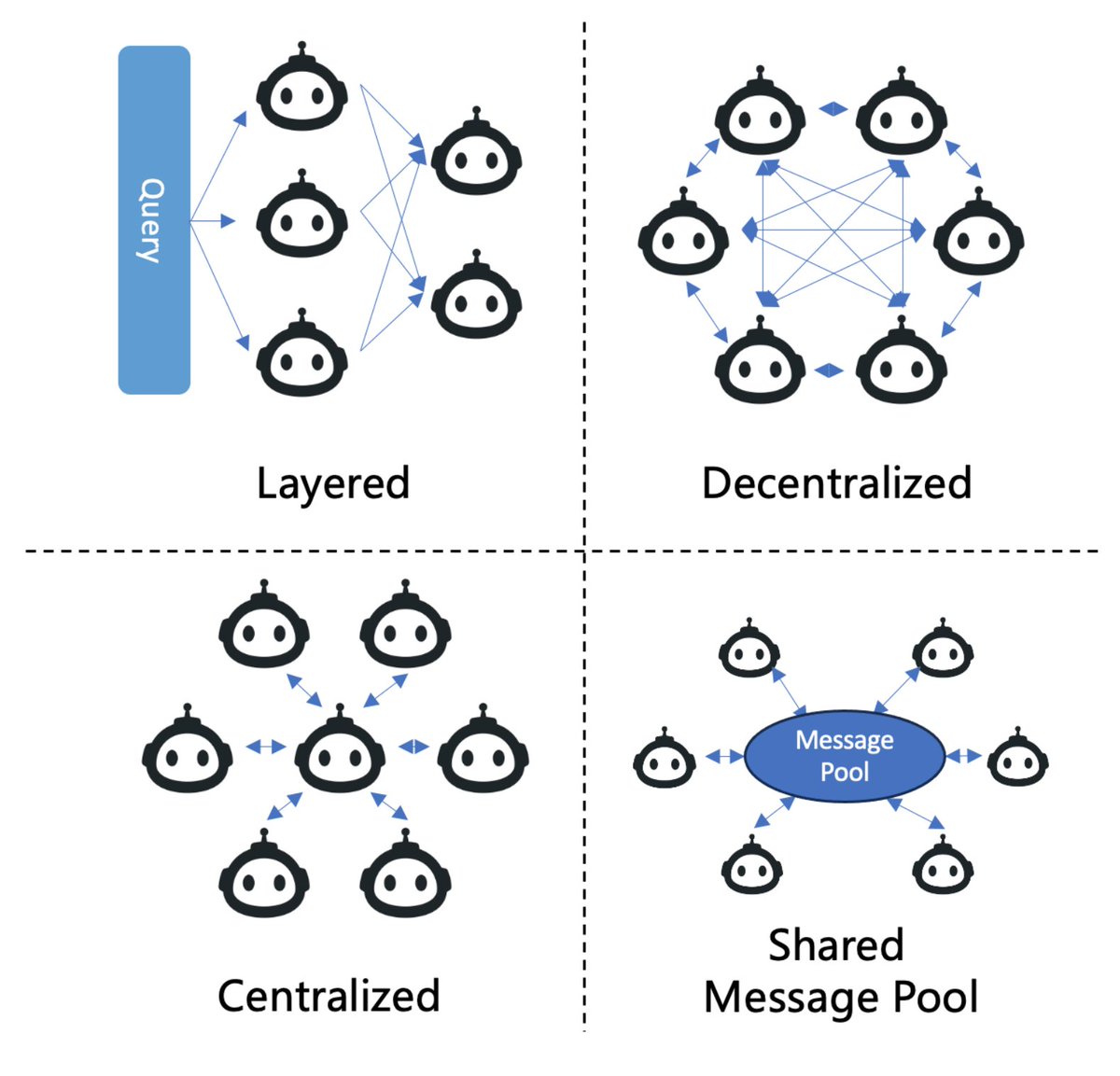
This encompasses communication paradigms (cooperative, debate, competitive), structures organizing agent interactions (layered, decentralized, centralized), and actual content exchanged (typically textual).
4. Agent Capability Acquisition:
It focuses on how agents obtain feedback to enhance their skills over time via memory, self-evolution by modifying goals/strategies, or dynamic agent generation.
In a nutshell, this ontology systematically connects the agents themselves, the environments they operate in, how they interact to solve problems collectively, and how they acquire knowledge. According to the paper, positioning LLM-MA systems in this framework can enable more structured analysis. The ontology provides a blueprint for continued research and applications.
1. Agents-Environment Interface:
This refers to how agents perceive and interact with the environment (sandbox, physical, or none). Environments could be software applications, embodied robot systems, gaming simulations etc.
2. Agent Profiling:
It deals with characterizing distinct agents based on aspects like roles, capabilities, constraints etc. Common methods are pre-defined profiles, model-generated profiles, or data-derived profiles.
3. Agent Communication:
This encompasses communication paradigms (cooperative, debate, competitive), structures organizing agent interactions (layered, decentralized, centralized), and actual content exchanged (typically textual).
4. Agent Capability Acquisition:
It focuses on how agents obtain feedback to enhance their skills over time via memory, self-evolution by modifying goals/strategies, or dynamic agent generation.
In a nutshell, this ontology systematically connects the agents themselves, the environments they operate in, how they interact to solve problems collectively, and how they acquire knowledge. According to the paper, positioning LLM-MA systems in this framework can enable more structured analysis. The ontology provides a blueprint for continued research and applications.
3/n Here's the survey paper:
Large Language Model based Multi-Agents: A Survey of Progress and Challenges
DOI: 10.13140/RG.2.2.36311.85928researchgate.net/publication/37…
Large Language Model based Multi-Agents: A Survey of Progress and Challenges
DOI: 10.13140/RG.2.2.36311.85928researchgate.net/publication/37…
• • •
Missing some Tweet in this thread? You can try to
force a refresh